Дескриптивный анализ и разработка выборочного плана

В районе города проживает 4000 семей. Нужно определить методом случайного бссповторного отбора необходимую численность опрашиваемых при условии, что ошибка выборочной средней не должна превышать 0,35 семьи с вероятностью 0,954 и среднем квадратическом отклонении две семьи, а также определить, какой должна быть численность отбора семей с одним ребенком с вероятностью 0,950, чтобы ошибка выборки… Читать ещё >
Дескриптивный анализ и разработка выборочного плана (реферат, курсовая, диплом, контрольная)
При проведении маркетинговых исследований используют следующие виды статистического анализа:
- 1) дескриптивный анализ, предполагающий использование таких статистических показателей, как средние величины, структурные средние: мода и медианы, среднее квадратическое отклонение, показатели вариации;
- 2) выводной анализ — использование статистических процедур (например, проверка гипотез) с целью обобщения полученных результатов на всю совокупность;
- 3) анализ различий используется для сравнения результатов исследования двух групп (двух рыночных сегментов) для определения степени реального различия в их поведении, в реакции на одну и ту же рекламу и т. п.
- 4) анализ связей направлен на определение систематических связей (их направленности и силы) переменных (например, для определения того, как увеличение затрат на рекламу влияет на увеличение сбыта);
- 5) предсказательный анализ используется в целях прогнозирования развития событий в будущем.
Прежде чем рассматривать использование дескриптивного анализа в маркетинговых исследованиях, необходимо определиться с ролью наблюдения в маркетинговых исследованиях.
Статистическое наблюдение — первый этап статистического исследования, в том числе маркетингового исследования социально-экономических процессов и явлений, представляющий собой научно организованный сбор (учет, регистрация) сведений по заранее разработанному плану.
Статистическое наблюдение может реализовываться двумя способами:
- 1) посредством отчетности по установленным формам, в установленные сроки (при этом отчетность может быть типичной, т. е. иметь одинаковую форму и содержание для всех субъектов деятельности, и специальной, т. е. выражать отдельные (специфические) стороны отдельных предприятий);
- 2) посредством специально организованных обследований (например, проведение переписи).
Для того чтобы статистическое наблюдение было полным, достоверным и своевременным, обязательно составляются план и программа статистического наблюдения.
План статистического наблюдения представляет собой перечень мероприятий, необходимых для успешного выполнения работы по сбору и обработке материалов, с указанием сроков и исполнителей.
Программа статистического наблюдения представляет собой перечень вопросов, по которым нужно получить сведения в отношении каждой исследуемой единицы в процессе наблюдения, и состоит из двух частей — адресной и содержательной.
Адресная часть включает:
- а) местоположение наблюдаемой единицы;
- б) объект наблюдения — совокупность лиц, явлений, предметов, подвергаемых статистическому наблюдению и имеющих общие признаки, например население страны или региона, предприятия или учебные заведения страны или региона и т. д.;
- в) единица наблюдения — составной элемент объекта наблюдения, его первичную ячейку, являющуюся источником информации, носителем признаков, подлежащих регистрации при проведении статистического наблюдения, например домохозяйство и его жильцы, компания, фирма, фермерское хозяйство и т. д.;
- г) единица совокупности — носитель признаков и начальной информации, образующих статистическую совокупность, например во время переписи — каждый конкретный человек, при регистрации проданных квартир — каждая квартира и т. д.
Понятия единицы совокупности и единицы наблюдения могут совпадать.
Содержательная часть представляет собой перечень вопросов, на которые необходимо получить ответы и которые должны обеспечивать полноту и достоверность начальных статистических данных. При этом вопросы должны быть сформулированы достаточно четко, понятно и в логической последовательности, чтобы избежать получения лишней информации, которая может повлечь за собой дополнительные трудовые и финансовые расходы.
Для обеспечения стандартизации получаемых сведений используют документ единого образца, содержащий программу и результаты наблюдения (статистический формуляр).
Статистическое наблюдение может классифицироваться по ряду признаков.
- 1. По степени охвата единиц выделяют следующие виды статистического наблюдения:
- а) сплошное — обследуются все без исключения единицы совокупности (например, перепись населения);
- б) несплошное — обследуется лишь часть единиц совокупности. Этот вид, в свою очередь, подразделяется на следующие подвиды:
- — выборочное наблюдение — обследованию подлежит часть единиц совокупности, полученная на основе случайного отбора. Например, чтобы узнать среднюю цену товара А, производится отбор нескольких случайных магазинов, и на основе полученных данных дается представление о средней цене,
- — анкетное наблюдение — обследование происходит на основе анкет, предоставленных физическим или юридическим лицам, например анкетный опрос покупателей с целью выяснения удовлетворенности ими товарами данной компании,
- — монографическое наблюдение — обследование отдельных единиц совокупности носит подробный и полный характер, например обследование технологии производства новых видов продукции,
- — способ основного массива — обследование той части совокупности, которая имеет наибольший удельный вес в общем объеме совокупности, например обследование наиболее крупных торговых компаний в общей структуре товарооборота.
- 2. По времени регистрации данных выделяют следующие виды статистического наблюдения:
- а) текущее — наблюдение происходит постоянно по мере возникновения данных, например налоговая отчетность компаний;
- б) периодическое — обследование проводится через определенные промежутки времени, например перепись населения;
- в) одноразовое — наблюдение единовременно происходит в определенный период времени, например обследование определенного числа жителей района на выявление заболеваний с целью подтверждения либо опровержения научной точки зрения при написании диссертации.
При проведении статистического наблюдения необходимо в обязательном порядке обозначить критический момент наблюдения. Под критическим моментом наблюдения понимают конкретный момент, к которому приурочены собираемые сведения. Так, критическим моментом переписи может быть 00 ч 00 мин 2 сентября соответствующего года, а значит, перепись будет проведена по состоянию на определенную дату.
Статистическая сводка — второй этап статистического маркетингового исследования социально-экономических процессов и явлений, представляющий собой первичную научно организованную обработку материалов наблюдения (но заранее разработанной программе) и включающий в себя кроме обязательного контроля собранных данных систематизацию, группировку материалов, составление таблиц, получение итогов и производных показателей (средних, относительных величин) с целью получения обобщающих сведений изучаемого явления по ряду типичных признаков.
Статистическая группировка — разбиение совокупности на группы, однородные по определенному признаку, либо объединение единиц совокупности в однородные группы, имеющие общие черты, с целью:
- — выделения социально-экономических типов явлений и процессов;
- — определения характеристики структуры совокупности и структурных сдвигов в пределах выделенных социально-экономических типов явлений и процессов;
- — выявления взаимосвязи и взаимозависимости между изучаемыми явлениями и процессами.
Ряд распределения — это первичный результат группировки, который представляет собой упорядоченное распределение единиц совокупности на группы по определенному изучаемому варьирующему признаку.
В зависимости от характера изучаемого признака ряды подразделяются:
1) на атрибутивные — когда варьирующий признак не имеет количественного выражения, например распределение населения по возрасту, рабочих — по стажу (частным случаем данного ряда является альтернативный признак, когда единицы совокупности имеют изучаемый признак (при этом его числовое значение равно 1) или данный признак отсутствует (при этом его числовое значение равно 0));
- 2) вариационные — варьирующий признак имеет количественное выражение, при этом данный ряд может подразделяться на следующие подвиды:
- а) дискретные — варианты представлены целыми значениями признака, например распределение семей по количеству детей,
- б) интервальные — варианты представлены числовыми интервалами, т. е. величина признака у единиц совокупности может принимать в определенных пределах любые значения (целое или дробное), например распределение цен на продукты в магазинах определенной территории.
В каждом ряду распределения можно выделить следующие основные элементы:
- а) вариант — конкретное значение варьирующего признака;
- б) частота — числа, показывающие, как часто встречаются варианты в ряду распределения;
- в) частость — частоты, выраженные в долях единицы или процентах к итогу;
- г) накопленная частота — численность единиц, образуемая путем суммирования предыдущих частот от группы к группе, т. е. нарастающим итогом.
Для построения ряда распределения необходимо выделить количество групп, при этом чем сильнее вариация, тем большее число групп нужно выделить. Затем следует определить интервал группировки по следующей формуле:

где i — интервал группировки; xmax — максимальное значение признака в группе; хт[п — минимальное значение признака в группе; п — число групп.
Пример 5.8.
Имеются следующие данные об объеме продаж сети розничных магазинов и их прибыли (табл. 5.12). Нужно построить ряд распределения по объему продаж розничных сетей, образовав три группы, и определить, существует ли зависимость между прибылью и объемом продаж.
Таблица 5.12
Объем продаж и прибыль розничных сетей, млн ден. ед.
Номер розничной сети по списку. | Объем продаж. | Прибыль. |
4,5. | 3,2. | |
6,8. | 4,4. | |
7,1. | 5,1. | |
3,0. | 2,8. | |
9,8. | 6,9. | |
9,4. | 6,7. | |
10,2. | 7,5. | |
12,0. | 8,1. | |
3,7. | 3,0. |
Решение
С помощью форулы (5.1) находим величину равных интервалов: i = (12,0 — 3,0) /3 = 3 млн дсн. сд.
Составим ряд распределения розных сетей по объему продаж в интервалах 3−6; 6−9; 9−12 (табл. 5.13).
Таблица 5.13
Ряд распределения розничных сетей по объему продаж.
Группы розничных сетей по объему продаж, млн ден. ед. | Число розничных сетей в группе. | Число розничных сетей, проценты к итогу. | Число розничных сетей нарастающим итогом. |
3−6. | 33,33. | ||
6−9. | 22,22. | ||
9−12. | 44,45. | ||
Итого. | —. |
Первый интервал означает, что объем продаж составит не менее 3 млн деи. ед., но и не более 6 млн ден. ед., а значит, розничные сети с объемом продаж в 6 млн ден. ед. войдут уже во вторую группу. Такой подход к формированию групп остается далее при построении ряда распределения. И исключение составляет последняя группа, которая, как в данном случае, будет включать в себя розничную сеть с объемом продаж 12 млн ден. ед.
Далее следует разделить единицы совокупности на группы по факторному признаку — объему продаж, от которого может зависеть прибыль. Однако перед построением аналитической таблицы рекомендуется составить рабочую таблицу (табл. 5.14).
Таблица 5.14
Рабочая таблица.
Группы розничных сетей по объему продаж, мли ден. ед. | Номер розничной сети. | Прибыль, мли деи. ед. |
3−6. |
|
|
Итого. | ||
6−9. |
|
|
Итого. | 9,5. | |
9−12. |
|
|
Итого. | 29,2. | |
Всего. | 47,7. |
На основе данных рабочей таблицы можно построить аналитическую таблицу (табл. 5.15) и ответить на вопрос: «Существует ли зависимость между прибылью и объемом продаж розничной сети?».
Зависимость прибыли от объема продаж розничных сетей, млн ден. ед.
Группы розничных сетей по объему продаж. | Количество розничных сетей в группе. | Прибыль. | |
всего по группе. | в среднем на одну розничную сеть. | ||
3−6. | |||
6−9. | 9,5. | 4,75. | |
9−12. | 29,2. | 7,3. | |
Итого. | 47,7. | 5,3. | |
Анализ табл. 5.15 показал, что с ростом объема продаж от группы к группе возрастает прибыль розничных сетей, а значит, между ними существует взаимосвязь.
Для характеристики изучаемой совокупности в маркетинговых исследованиях в целом используют средние величины и показатели вариации, которые и составляют дескриптивный анализ.
Средняя величина — это обобщающий показатель, характеризующий изучаемый признак в исследуемой маркетинговой совокупности. Он выражает уровень признака, отнесенный к единице совокупности в определенных условиях места и времени.
Вычисление среднего показателя является одним из распространенных приемов обобщения, поскольку данный показатель показывает общую тенденцию, которая характерна для всех единиц изучаемой совокупности, в то же время он игнорирует различия отдельных единиц.
Основными условиями применения средних величин являютея:
- а) массовый характер совокупности;
- б) качественная однородность совокупности.
В зависимости от исходной статистической информации и характера признака, который усредняется, выделяют следующие основные виды средних величин:
- а) средняя арифметическая;
- б) средняя гармоническая;
- в) средняя квадратическая;
- г) средняя геометрическая.
Рассмотрим подробно ее первые два вида, которые применяются чаще всего.
Средняя арифметическая величина является наиболее распространенной в практическом применении и подразделяется на следующие два вида.
1. Простая средняя арифметическая применяется, когда известны индивидуальные значения усредняемого признака и их количество в совокупности:
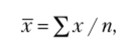
где — совокупность значений признака; п — количество признаков в совокупности.
В течение 10 лет компания финансировала бюджет отдела маркетинга. Ниже представлены данные о финансировании по годам (тыс. руб.).
Год… 1-й. | 2-й. | 3-й. | 4-й. | 5-й. | 6-й. | 7-й. | 8-й. | 9-й. | 10-й. |
Объем финансирования… 200. |
Средний размер финансирования будет составлять:
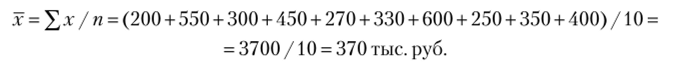
2. Взвешенная средняя арифметическая применяется, когда расчет средней производится по сгруппированным данным или вариационным рядам, в которых варианты могут повторяться не один раз:
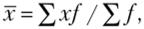
где / — частота появления признака.
Пример 5.10.
Расчет среднего размера финансирования в отдел маркетинга по годам на основе ряда распределения представлен в табл. 5.16.
Таблица 5.16
Расчет среднего размера финансирования.
Группы по размеру по финансированию, тыс. руб. | Число лет, /. | Середина интервала, .г. | xf |
200−300. | |||
300−400. | |||
400−500. | |||
500−600. | |||
Итого. | ; |
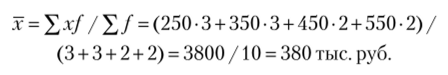
Данный результат отличается от результата, рассчитанного с помощью простой средней арифметической, поскольку произведенный расчет базируется на сведениях о середине интервала, а не на индивидуальных данных.[1][2]
произведения xf одинаковы или равны единице (М= 1), применяется средняя гармоническая простая, рассчитываемая по формуле 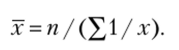
Пример 5.11.
Цена 1 шт. товара, продаваемого в первом магазине, составляет 35 руб., во втором — 36 руб., в третьем — 32 руб. Какая будет средняя цена товара, если выручка от продажи молока в магазинах одинакова?
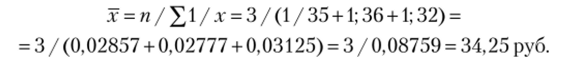
Примечание При применении простой средней арифметической, что, на первый взгляд, кажется более разумным, средняя цена составит: (35 + 36 + 32) / 3) = 34,33 руб. Можно проверить обоснованность данного расчета следующим образом. Допустим, в течение одного дня выручка от продажи товара составит 33 тыс. руб. (для доказательства сумма не имеет значения). Тогда первый магазин должен продать: 33 000 / 35 = 942,86 шт. товара, второй — 916,67 шт. товара, а третий — 1031,25 шт. товара, что в сумме составит 2890,78 шт. товара. Если заменить индивидуальные значения признака их рассчитанным с помощью простой средней арифметической средним значением, то общее количество проданной продукции сократится до 2883,78 шт. товара. Следовательно, полученная средняя рассчитана неверно.
При замене индивидуального значения признака их средней величиной, рассчитанной с помощью простой средней гармонической, общий объем приобретенного молока практически не изменился и составил 2890,5 шт. товара (33 000 / 34,25 + + 33 000 / 34,25 + 33 000 / 34,25).
2. Взвешенная гармоническая средняя — применяется, когда неизвестны действительные веса /, а известно произведение xf = М: 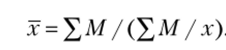
Пример 5.12.
Имеются следующие данные о продажах в двух филиалах компании (тыс. руб.):
• средние продажи каждого отдела в филиале (.г): филиал 1 — 1544; филиал 2 — 1276;
• общие продажи филиала (М): филиал 1 — 12 450; филиал 2 — 24 570. Требуется рассчитать средние продажи по двум филиалам компании в целом. Решение 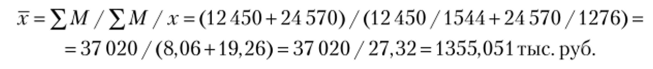
Особый вид средних величин — структурные средние — применяется для изучения внутреннего строения рядов распределения значений признака, а также для оценки средней величины, если по имеющимся статистическим данным ее расчет не может быть выполнен. Их величины зависят от характера частот, т. е. от структуры распределения, и не зависят от крайних значений. К структурным средним относятся мода и медиана.
Мода (М0) — это наиболее часто повторяющееся значение признака, которое рассчитывается по формуле.
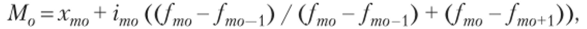
где хто — нижняя граница модального интервала; imo — величина модального интервала; fmo — частота модального интервала; fmo. — частота интервала, предшествующего модальному; /ото+1 — частота интервала, следующего за модальным.
Медиана (Ме) — эго величина признака, которая делит упорядоченную последовательность его значений на две равные по численности части и рассчитывается по формуле.
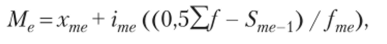
где хте — нижняя граница медианного интервала; ime — величина медианного интервала;/Ш? — частота медианного интервала; Sme_{ — сумма накопленных частот, предшествующих медианному.
Пример 5.13.
Компания производит электрооборудование. Нужно произвести расчет средней цепы проданного оборудования, моды и медианы, если известны следующие данные (табл. 5.17).
Таблица 5.17
Ряд распределения оборудования по возрастной группе.
Группы проданного оборудования в зависимости от цены, тыс. руб. | Количество проданных единиц. |
0−4. | |
4−8. | |
8−12. | |
12−16. | |
16−20. | |
Итого. |
Решение представлено в табл. 5.18.
Распределение проданного оборудования в зависимости от количества выполняемых функций.
Таблица 5.18
Группы оборудования по цене, тыс. руб. | Количество проданных единиц оборудования. | Середина интервала. | х/ | Накопленные частоты. |
0−4. | ||||
|
Группы оборудования, но цене, тыс. руб. | Количество проданных единиц оборудования. | Середина интервала. | X/ | Накопленные частоты. |
8−12. | ||||
12−16. | ||||
16−20. | ||||
Итого. | —. | —. |
Расчет среднего количества функций оборудования производится с использованием взвешенной арифметической средней, поскольку известна частота появления признака.
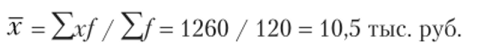
Рассчитываем моду:
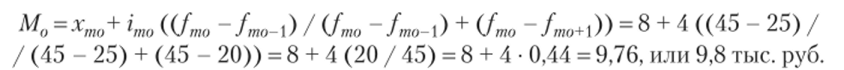
Рассчитываем медиану:
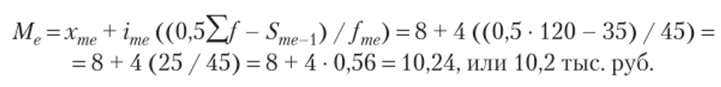
Итак, средняя цена проданного оборудования составляет 10,5 тыс. руб.; наиболее часто встречающийся ценой продаваемого оборудования является 9,8 тыс. руб.; половина оборудования продается по цене меньше 10,2 тыс. руб., а половина — больше данной цены.
Для того чтобы судить о надежности (типичности) средней величины, используют показатели вариации. Вариацией называют отличие численных значений единиц совокупности и их колебание около средней величины. В случае незначительной вариации наблюдается достаточно однородная совокупность, а значит, можно судить о надежности и типичности средней величины.
Основными показателями вариации являются следующие.
1. Размах вариации — разность между максимальным и минимальным значениями признака в изучаемой совокупности:
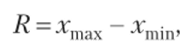
где лгтах и хтт — максимальное и минимальное значение признака соответственно.
Размах вариации учитывает только крайние значения признака и не учитывает промежуточные значения между ними.
- 2. Среднее линейное отклонение — это средняя арифметическая из абсолютных значений всех отклонений индивидуальных значений признака от среднего значения признака. Поскольку при его расчете не учитываются знаки отклонений, данный показатель используется редко:
- — взвешенное линейное отклонение:
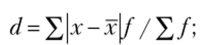
— простое линейное отклонение:
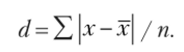
- 3. Дисперсия — это один из наиболее распространенных показателей вариации, представляющий собой среднюю из квадратов отклонений вариантов значений признака от их средней величины. Данный показатель бывает двух видов:
- — взвешенная дисперсия:
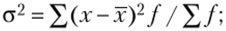
— простая дисперсия:
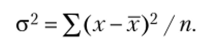
Дисперсия не имеет единиц измерения.
- 4. Среднее квадратическое отклонение представляет собой корень квадратный из дисперсии и показывает, на сколько в среднем отклоняются индивидуальные значения признака от их среднего значения и имеет единицы измерения. Так же как и дисперсия, бывает двух видов:
- — взвешенное квадратическое отклонение:
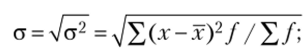
— простое квадратическое отклонение:
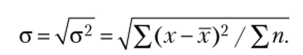
Дисперсия и среднее квадратическое отклонение недостаточно полно характеризуют колеблемость признака, поскольку характеризуют абсолютный размер отклонений, что затрудняет сравнение изменчивости различных признаков.
5. Коэффициент вариации используют для характеристики колеблемости явлений, т. е. он позволяет сравнить степень вариации признака. Рассчитывается коэффициент с помощью сопоставления среднего квадратического отклонения с его средней величиной и выражается в процентах:
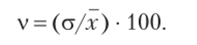
В случае если величина коэффициента вариации не превышает 33—35%, можно судить о надежности и типичности рассчитанной средней величины, а значит, и об однородности совокупности. Если же коэффициент вариации больше 33—35%, значит, исследуемая совокупность неоднородна, а средняя величина не типична.
Пример 5.14.
Воспользуемся условиями и решением предыдущей задачи и рассчитаем показатели вариации оборудования (табл. 5.19).
Таблица 5.19
Расчет показателей вариации оборудования, сгруппированного по цене.
Группа оборудования по цене, тыс. руб. | Количество единиц оборудования,/. | Середина интервала,. X | х{ | х — X | (х — х)[3]/ | |
| — 8,5. | 72,25. | 722,5. | |||
| — 4,5. | 20,25. | 506,25. | |||
8−12. | — 0,5. | 0,25. | 11,25. | |||
12−16. | 3,5. | 12,25. | ||||
16−20. | 7,5. | 56,25. | ||||
Итого. | ; | ; | ; |
Расчет средней цены оборудования производится с использованием взвешенной арифметической средней, поскольку известна частота появления признака:
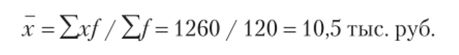
Рассчитаем показатели вариации: 1) размах вариации:
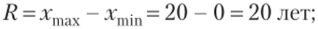
велика, средняя цена оборудования не является типичной, а саму совокупность сложно назвать однородной, но цене.
Важно запомнить!
В маркетинговых исследованиях практически всегда применяется выборочное наблюдение. Это способ несплошного наблюдения, при котором исследуется не вся совокупность, а только ее часть, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
Выборочное наблюдение необходимо тогда, когда нецелесообразно проводить сплошное обследование, как в масштабах страны (например, проведение социологического опроса всех жителей города по определенному вопросу), так и на предприятии (например, при обследовании всех буханок хлеба, произведенных предприятием). Использование выборочного наблюдения предоставляет возможность сэкономить на финансовых, материальных и трудовых ресурсах и без потери репрезентативности провести исследование в короткие сроки.
А значит, выборочная совокупность (п) представляет и характеризует генеральную совокупность (jV), т. е. отдельная часть изучаемых единиц характеризует все единицы изучаемого явления или процесса.
Для того чтобы говорить об объективности полученных результатов, следует придерживаться следующих правил:
- 1) выборка должна носить случайный характер, т. е. каждая единица совокупности должна иметь равные возможности попасть в выборку;
- 2) выборка должна происходить из однородной совокупности, поскольку в случае обследования неоднородной совокупности говорить об его объективности можно будет, лишь основываясь на результатах сплошного обследования.
Выборочное наблюдение, основываясь на перечисленных выше правилах, базируется на двух подходах.
- 1. Отбор по жеребьевке используют, когда единицы генеральной совокупности являются предварительно пронумерованными. При этом выборка может быть:
- а) повторной — когда отобранная единица фиксируется и снова возвращается в генеральную совокупность, после чего номера единиц совокупности перемешиваются, и снова проводится выборка;
- б) бесповторной — когда отобранная единица фиксируется и не возвращается в генеральную совокупность, а откладывается, после чего продолжается дальнейший процесс выборки.
- 2. Отбор по таблице случайных чисел используют, когда каждая единица генеральной совокупности имеет порядковый номер. Таблица случайных чисел, составленная с помощью ЭВМ, представляет собой произвольные столбцы цифр, и в соответствии с объемом генеральной совокупности произвольно выбирается колонка с числами необходимой значимости. Затем в выборочную совокупность отбираются единицы с порядковыми номерами, соответствующими номеру выбранной колонки.
Объективность и достоверность данных выборочного наблюдения зависят от способа отбора единиц из генеральной совокупности. Способ отбора характеризует процедуру (механизм) проведения выборочного наблюдения.
Выделяют следующие основные способы отбора.
1. Случайный отбор — наиболее распространенный способ отбора в случайной выборке, т. е. отбор единиц из генеральной совокупности проходит наугад; это так называемый метод жеребьевки, при котором на каждую единицу совокупности заготавливается жетон или билет с порядковым номером. Затем в случайном порядке отбирается необходимое количество единиц совокупности. При этих условиях каждая из них имеет одинаковую вероятность попасть в выборку. Случайный отбор может быть как повторным, так и бесповторным.
Условия его применения:
- а) все единицы совокупности должны иметь равные шансы попасть в выборку;
- б) должны быть установлены четкие границы генеральной совокупности, чтобы включение и невключение отдельных единиц совокупности не подвергалось сомнению; например, при обследовании промышленных предприятий необходимо определиться, будет ли генеральная совокупность включать малые предприятия, все ли виды деятельности будут охвачены и т. д.;
- в) каждая единица совокупности должна содержать в случае жеребьевки определенную информацию (ФИО, адрес и т. д.), а при применении таблицы случайных чисел — порядковый номер.
- 2. Механический отбор — когда всю совокупность разбивают на равные по объему группы по случайному признаку. Из каждой группы, как правило, берется одна единица. Все единицы изучаемой совокупности предварительно располагаются в определенном порядке, например по алфавиту, а затем через определенный интервал отбирается необходимое количество единиц, например каждая пятая, десятая и т. д. Механический способ осуществляется только бесповторным способом.
Условия его применения:
- а) генеральная совокупность должна быть упорядочена определенным образом;
- б) отбор должен осуществляться в соответствии с установленной пропорцией через равные интервалы;
- в) отбор целесообразно начинать с середины первого интервала;
- г) во избежание случайного совпадения выбранного интервала в каждом новом объекте отбора следует менять начало отбора.
- 3. Типический отбор — когда совокупность разбивают по существенному (типическому) признаку на качественно однородные группы. Затем из каждой группы в случайном порядке отбирается определенное количество единиц, как правило, пропорциональное удельному весу группы во всей совокупности.
Типический отбор дает более высокую репрезентативность, однако характеризуется, как это видно выше, особой организацией.
Условия его применения:
- а) генеральную совокупность можно разбить на несколько типических групп, например однокомнатные квартиры, двухкомнатные квартиры и т. д.;
- б) выборка единиц из типической группы может происходить собственно случайным или механическим способом;
- в) отбор единиц может быть организован или пропорционально удельном}? весу группы во всей совокупности, или пропорционально внутригрупповой дифференциации признака.
- 4. Серийный отбор — когда из генеральной совокупности отбору подлежат не отдельные единицы, а целые группы (серии, гнезда), отобранные случайным или механическим способом, например контроль успеваемости в студенческих группах. В каждой серии проводится сплошное наблюдение, а результаты переносятся на всю совокупность. Данный тип отбора может быть как повторным, так и бесповторным.
Условия его применения:
- а) единицы совокупности должны быть объединены в небольшие серии или группы;
- б) внутри серии или группы должны обследоваться все единицы совокупности.
Ошибка выборки — это некоторое расхождение характеристик генеральной совокупности от характеристик, полученных на основе выборочного наблюдения.
При осуществлении выборочного наблюдения исчисляют средние (р) и предельные (Д) ошибки выборки. Предельная ошибка выборки тесно связана со средней ошибкой равенством.
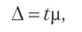
где t — коэффициент доверия (кратность ошибки выборки), который по таблице значений интегральной функции Лапласа при заданной вероятности (Р) имеет определенные значения (табл. 5.20).
Таблица 5.20
Основные значения параметров.
Заданная вероятность (Р). | Коэффициент доверия (Г). |
0,683. | |
0,950. | 1,96. |
0,954. | |
0,997. |
Рассмотрим расчет ошибки выборки для каждого способа отбора по отдельности.
1. Для собственно случайного повторного отбора предельная ошибка для средней (Д х) определяется по следующей формуле:
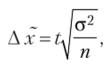
где Дх — предельная ошибка для средней; t — коэффициент доверия при заданной вероятности; а2 — дисперсия количественно варьирующего признака выборочной совокупности; п — численность единиц выборочной совокупности.
Предельная ошибка для доли (Ак,):
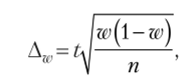
где Д", — предельная ошибка для доли; w (1 — w) — дисперсия альтернативного признака.
Пример 5.15.
Рассмотрим расчет предельной ошибки для средней и для доли на следующем примере.
Для определения мнения потребителей о дизайне упаковки в порядке случайной повторной выборки было обследовано 100 потребителей. В результате установлено, что средняя оценка составила 3,7 балла при среднеквадратическом отклонении в 0,8 балла. Также стало известно, что 20 потребителей предпочитают другой вид упаковки. С вероятностью 0,683 определите пределы, в которых будет находиться средний балл оценки упаковки, и долю потребителей, предпочитающих другой вид упаковки (в отдельном пакете).
Решение
Рассчитываем предельную ошибку для средней:
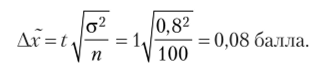
Рассчитаем предельную ошибку для доли:
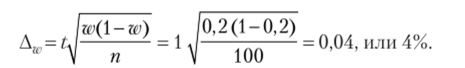
При этом.
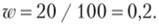
Ответ.
- 1. С вероятностью 0,683 можно утверждать, что средняя оценка дизайна упаковки потребителями будет колебаться в пределах от (3,7 — 0,08) до (3,7 + 0,08), т. е. от 3,62 до 3,78 балла.
- 2. С вероятностью 0,683 можно утверждать, что доля потребителей, предпочитающих иной вид упаковки, будет колебаться в пределах от (20% - 4%) до (20% + + 4%), т. е. от 16 до 24%.
Для бесповторного собственно случайного и механического отбора предельная ошибка для средней (Лх) определяется по следующей формуле:
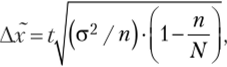
где N — численность единиц генеральной совокупности.
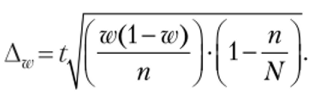
Пример 5.16.
Рассмотрим расчет предельной ошибки для средней и для доли.
Для определения лояльности потребителей из базы данных компании была проведена 20%-ная механическая выборка, в которую попало 150 человек. В результате обследования было установлено, что средний стаж потребления продукта составляет восемь лет при срсднсквадратичсском отклонении два года. У 35 человек средний стаж потребления продукта превышал 10 лет. Нужно с вероятностью 0,954 определить пределы, в которых будет находиться средний стаж лояльности потребителей в генеральной совокупности, и долю потребителей, имеющих стаж потребления более 10 лет.
Решение
Рассчитываем предельную ошибку для средней:
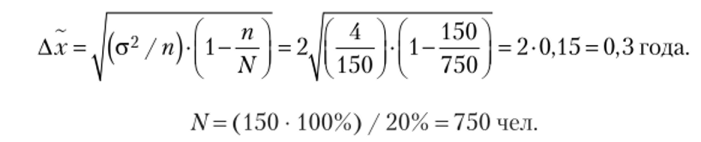
Рассчитаем предельную ошибку для доли:

Ответ.
- 1. С вероятностью 0,954 можно утверждать, что средний стаж потребления клиентов компании будет колебаться в пределах от (8 — 0,3) до (8 + 0,3), т. е. от 7,7 до 8,3 года.
- 2. С вероятностью 0,954 можно утверждать, что доля потребителей, чей стаж более 10 лет, будет колебаться в пределах от (23,33% — 6,2%) до (23,33% + 6,2%), т. е. от 17,13% до 29,53%.
- 3. Для типического отбора предельная ошибка для средней (Аг) определяется по следующей формуле:
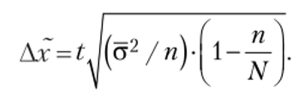
При этом.
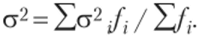
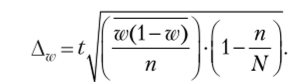
При этом.
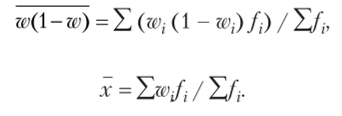
Пример 5.17.
Рассмотрим расчет предельной ошибки для средней и для доли на следующем примере.
В результате 10%-ного типического отбора потребителей были получены следующие исходные данные (табл. 5.21).
Таблица 5.21
Средние расходы времени на обработку одной покупки в офисе компании.
Регион. | Средние расходы времени на совершение одной покупки в офисе компании, мин. | Количество потребителей, участвующих в выборке, чел. | Среднеквадратичсскос отклонение, мин. | Удельный вес потребителей моложе 25 лет, %. |
Москва. | ||||
Санкт; Петербург. | ||||
Владивосток. | ||||
Сочи. | ||||
Итого. | ; | ; | ; |
11ужно с вероятностью 0,954 определить пределы колебания среднего времени оформления покупки товаров в офисе компании и пределы колебания доли потребителей моложе 25 лет.
Решение
1. Определим средние расходы времени на приобретение товара в офисах компании по всем регионам:
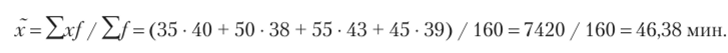
2. Вычислим среднюю из групповых дисперсий:
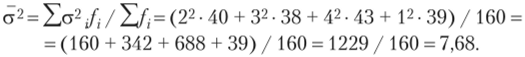
3. Определим предельную ошибку выборки для средней по формуле 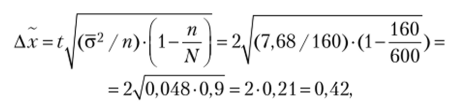 где N= (160 • 100%) / 10% = 1600 чел.
где N= (160 • 100%) / 10% = 1600 чел.
4. Вычислим долю потребителей младше 25 лет в общей численности потребителей по формуле.
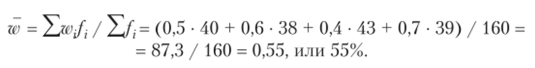
5. Рассчитаем выборочную дисперсию альтернативного признака по формуле.
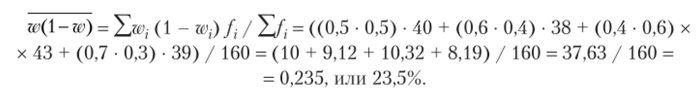
6. Ошибку для доли определим по формуле.
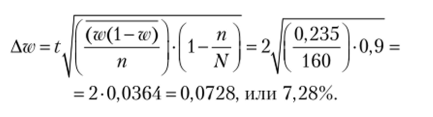
Ответ.
- 1. С вероятностью 0,954 можно утверждать, что средние расходы времени на оформление одной покупки будут колебаться в пределах от (46,38 — 0,42) до (46,38 + 0,42), т. е. от 45,96 до 46,8 мин.
- 2. С вероятностью 0,954 можно утверждать, что доля покупателей младше 25 лет будет колебаться в пределах от (55% - 7,28%) до (55% + 7,28%), т. е. от 47,72 до 62,28%.
- 4. Для серийной выборки предельная ошибка для средней (Ат) определяется по следующей формуле:
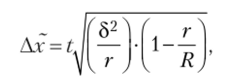
где 82 — межсерийная дисперсия; г — число отобранных серий; R — число серий в генеральной совокупности.
При этом межсерийная дисперсия рассчитывается по следующей формуле:
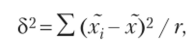
где Xj — выборочная средняя каждой серии; х — выборочная средняя серийной выборки.
Рассмотрим расчет предельной ошибки для средней.
Компания имеет 50 отделений. С целью изучения возврата товаров была проведена 10%-ная серийная выборка, в которую попали пять отделений компании. В результате обследования установлено, что возврат товаров в отделениях компании составил: 5, 7, 8, 3, 6 шт. С вероятностью 0,954 определите пределы, в которых будет находиться среднее количество возврата товара.
Решение
1. Определим выборочную среднюю серийной выборки:
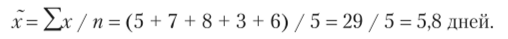
2. Определим дисперсию серийной выборки, но формуле.
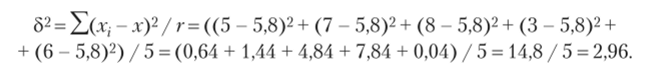
3. Рассчитаем предельную ошибку для средней:
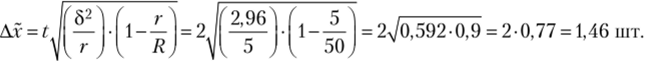
Ответ.
С вероятностью 0,954 можно утверждать, что среднее количество возвращенного товара будет находиться в пределах с (5,8 — 1,46) до (5,8 + 1,46), т. е. от 4,34 до 7,26 шт.
Довольно часто в практике важно правильно определить численность (объем) выборочной совокупности, которая с определенной вероятностью обеспечит заданную точность и объективность результатов наблюдения. Формулы для определения необходимой численности выборки находятся путем преобразования формул ошибок выборки, при этом должны быть известны предельная ошибка выборки, вероятность ее появления и вариация признака.
Объемы выборок, используемых в маркетинговых исследованиях, представлены в табл. 5.22.
Минимальная численность респондентов, необходимая для репрезентативности выборки1
Таблица 5.22
Вид исследования. | Мини мальный объем. | Обычный диапазон. |
Исследование, цель которого — определить проблему (например, изучение потенциала рынка). | 1000−2500. | |
Исследование, цель которого — решить проблему (например, определить цену). | 300−500. | |
Тестирование товара. | 300−500. |
1 Малхотра II. К. Указ. соч.
Вид исследования. | Мини мальный объем. | Обычный диапазон. |
Пробный маркетинг. | 300−500. | |
Теле-, радиои печатная реклама (в расчете на одно рекламное объявление, эффективность которого исследуется). | 200−300. | |
Аудит на пробном рынке. | 10 магазинов. | 10—20 магазинов. |
Фокус-группы. | шесть групп. |
|
Рассмотрим формулы нахождения численности выборки по видам отбора.
1. Для собственно случайного повторного отбора численность выборки для средней количественного признака определяется по следующей формуле:
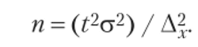
А для доли (альтернативного признака).
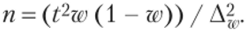
Пример 5.19.
Рассмотрим расчет нахождения численности для средней количественного признака и для доли.
Определите в случае случайного повторного отбора необходимую численность опрашиваемых при условии, что ошибка выборочной средней не должна превышать 0,05 семьи с вероятностью 0,683 и среднем квадратическом отклонении 1,5 семьи. А также определите, какой должна быть численность отбора семей с двумя детьми с вероятностью 0,954, чтобы ошибка выборки не превышала 0,03 семьи, если на основе предыдущего отбора было выявлено, что 47% семей имеют двоих детей.
Решение
1. Определяем численность выборки для средней количественного признака, но следующей формуле:[7]
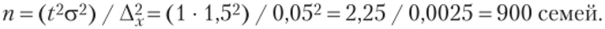
2. Для бесновторного собственно случайного и механического отбора численность выборки для средней количественного признака определяется по следующей формуле:
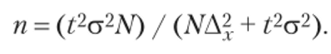
А для доли (альтернативного признака) 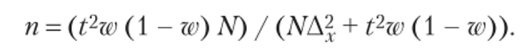
Пример 5.20.
Рассмотрим расчет нахождения численности для средней количественного признака и для доли.
В районе города проживает 4000 семей. Нужно определить методом случайного бссповторного отбора необходимую численность опрашиваемых при условии, что ошибка выборочной средней не должна превышать 0,35 семьи с вероятностью 0,954 и среднем квадратическом отклонении две семьи, а также определить, какой должна быть численность отбора семей с одним ребенком с вероятностью 0,950, чтобы ошибка выборки не превышала 0,4 семьи, если на основе предыдущего отбора было выявлено, что 55% семей имеют одного ребенка.
Решение
1. Определяем численность выборки для средней количественного признака, но следующей формуле:
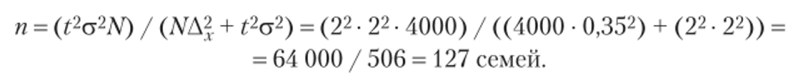
2. Определяем численность выборки для доли по следующей формуле:

Ответ.
Численность отбора при условии, что ошибка выборочной средней не должна превышать 0,35 семьи с вероятностью 0,954, должна составлять 127 семей, а численность отбора семей с одним ребенком с вероятностью 0,950, чтобы ошибка выборки не превышала 0,4 семьи, должна составлять б семей.
3. Для типического отбора численность выборки для средней количественного признака определяется по следующей формуле:
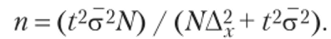
А для доли (альтернативного признака).
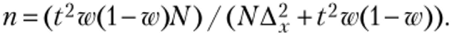
Пример 5.21.
Рассмотрим расчет нахождения численности для средней количественного признака на следующем примере.
Для выявления размера количества семей городов была осуществлена 10%-ная типическая выборка, результаты обследования представлены в табл. 5.23.
Таблица 5.23
Данные 10%-ной выборки.
Номер города. | Количество семей. | Среднее квадратическое отклонение. |
2,2. | ||
3,4. | ||
2,8. |
Определите необходимый объем выборки при определении среднего размера количества семей, чтобы с вероятностью 0,954 предельная ошибка выборки была не более 0,9 семьи.
Решение
1. Вычислим среднюю из групповых дисперсий:
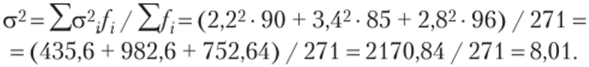
2. Определяем численность выборки для средней количественного признака по следующей формуле: 
Ответ
Необходимый объем выборки при определении среднего размера количества семей, чтобы с вероятностью 0,954 предельная ошибка выборки была не более 0,9 семьи, должен составлять 39 семей.
4. Для серийного отбора численность выборки для средней количественного признака определяется по следующей формуле: 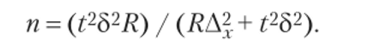
Пример 5.22.
Рассмотрим расчет нахождения численности для средней количественного признака.
Банк имеет 50 отделений. С целью изучения возврата потребительских кредитов с помощью серийной выборки нужно определить необходимую численность обследования отделений банка, с вероятностью 0,954, если межсерийная дисперсия составляет 3,2, а предельная ошибка выборки — 1,5 дня. 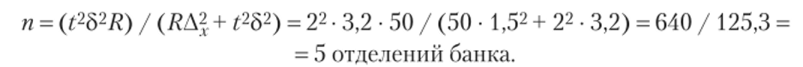
Корреляционный анализ количественно определяет тесноту связи между признаками (при парной связи) и между результативным и множеством факторных признаков (при многофакторной связи). Теснота связи количественно выражается величиной коэффициента корреляции.
Корреляционно-регрессионный анализ включает в себя измерение тесноты и направления связи, а также установление аналитического выражения (формы) связи. Наиболее часто используемой является линейная форма связи.
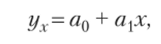
где ух — результативный признак, х — факторный признак, а^ал — параметры уравнения.
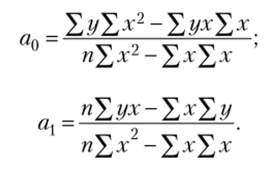
Параметр ах называется коэффициентом регрессии и показывает изменение результативного признака при изменении факторного признака на единицу. Параметр а0 не имеет экономического содержания. Если а > О, то относительное изменение результата происходит медленнее, чем изменение фактора.
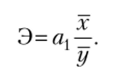
Часто исследуемые признаки имеют разные единицы измерения, поэтому для оценки влияния факторного признака на результативный показатель применяется линейный коэффициент корреляции г.
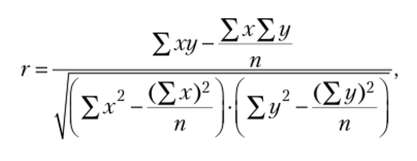
где п — число взаимосвязанных пар показателей.
Линейный коэффициент корреляции может принимать любые значения от -1 до +1. Чем ближе модуль значения коэффициента к 1, тем теснее взаимосвязь между признаками. Знак «+» означает прямую зависимость, а знак «-» — обратную зависимость.
Количественные критерии оценки тесноты связи представлены в табл. 5.24.
Критерии оценки тесноты связи.
Таблица 5.24
Величина коэффициента корреляции г | 0,1 -0,3. | 0,3−0,5. | 0,5−0,7. | 0,7−0,9. | 0,9−1,0. |
Характеристика силы связи. | Слабая. | Умеренная. | Заметная. | Высокая. | Весьма высокая. |
Коэффициент детерминации — это квадрат коэффициента корреляции г2;
Пример 5.23.
Рассмотрим применение корреляционно-регрессионного анализа на условном примере (табл. 5.25).
Таблица 5.25
Исходные данные.
Возраст, год (х). | Потребление футболок на одного человека в год (у) |
0−6. | |
6−18. | |
18−24. | |
24−34. | |
34−54. | |
54−64. | |
Итого. |
Нужно проанализировать зависимость потребления обуви от возраста потребителей, используя корреляционно-регрессионный анализ, и сделать вывод.
Решение представлено в табл. 5.26.
Таблица 5.26
Решение.
Возраст. | У | X | ух | X2 | У2 |
0−6. | |||||
6−18. | |||||
18−24. | |||||
24−34. | |||||
34−54. | |||||
54−64. | |||||
Итого. | |||||
В среднем. | 9,33 — 9. | ; | ; | ; |

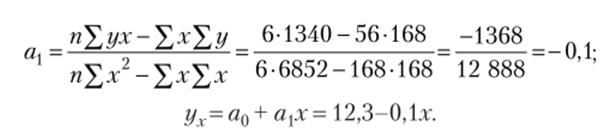
С увеличением возраста на один год потребление футболок снижается на 0,1 шт. Коэффициент эластичности показывает, что с увеличением возраста на 1% потребление футболок уменьшается на 0,31%.
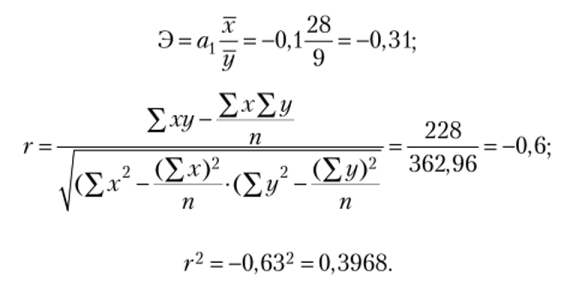
Величина коэффициента корреляции -0,63 свидетельствует о заметной связи между возрастом и потреблением, которая является обратной. При этом 39,68% отклонений потребления на одного покупателя могут быть объяснены возрастом. Остальные 60,32% причин отклонений должны быть приписаны влиянию других факторов.
В конце проведения маркетинговых исследований исследовательские компании часто определяют тенденцию развития изучаемого социальноэкономического явления, т. е. определяют тренд. Тренд — это долговременная тенденция развития, которая дает представление об основной линии развития, исключая остальные компоненты. Для того чтобы устранить влияние случайных обстоятельств, используют следующие основные способы обработки рядов динамики.
1. Метод укрепления временных интервалов предполагает замену первоначального ряда динамики другим, уровни которого являются большими по продолжительности, например, месячные интервалы заменяют на квартальные и т. д. Так, используя данные предыдущей задачи и продолжая ее, можно привести наглядную демонстрацию этого метода.
Пример 5.24
Имеются следующие данные о количестве покупателей (условные): январь — 789 чел., февраль — 793, март — 798, апрель — 795, май — 810, июнь — 809, июль — 802, август — 805, сентябрь — 812, октябрь — 819, ноябрь — 821, декабрь — 825 чел. Нужно осуществить укрепление временных интервалов.
Решение
Переводим месячные уровни в квартальные:
I квартал = 2380 чел. (789 + 793 + 798).
II квартал = 2414 чел.
III квартал = 2419 чел.
IV квартал = 2465 чел.
Ответ
После увеличения интервалов основная тенденция увеличения покупателей в компании становится явной, поскольку 2380 < 2414 < 2419 < 2465.
2. Метод скользящих средних представляет собой расчет среднего уровня из определенного числа первых по порядку уровней ряда, затем — средний уровень из такого же числа уровней, начиная со второго и т. д.
Пример 5.25.
В табл. 5.27 приведен пример расчета (данные предыдущей задачи).
Таблица 5.27
Метод скользящих средних.
Месяц. | Количество потребителей, чел. | Расчет скользящей средней. | Скользящая средняя по вкладам, чел. |
Январь. | ; | ; | |
Февраль. | (789 + 793 + 798) / 3. | 793,33. | |
Март. | (793 + 798 + 795) / 3. | 795,33. | |
Апрель. | (798 + 795 +810)/3. | 801,00. | |
Май. | (795 + 810 + 809) / 3. | 804,67. | |
Июнь. | (810 + 809 + 802) / 3. | 807,00. | |
Июль. | (809 + 802 + 805) / 3. | 805,33. | |
Август. | (802 + 805 +812)/3. | 806,33. | |
Сентябрь. | (805 + 812 +819)/3. | 812,00. | |
Октябрь. | (812+ 819 +821)/3. | 817,33. | |
Ноябрь. | (819 + 821 +825)/3. | 821,67. | |
Декабрь. | ; |
Ответ
Несмотря на некоторое снижение в середине года, количество потребителей в компании имеет явную тенденцию к росту.
3. Метод аналитического выравнивания представляет собой замену фактических уровней плавными уровнями, рассчитанными на основе определенного тренда, отражающего общую тенденцию явления. Отклонение конкретных уровней ряда от уровней, соответствующих общей тенденции, объясняют действием факторов, проявляющихся случайно или циклически. В результате приходят к следующей трендовой модели:
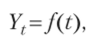
где f (t) — уровень, определяемый тенденцией развития. При этом на практике применяют следующие виды математических функций: а) линейная функция выравнивает динамические ряды по уравнению прямой линии и применяется тогда, когда ценные абсолютные приросты более-менее постоянны (арифметическая прогрессия). При этом она имеет следующий вид:
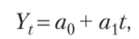
где я0 и ах — параметры, которые находятся методом наименьших квадратов; t — порядковый номер периода.
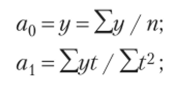
б) параболическая функция представляет собой динамические ряды по уравнению квадратической параболы и применяется, когда абсолютные цепные приросты сами по себе обнаруживают некоторую тенденцию развития, но абсолютные цепные приросты абсолютных цепных приростов (разности второго порядка) никакой тенденции развития не проявляют, или изменение уровней ряда происходит с равномерным ускорением (замедлением) цепных абсолютных приростов. При этом она имеет следующий вид:
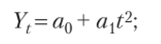
в) степенная функция представляет собой динамические ряды по уравнению степенной функции и применяется тогда, когда уровни ряда динамики проявляют тенденцию постоянства цепных темпов роста (геометрическая прогрессия). При этом она имеет следующий вид: 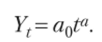
Пример 5.26.
Приведем пример наиболее часто применяемого из основных методов аналитического выравнивания — использование линейной функции. Используем данные задачи, представленной в примере 5.25.
Имеются следующие данные о количестве потребителей в компании (данные условные): январь — 789 чел., февраль — 793, март — 798, апрель — 795, май — 810 чел. Требуется рассчитать параметры линейного тренда.
Данное задание можно выполнить с помощью табл. 5.28.
Таблица 5.28
Расчет параметров линейного тренда количества потребителей в компании.
Месяц. | t | У | Y, | о- | Ух |
Январь. | — 2. | — 1578. | 788,2. | ||
Февраль. | — 1. | — 793. | 792,6. | ||
Март. | 797,0. | ||||
Апрель. | 801,4. | ||||
Май. | 805,8. | ||||
Итого. |
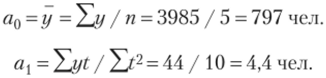
Тренд примет вид.
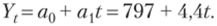
Ответ.
Итак, придавая конкретные значения t, получаем выровненные значения количества потребителей в компании. Значение ал дает представление о том, что от месяца к месяцу количество потребителей возрастает на 4,4 потребителя, а значит, можно наблюдать устойчивую тенденцию к росту. Благодаря тренду можно найти прогноз покупателей компании на июнь: 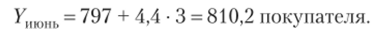
- [1] Средняя гармоническая величина подразделяется на следующие виды.
- [2] Простая гармоническая средняя — применяется, когда частоты /неизвестны, а известны только индивидуальные значения признака хи произведения х/. Обозначим произведение х/ как М. В тех случаях, когда
- [3] дисперсия:
- [4] среднее квадратическое отклонение:
- [5] коэффициент вариации: Анализ рассчитанных данных показывает, что цена продаваемогооборудования отличается от средней цены (10,5 тыс. руб.) в среднемна 4,66 тыс. руб., или на 44,38%. Поскольку коэффициент вариации больше33—35%, значит, исследуемая вариация цены продаваемого оборудования
- [6] дисперсия:
- [7] Определяем численность выборки для доли по следующей формуле: Ответ Численность отбора при условии, что ошибка выборочной средней не должнапревышать 0,05 семьи с вероятностью 0,683 и среднем квадратическом отклонении1,5 семьи, должна составлять 900 семей, а численность отбора семей с двумя детьмис вероятностью 0,954, чтобы ошибка выборки не превышала 0,03 семьи, должнасоставлять 1107 семей.