Параметры помехоустойчивых кодов

Простейшим из помехоустойчивых кодов с обнаружением ошибок является код с проверкой на четность. Его суть заключается в следующем. На передающем конце канала связи устройство кодирования проводит подсчет числа логических 1 в передаваемом двоичном кодовом слове. Если сумма логических 1 оказывается нечетной, в конец передаваемой кодовой комбинации добавляется 1, а если нет, то 0. На приемном конце… Читать ещё >
Параметры помехоустойчивых кодов (реферат, курсовая, диплом, контрольная)
Помехоустойчивый код характеризуют следующие параметры:
- • основание т
- • длина комбинации — длина слова п;
- • длина информационной последовательности k;
- • число проверочных символов г,
- • число кодовых комбинаций Nl{;
- • кодовое расстояние d:j;
- • скорость R;
- • избыточность v;
- • вес кодовой комбинации о;
- • кратность ошибки;
- • вероятность обнаружения ошибки рпо и вероятность необнаружения ошибки р1Ю.
Проверку кода на безошибочность приема проводят, но контрольному сигналу — синдрому. Если синдром равен нулю, то ошибок в коде нет.
Цель внесения избыточных символов в помехоустойчивые коды — сформировать сообщения, как можно больше отличающиеся друг от друга. Для измерения степени отличия Р. Хемминг ввел кодовое расстояние dtj между двумя кодовыми словами — число позиций, в которых соответствующие символы двух слов одинаковой длины различны. Наименьшее значение dtj для всех пар кодовых последовательностей (минимальное число символов, которыми различаются два кодированных сообщения) называют минимальным кодовым расстоянием d0. Для некодированных сообщений кодовое расстояние d0= 1. От кодового расстояния зависит корректирующая способность кода — возможность обнаруживать и (или) исправлять с его помощью некоторые из ошибок. При декодировании сообщения с кодовым расстоянием d0 можно обнаружить ошибки кратности t0=dn- 1 и исправить ошибки кратности ?0 = (d0 — 1)/2.
Говорят, что в канале произошла ошибка кратности t0, если в кодовой комбинации t символов приняты ошибочно. Кратность ошибки есть не что иное, как расстояние Хемминга между переданной и принятой кодовыми комбинациями, иначе, вес вектора ошибки. Параметр t указывает, что все комбинации из t0 или менее ошибок в любой принятой последовательности могут быть исправлены. В теории кодирования доказано, что систематический код обладает способностью обнаружить ошибки лишь тогда, когда минимальное кодовое расстояние для него больше или равно 2?0 (в случае обнаружения одиночных ошибок t0 =1). Это означает, что между соседними кодовыми комбинациями должна существовать по крайней мере еще одна кодовая комбинация.
Запишем основные зависимости между кратностью обнаруживаемых ошибок ?0, исправляемых ошибок ?и, исправлением стираний ?с и минимальным кодовым расстоянием d" кода: 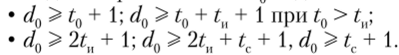
Избыточность кода — разность между средней длиной слова и энтропией:
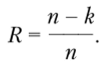
При этом скорость передачи.
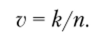
Например, для блокового кода с длиной слова п = 15, исправляющего две ошибки, k = 7 и R = (15 — 7)/15 ~ 0,533, а при длине слова п = 15 и исправлении трех ошибок k = 5 и R = (15 — 5)/15 ~ 0,666. Соответственно, v = 0,467 и 0,333. Значит, при данной длине блоков п повышение корректирующей способности связано с увеличением избыточности R и уменьшением скорости передачи v. Так как число различных сообщений может кодироваться блоком длиной п, то снижение скорости передачи v эквивалентно уменьшению потока передаваемых сообщений. Отметим, что число проверочных символов r = n-k, a число ненулевых элементов в кодовой комбинации определяет ее вес со.
Коды, у которых требуемая корректирующая способность достигается при минимальной избыточности, называются оптимальными.
К. Шенноном доказано, что при кодировании длинных последовательностей (блоков) символов (п —>? оо) существуют коды с как угодно малой избыточностью (R -* 0) при как угодно малой вероятности ошибочного опознания сообщений. В наиболее часто используемых сейчас кодах обычно с увеличением п корректирующая способность улучшается, однако при п —" 00 у большинства кодов R —*? 1.
Различают коды, только обнаруживающие ошибки и исправляющие (корректирующие), которые дополнительно к обнаружению еще и исправляют ошибки. Устранение ошибок с помощью корректирующих кодов реализуют в симплексных каналах связи. В дуплексных каналах достаточно применения кодов, обнаруживающих ошибки, так как сигнализация об ошибке вызывает повторную передачу от источника. Это основные методы, используемые в сетях связи.
Код с обнаружением ошибок уменьшает число неверно опознанных сообщений, позволяет «стирать» или особо отмечать сообщения, в которых установлено присутствие ошибки, а в некоторых случаях (системы с обратными связями) принять меры к повторной передаче и приему неопознанных сообщений.
Простейшим из помехоустойчивых кодов с обнаружением ошибок является код с проверкой на четность. Его суть заключается в следующем. На передающем конце канала связи устройство кодирования проводит подсчет числа логических 1 в передаваемом двоичном кодовом слове. Если сумма логических 1 оказывается нечетной, в конец передаваемой кодовой комбинации добавляется 1, а если нет, то 0. На приемном конце канала связи проводится аналогичный подсчет, и если контрольная сумма будет нечетной, то принимается решение о том, что при передаче произошло искажение информации, в противном случае принятая информация признается достоверной. При контроле на четность единственный способ получить достоверную информацию — повторная передача кодового слова. Для этого приемник формирует специальную команду, которую передают по каналу связи в обратном направлении к передатчику сообщений. Однако такие коды недостаточно надежны, особенно при появлении пачек ошибок. Более надежными обнаруживающими ошибки кодами являются циклические коды (см. далее).
Код с исправлением (коррекцией) ошибок позволяет получать верные сообщения, несмотря на наличие некоторого числа ошибок при опознании символов. Коррекция (обнаружение и исправление) ошибок достигается лишь при использовании в кодовом слове определенного числа избыточных символов. Общий принцип построения такого кода аналогичен принципу построения кода, обнаруживающего одиночную ошибку. Однако при этом из всех кодовых слов длиной п символов для использования в системе передачи необходимо отобрать лишь определенную часть, считая остальные слова запрещенными. При этом, чтобы исправить одну ошибку, все отобранные кодовые слова должны отличаться друг от друга как минимум на три символа. В этом случае одиночная ошибка переведет переданное слово в одно из запрещенных, что и позволит обнаружить ошибку, но полученное запрещенное слово отличается от переданного лишь одним символом, а от остальных разрешенных слов — не менее чем на два символа. Значит, принятое слово «ближе» к действительно переданному и менее похоже на остальные разрешенные слова.
Если при передаче используют все возможные кодовые комбинации, то ошибка любой кратности остается незамеченной. Действительно, любое число замен превращает одну кодовую комбинацию в другую, а так как любая комбинация может встретиться в передаче, то нет сомнений в правильности принятой комбинации. Рассмотрим в качестве примера передачу четырех символов двузначным двоичным кодом (п = 2; k = 2):
сообщение, А Б В Г, код 00 01 10 11.
При передаче сообщения Б одиночная ошибка в первом знаке приведет к приему сообщения Г, ошибка во втором знаке — к Л, двойная ошибка — к В. Эти ошибки не различимы, из-за того что все сообщения отличаются лишь в одном или в двух знаках.
Для того чтобы можно было обнаружить одиночную ошибку, достаточно взять такие кодовые комбинации, которые отличались бы между собой не менее чем в двух знаках. Таким образом, принцип построения кода, обнаруживающего одиночную ошибку, состоит в использовании не всех возможных комбинаций, а только половины. Вторая половина должна образовывать запрещенные комбинации. Одиночная ошибка превращает разрешенную комбинацию в запрещенную. Для того же примера код с обнаружением ошибки имеет следующий вид:
сообщение, А Б В Г, код 000 011 101 110.
Здесь каждая комбинация отличается от другой уже двумя знаками. Для этого пришлось взять трехзначный код (N = 2″ = 2Л = 8).
Код, позволяющий исправить ошибку, строится из кодовых комбинаций, различающихся не менее чем в трех знаках. Ошибочно принятая комбинация всегда будет ближе к истинной, чем к любой другой разрешенной комбинации:
сообщение, А Б В Г, код 0 1 101 10 110 11 011.
Здесь применен пятизначный код. Пусть принята комбинация 1 001, которой в кодовой таблице нет. Следовательно, появилась ошибка. Принятая комбинация отличается от Л и Г в двух знаках, от Б — в одном, от В — в пяти, значит, передавали сообщение В. Это эквивалентно исправлению одиночной ошибки.
Если в кодовой комбинации два знака заменяются ошибочными, то ошибка называется двойной, если три — тройной и т. д. Чем больше исправляющая способность кода, тем выше кратность исправляемых ошибок, тем больше требуется знаков. Само исправление происходит путем сравнения принятого кода с разрешенными, и если обнаружена ошибка, то истинной считается та комбинация, от которой принятая наименее отличается. Это достаточно сложная задача, приводящая к громоздким техническим решениям. Поэтому разрабатываются специальные коды, строение которых позволяет осуществить декодирование более простыми способами. Примером таких кодов являются систематические коды. Число информационных знаков определяется числом N различных сообщений, которые нужно передать, т. е. N = 2*. Из г контрольных знаков образуется 2' двоичных комбинаций. Число г определяется в зависимости от ситуации:
- • указать, есть ли ошибка или нет;
- • если ошибка есть, то указать, в какой из п позиций она находится.
Исправление сводится к замене в указанном месте нуля единицей или наоборот. Таким образом, нужна одна кодовая комбинация для ответа «да» или «нет» на вопрос о наличии ошибки и п кодовых комбинаций для указания номера ошибочной позиции. Отсюда должно выполняться неравенство.
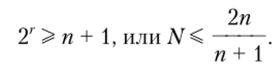
Итак, повышение помехоустойчивости, достигаемое с помощью корректирующих кодов, связано с увеличением значности кода, что предполагает либо увеличение длительности передаваемого сигнала, либо расширение полосы его частот, занимаемой сигналом.