Статистические гипотезы в маркетинге: основные положения проверки и выводы

Почему проверку гипотез проводят в условиях неопределенности? Ответ очевиден. В случае расчетов показателей совокупности, исходя из полной информации, получаем реальную характеристику совокупности, т. е. сразу получаем искомый параметр 0. И еще один вопрос: нам необходимо найти величину параметра 0, но зачем при этом заменять интервальную оценку — (c) — О — процедурой проверки статистической… Читать ещё >
Статистические гипотезы в маркетинге: основные положения проверки и выводы (реферат, курсовая, диплом, контрольная)
Информация, полученная на основе выборки, используется для характеристики генеральной совокупности либо в виде чисел (точечная оценка, а также и интервальное оценивание) либо как утверждение или допущения — тогда это статистическая гипотеза. В чем необходимость обращения к гипотезам? Иногда сравнение каких-либо явлений или процессов проводят на интуитивном уровне. Умозрительно можно сравнивать и конкретные величины. Если говорить о статистике, то часто на практике расхождение между вычисленным значением средней величины выборки и гипотетическим значением генеральной средней бывает большим. В такой ситуации трудно полагаться на интуицию или здравый смысл, и тогда выдвигается предположение или гипотеза. Возникает необходимость в разработке процедуры, обеспечивающей обоснование принимаемого решения.
Например, возникает допущение или гипотеза, что в крупной транспортной компании все водители работают эффективно. Руководство фирмы предполагает, что 85—90% грузов доставляется в срок. Однако разброс данных велик, и реально получить количественный ответ без процедуры применения статистических гипотез трудно.
Формально проверка гипотез заключается в последовательности действий по установлению критических пределов для оценки значимых отклонений вычисленной характеристики выборки от предполагаемого значения генеральной совокупности.
Гипотеза необязательно должна быть верной, она может быть и неверной, поскольку для решения этого вопроса применяют выборку. Статистические гипотезы применяют только к случайным числам, т. е. в условиях неполной информации.
При наличии неопределенности (случайные величины и выборка) проверка статистических гипотез позволяет максимально использовать имеющуюся неполную информацию.
Итак, во многих случаях делают допущения относительно исходной генеральной совокупности, которые требуют объективной проверки. Допущения могут быть подтверждены или, наоборот, отвергнуты с помощью критериев проверки гипотезы. В этих критериях задействованы понятия вероятности.
Проверка статистических гипотез позволяет на основе имеющейся информации сделать выбор между двумя версиями или предположениями. Эти предположения и являются гипотезами. Например, гипотезы позволяют подтвердить или отклонить вывод о том, что величина себестоимости продукции фирмы М выше, чем у фирмы N.
Как и в случаях точечной оценки или интервального оценивания, проверка статистических гипотез проводится при неполной информации, т. е. по выборочному наблюдению. Однако если в качестве точечной оценки рассматривалась одна из статистик и она сравнивалась с соответствующим параметром ГС, то при проверке статистических гипотез действия обратные. Еще до получения выборочных данных значение неизвестного параметра 0 генеральной совокупности называют заранее (значение 0 — это гипотеза). Затем проводятся выборка, расчет выборочных данных; определяется статистический критерий Z, по которому принимают или отклоняют параметр 0.
Почему проверку гипотез проводят в условиях неопределенности? Ответ очевиден. В случае расчетов показателей совокупности, исходя из полной информации, получаем реальную характеристику совокупности, т. е. сразу получаем искомый параметр 0. И еще один вопрос: нам необходимо найти величину параметра 0, но зачем при этом заменять интервальную оценку | (c) — О | процедурой проверки статистической гипотезы? Дело в том, что зачастую бывают ситуации, когда значение неизвестного параметра нам навязывают либо внешние обстоятельства, либо внутренние. Словом, с этим фактом приходится считаться и принимать его во внимание. Например, гипотеза об объеме инвестиций — хватит ли заданной величины капитальных вложений для увеличения объема производства; оправдает ли технологическое новшество (например, изменение состава сырья) предполагаемую гипотезу — конкретную величину (допустим, в виде процента) улучшения качества продукции. Либо предлагают разместить рекламу продукции в престижном журнале и заранее называют цифру увеличения дохода от продаж и т. д.
Статистические гипотезы подразделяются на два вида: параметрические и непараметрические.
Параметрические гипотезы — это предположения численных величин отдельных параметров (среднего значения, медианы или дисперсии). Кроме того, рассматриваются случаи, когда выбирается иной, не статистический параметр генеральной совокупности. Например, изучается показатель «доля рабочих, не выполняющих сменное задание».
Значения величин, лежащих вне ожидаемого интервала, куда попадает неизвестный параметр, называют значимыми, поэтому параметрические гипотезы оценивают по критериям значимости. Кроме того, в данном случае проверка гипотез может быть как односторонней, так и двухсторонней; при этом важным является показатель «мощность критерия».
Непараметрические гипотезы — это предположения о форме распределения генеральной совокупности — какому закону распределения подчиняется эта совокупность. Когда проверяют непараметрические гипотезы, то оценивают, согласуется ли выборочное наблюдение с заранее заданным законом распределения, который был назван для генеральной совокупности. Иными словами, согласуется ли реальный закон распределения с гипотетическим. Таким образом, непараметрические гипотезы проверяют по критериям согласия.
В данном учебном пособии рассматриваются только параметрические гипотезы.
Статистическая гипотеза — это предположение о величине неизвестного параметра 0, проверяемое по величине статистического критерия к, который получен по результатам выборочного наблюдения.
Назовем основные случаи, в которых используются методы проверки статистических гипотез. Это проверка равенства:
- • средних величин двух совокупностей, когда генеральная дисперсия известна;
- • средних величин двух совокупностей, когда генеральная дисперсия неизвестна;
- • дисперсий двух совокупностей (выборочной и генеральной);
- • средних величин при известных генеральных дисперсиях (две совокупности, и обе генеральные);
- • параметров двух совокупностей (выборочной и генеральной)
и, наконец, проверка однородности выборки (исключаются «выбросы» данных или очень резкие отклонения данных).
Говоря о статистических гипотезах, следует иметь в виду, что выдвигаются два вида предположений:
- 1) неизвестен статистический закон распределения случайных величин, образующих генеральную совокупность. Это случай — непараметрические гипотезы;
- 2) нет значений параметров СВ при известном статистическом законе распределения этих величин в ГС — это параметрические гипотезы.
Заметим, что параметрические гипотезы всегда рассматриваются только попарно, причем такие гипотезы взаимно исключают друг друга и называются нулевая (Н0) и альтернативная (Нх) гипотезы. Если гипотеза включает только одно условие (число), она является простой. Нулевая гипотеза Н0 всегда одна, поэтому она является простой гипотезой. Когда гипотеза имеет несколько условий, толкований или версий — это сложная гипотеза. Как правило, альтернативная гипотеза Hj — сложная, так как может иметь несколько высказываний (условий). Конечно, гипотеза Н, может быть одна, а может их быть и несколько. Последнее связано с тем, что количество альтернативных предположений, или гипотез, определяется конкретной ситуацией рассматриваемого процесса или случая. Иными словами, гипотеза На формулируется в зависимости от того, сколько ответов мы хотим получить.
Нулевая гипотеза Н0 — это гипотеза о величине неизвестного параметра генеральной совокупности, причем этот параметр задается заранее. Она должна формулироваться так, чтобы можно было использовать один из следующих законов распределения:
- • Ф (?) — нормальное распределение, или функция Лапласа;
- • Ф (Г) — распределение Стьюдента;
- • X2 — распределение Пирсона (хи-квадрат);
- • F — распределение Фишера — Снедекора.
В основном будем исходить из того, что генеральная совокупность имеет нормальное распределение. Наряду с гипотезой Н0 выдвигают альтернативную гипотезу Нх. Ее еще называют исследовательской и принимают только тогда, когда получено убедительное статистическое доказательство.
Альтернативная гипотеза Нг — это гипотеза, которая принимается, если в результате статистической проверки отвергается нулевая гипотеза.
Например, рассмотрим случай, когда проверяется, равна ли генеральная средняя р величине выборочной х. При этом могут быть сформулированы три альтернативные гипотезы Н:
1) первый вариант:
Н0: Ц = *_,.
Нр р Ф х
2) второй вариант:
Н0: р = *,.
Нр р > х;
3) третий вариант:
Н0: Р = х>
Нр р < х.
Поэтому следует точно формулировать гипотезу Hj. Если мы хотим узнать, равны или не равны средние величины двух совокупностей (генеральной и средней), то рассматриваем первый вариант. В случае поиска ответа на вопрос, превышает или нет параметр генеральной совокупности данное значение, альтернативная гипотеза принимается как второй вариант и т. д.
Отметим, что при написании гипотезы Н0 или гипотезы Н] всегда ставится двоеточие и пишется «Н0:» или «Нр».
Процедура проверки нулевой гипотезы. Статистическая проверка — это проверка гипотезы, для того чтобы или принять ее, или отклонить. Она выполняется на основе статистического критерия, приведенного к стандартизированной форме, или стандартизированного статистического критерия.
Применительно к нормальному распределению статистический критерий к имеет формулу.
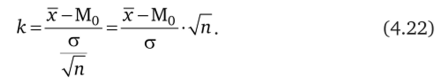
где х — выборочная средняя; М0 — гипотеза, заданное значение средней величины генеральной совокупности (ГС); о — среднее квадратическое отклонение в ГС; п — объем выборочного наблюдения (выборки), по которому рассчитывается средняя величина х.
Ниже приведен алгоритм проверки статистических гипотез.
- 1. Формируем нулевую гипотезу Н0. При этом могут возникнуть два случая:
- а) нулевая гипотеза Н0 называется сразу. Это тот параметр генеральной совокупности, который либо называем мы, либо его называют нам, и который следует проверить;
- б) нулевая гипотеза Н0 называется после проведения выборочного наблюдения. Например, из генеральной совокупности проводят бесповторную выборку и в каждом отобранном изделии проверяют качество, его показатель Хср. Далее, располагая выборочными данными Хь Х2, …, Хп по характеристике выборки, например средней величине Хср, формируется нулевая гипотеза Н0.
- 2. После того как известна нулевая гипотеза Н0, выдвигаем (называем) альтернативную гипотезу Hj.
- 3. Задаем уровень значимости, а (как правило, 0,05 или 0,01; ОД или 0,001).
- 4. Рассчитываем статистический критерий Z.
- 5. Для двусторонней проверки или односторонней проверки с учетом значимости определений смотрим, куда попадает критерий Z: если в критическую область (рис. 4.2), то Н0 отвергается; в противном случае нулевая гипотеза Н0 принимается.
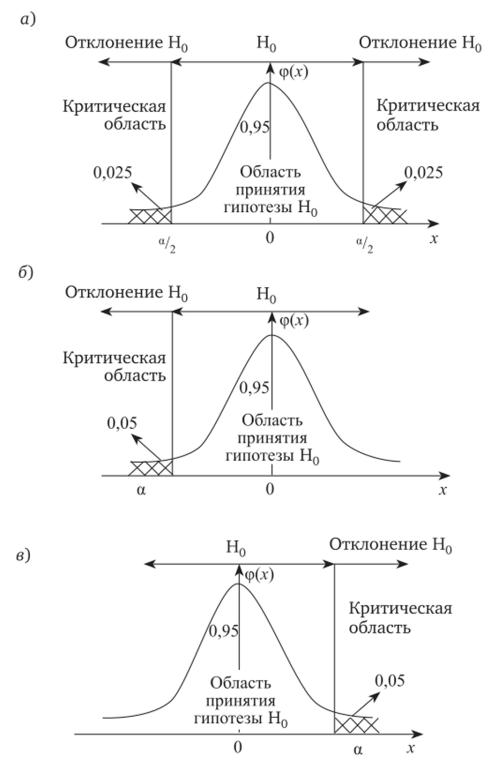
Рис. 4.2. Проверка статистических гипотез с уровнем значимости а = 0,05: а — двухсторонняя проверка а/2; б — левосторонняя проверка; в — правосторонняя проверка:
ф (х) — плотность распределения нормированной случайной величины х, распределенной по нормальному закону Ошибки первого и второго рода. Мощность статистического критерия. Очевидно, что на основе статистических данных с участием случайных величин трудно, а иногда невозможно делать безошибочные выводы. Не являются исключением и выводы, которые делают на основании проверок статистических гипотез — возникают ошибки 1-го и 2-го рода.
Итак, как и в двух предыдущих случаях (точечной оценки и интервального оценивания), на этот раз снова речь идет о точности метода, вернее о правильности, принятия нулевой гипотезы Н0 — заранее названного параметра генеральной совокупности.
Рассмотрим пример на проверку нулевой гипотезы.
Пример 4.8.
Выдвинем нулевую гипотезу, связанную с параметром р — Н0: р = 16,75. Мы не знаем средней величины единиц признака ГС. Из нее провели выборку, допустим, со следующими результатами:
Xi | ||||
Si |
Для данной выборки Хср = 16,75. Предположим, что действительное значение средней величины р в ГС равно 16,75, тогда получим несмещенную нулевую гипотезу Н0, как показано на рис. 4.3.

Рис. 4.3. Несмещенная нулевая гипотеза Н0: р= 16,75:
Oj и П2 — два множества чисел, которые принадлежат ГС; х — единицы признака выборки По выборке получили среднюю величину XQp = 16,75, которая подтвердила нулевую гипотезу Н0. Действительное значение р в ГС равно 16,75.
Нулевая гипотеза Н0 редко бывает несмещенной и, как правило, появляется интервал, определяющий, насколько значение Н0 отличается от значения ц. Рассмотрим случай — совокупность данных ГС подчиняется нормальному закону распределения. Принцип проверки статистических гипотез очень прост: событие, которое попадает в критическую область, маловероятно. При принятии или отклонении нулевой гипотезы Н0 возникают ошибки 1-го рода и 2-го рода.
При проверке гипотез (по выбранному критерию) возможны два вида неправильных решений:
- 1) неправильное отклонение нулевой гипотезы — это ошибка 1-го рода;
- 2) неправильное принятие нулевой гипотезы — это ошибка 2-го рода.
Сведем эти ошибки в табл. 4.4.
Таблица 4.4
Виды ошибок при рассмотрении решений, связанных с проверкой статистической гипотезы.
Нулевая гипотеза НО. | Принятое решение. | |
ОТКЛОНИТЬ. | принять. | |
В действительности гипотеза. | Верна. | Неверна. |
Ошибка. | 1-го рода, вероятность а. | 2-го рода, вероятность (S. |
Примечание, а — уровень значимости, или область, где появление единиц признака маловероятно. Например, при а = -0,05 только 5 единиц признака из 100 попадут в область значений, ограниченных а; р — вероятность ошибки 2-го рода.
Заметим, что чем меньше уровень значимости а, тем меньше вероятность отклонить, или забраковать, проверяемую гипотезу, т. е. меньше риск совершить ошибку 1-го рода. На самом деле, если уровень значимости очень мал (например, а = 0,001), то практически во всей совокупности (кроме 0,1% значений признака) нулевая гипотеза Н0 «работает», и какой же смысл эту гипотезу отклонять? Уровень значимости, а критерия проверки Z контролирует лишь ошибки 1-го рода, но совсем не измеряет степень риска, связанного с принятием неверной гипотезы (т.е. с возможностью ошибки 2-го рода). Значит, помимо величины, а и само положение критической области, гарантирующей величину а, тоже может влиять на качество решения, связанного с принятием или отклонением статистической гипотезы.
Рассмотрим ситуацию, когда при заданном уровне значимости, а = = 0,05 на кривой нормального распределения по-разному располагается критическая область (она соответствует величине, а = 0,05). Изучим четыре положения критической области.
I. Вся критическая область размещена справа. Тогда величина единиц наблюдения х, попадающих в критическую область, определяется из неравенства.

где ц — средняя величина ГС; t — нормированный коэффициент; а — среднее квадратическое отклонение данных в ГС.
И. Вся критическая область размещена слева, тогда.

III. Критическая область разделена пополам и находится симметрично и слева, и справа от величины ц: 
IV. Критическая область также разделена надвое и размещена в центре, где располагается симметрично по отношению к ц:

Обычно в литературе эти размещения критической области получили наименования:
I — область больших положительных отклонений;
II — область больших отрицательных отклонений;
III — область больших по абсолютной величине отклонений;
IV — область малых по абсолютной величине отклонений. Приведем пример на применение этих критических областей.
Пример 4.9.
Принимаем величину, а = 1 и в соответствии с указанными расположениями и напишем итоговые формулы вероятности Р для критических областей.
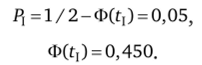
Из таблицы функции Лапласа для (Z) = 0,450 находим Z = 1,645. Следовательно, нормированный коэффициент Г, = 1,645.
На рис. 4.4 проведена функция плотности кривой нормального распределения 0(t). Значит, t= 1,645 определяет границу допустимых значений.
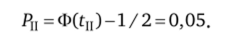
Аналогично п. I ползшим tn = —1,645.
Если ранее (в пунктах I и II) рассматривались только правая или только левая части плотности распределения (площадь половины такой функции равна ½), то в данном случае рассматриваем всю функцию целиком: ее площадь равна 1. С учетом того, что имеем две критические области, >фавнение вероятности примет вид.
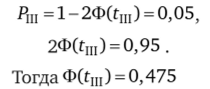
Табличное значение Z для функции (Z) = 0,475 составляет Z = 1,960. Следовательно, нормированный коэффициент tln = 1,960. Поскольку область отклонений берется по модулю, то на графике рис. 4.4 по оси абсцисс с двух сторон от значения х = ц откладываем tm = 1,960.
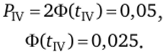
В этом случае критическая область удвоена, и вся область размещена в центре функции плотности распределения.
Для tw= 0,0564.
Именно интервал 2tIV = 2 • 0,0564 = 0,1128 определяет область «непопадания» отдельных единиц признака в значение х, = р.
Как видно на рис. 4.4, от того, где будет находиться критическая область, во многом зависит, правильно или нет принято решение по гипотезе Н0.
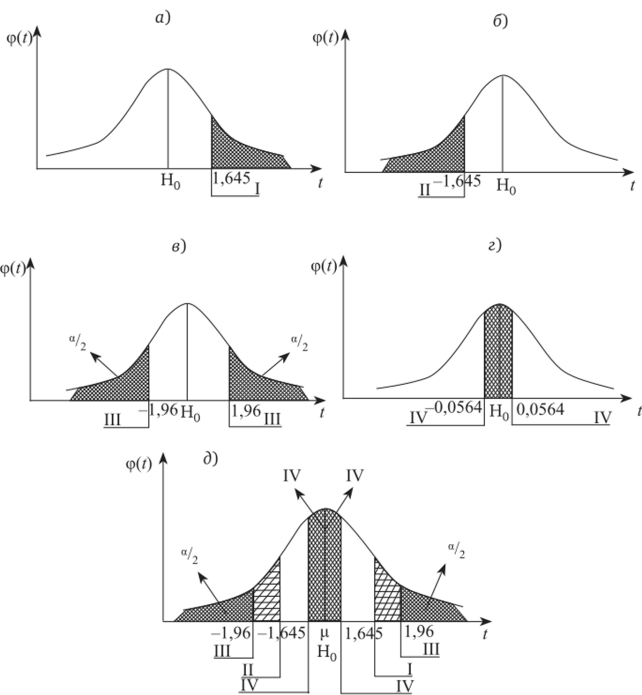
Рис. 4.4. Размещение критических областей, связанных с уровнем значимости, а = 0,05, на кривой стандартной функции плотности, а — критическая область расположена справа; б — критическая область расположена слева; в — критическая область разделена пополам; г — критическая область расположена вдоль центра функции распределения; д — объединение расположения критических областей Рассмотрим совокупность данных, имеющую нормальное распределение. Требуется проверить нулевую гипотезу Н0.
Пример 4.10.
Исходная совокупность данных приведена в табл. 4.5.
Таблица 4.5
Исходная совокупность данных (х, и f;), промежуточные расчеты и значения нормированных коэффициентов 1, и функции плотности.
fi | xi‘fi | (*, — И). | (Х;-Ц)2 | а. | <�р (0. | |
1,6. | 14,4. | — 1,1. | 10,89. | — 2,16. | 0,0387. | |
1,8. | 37,8. | — 0,9. | 17,01. | — 1,76. | 0,0387. | |
2,1. | 67,2. | — 0,6. | 11,52. | — 1,18. | 0,0387. | |
2,4. | 139,2. | — 0,3. | 5,22. | — 0,59. | 0,0387. | |
2,6. | 195,0. | — од. | 0,75. | — 0,20. | 0,0387. | |
зд. | 186,0. | 0,4. | 9,60. | 0,78. | 0,0387. | |
3,2. | 124,8. | 0,5. | 9,75. | 0,98. | 0,0387. | |
3,4. | 85,0. | 0,7. | 12,25. | 1,37. | 0,0387. | |
3,5. | 45,5. | 0,8. | 8,32. | 1,57. | 0,0387. | |
3,8. | 7,6. | 1Д. | 2,42. | 2,16. | 0,0387. | |
Итого. | 902,5. | —. | 87,73. | —. | —. |
Для данной совокупности средняя величина равна 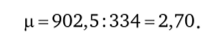 Среднее квадратическое отклонение, а равно
Среднее квадратическое отклонение, а равно 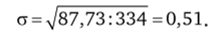 В табл. 4.5 также рассчитан нормированный коэффициент Г:
В табл. 4.5 также рассчитан нормированный коэффициент Г:

Из таблицы функции плотности ф (Г) для нормального распределения выписаны значения этой функции для каждой величины Г. Заметим, что в таблицах для значений t даются функции ф (?) и функция Лапласа Ф (г) (аргументы этих функций могут иметь обозначение t, или х, или Z). Ранее в данном пособии функцию Лапласа писали как (Z).
Отметим, что если взять дополнительную единицу совокупности, например х, — = 2,7, то для нее t = 0 и ф (0= 0,3989 — это максимальное значение: ф (0т;, х = 0,3989. Значение х, = 2,7 в ст.1 табл. 4.5 расположилось бы между значениями х, — = 2,6 и х, = 3,1. Следует проверить нулевую гипотезу Итак, в качестве генеральной совокупности возьмем совокупность, указанную ранее (табл. 4.5), но условимся, что средняя величина ц = 2,7 неизвестна. Выберем критическую область, расположенную в центре (рис. 4.4, г). Затем выдвинем нулевую гипотезу Н0: |i = 2,7 (напомним, было условлено, что значение ц неизвестно). Альтернативная гипотеза Hj: р Ф 2,7. Проведем выборочное наблюдение из ГС, и если получим р = 2,7, то, казалось бы, получим подтверждение тому, что р = 2,7. Однако это значение точно попадает в критическую область (рис. 4.4, г), поэтому отвергаем Н0, совершая ошибку 1-го рода.
Переходим к понятию «мощность критерия». Ошибки 1-го и 2-го рода связаны с неправильными решениями. Правильные решения выполняются, если вероятность равна Р = 1 — а, в этом случае верна гипотеза Н0, а если 1 — (3, то верна гипотеза Нг.
Критерий называют «мощным», если при заданном уровне значимости, а он обладает наименьшей вероятностью (3, т. е. наименьшей вероятностью совершения ошибки второго рода.
Мощность критерия — это вероятность того, что нулевая гипотеза Н0 будет отвергнута, когда верна гипотеза Hj. То есть это вероятность попадания в критическую область, а (т.е. область, где отвергается гипотеза Н0) при условии, что справедлива конкурирующая гипотеза Нх.
Почему вводится понятие «мощность критерия»? Конечно, это связано с надежностью, или правильностью, принятого решения: чем выше мощность критерия, тем чаще отвергается неверная гипотеза Н0.
Как можно сделать так, чтобы редко совершать ошибки 1-го и 2-го рода или совсем не ошибаться? Увы, это невозможно, поскольку при фиксированном объеме выборки можно по своему усмотрению задать только одну величину: либо а, либо (3; следовательно, увеличение вероятности одной из них приводит к снижению другой. Как правило, задан уровень значимости, а — это связано с тем, что с практической точки зрения важнее величина а. Вероятность ошибки 2-го рода еще называют оперативной характеристикой критерия. Так вот, предпочтение критерию а по сравнению с критерием Р связано с тем, что они имеют совершенно разную физическую природу. Например, пусть, а — это брак продукции, а Р — годные изделия. Пропуск отделом технического контроля бракованных изделий (отвергнута Н0, допущена ошибка 1-го рода с вероятностью ошибки а) влечет за собой значительно более тяжелые последствия, чем выбраковка годных изделий (принята Н0, допущена ошибка 2-го рода с вероятностью Р).
Итак, задаем величину а (0,05; 0,025 и т. д.), с ней связана величина р. Мощность критерия определяется величиной (1 — Р). Чем мощнее построенный критерий, тем он лучше «улавливает» отклонения от основной гипотезы Н0и больше величина (1 — Р). Вероятность ошибки второго рода Р (или риск второго рода) трудно контролировать, и она зависит:
- 1) от уровня объема выборки: чем больше величина п (число элементов выборки), тем надежнее будет установлено различие между Н0 и На;
- 2) расстояния между центрами выборки Н0 и выборки Hj;
- 3) выбора расположения критической области;
- 4) выбора статистического критерия Z.
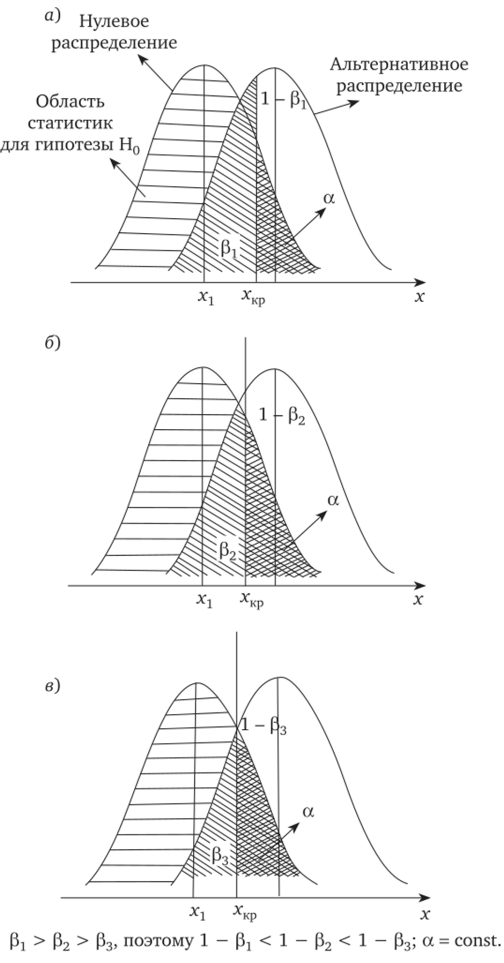
Рис. 4.5. Возрастание мощности критерия при увеличении расстояния между центрами нулевого распределения (выборки для гипотезы Н0: р = х1) и альтернативного распределения (выборки для гипотезы Н: х = х^):
мощность критерия увеличивается от, а к в; штриховка — это область статистики для гипотезы Н0
Выше указывалось, что-либо нулевая гипотеза Н0 называется сразу (например, предполагаемый доход либо увеличение выпуска продукции), либо ее выдвигают на основании выборки, сделанной из генеральной совокупности (например, проводится измерение веса пачек какого-либо продукта, а затем называется средняя величина веса Н0 для всей партии продукта). Именно в последнем случае и нулевая гипотеза Н0, и альтернативная гипотеза Hj имеют свои выборки и распределения.
При проверке статистических гипотез можно между собой сравнивать не только выборочные, но и генеральные совокупности. На рис. 4.5 предложено распределение двух выборочных совокупностей: одно из них принадлежит Н0 (это нулевое распределение), другое — альтернативной гипотезе Нх (альтернативное распределение).
Как видно на данном рисунке, чем больше расстояние между вертикальными линиями Xj и хкр, т. е. (хх — хкр), тем больше расстояния между центрами двух выборок.
При этом увеличивается надежность статистического вывода, связанного с проверкой гипотез. На рис. 4.5 значение точки хкр — это критическая величина, которая разделяет значения критической области а и значения вероятности р. При сдвиге хкр вправо растет расстояние между центрами распределений для гипотез Н0 и Hl5 уменьшается величина Р, тем самым растет величина (1 — Р) и увеличивается надежность принятия решения при проверке статистической гипотезы Н0.
В данном случае величина, а была постоянной и при выбранной области вероятность Р ошибки 2-го рода была выбрана минимальной, что соответствовало наибольшей мощности критерия. Как видно на рис. 4.5, область статистики для нулевой гипотезы расширяется. В нашем случаем была выбрана статистика 3q — это средняя величина. В качестве статистики можно выбрать и другой параметр нулевого распределения.
В заключение отметим, что непараметрические критерии, связанные с изучением законов распределения данных (например, когда сравнивается закон распределения, выдвинутый в качестве нулевой гипотезы, с действительным законом распределения единиц признака в генеральной совокупности), обладают меньшей мощностью, чем параметрические. Это означает, что первые требуют значительно больший объем выборочного наблюдения, чтобы по критериям согласия можно было принять или отвергнуть заранее выдвинутый закон распределения данных.