MS SQL Server и MS SQL Server Management Studio 2012

Microsoft SQL Server — система управления реляционными базами данных (СУБД), разработанная корпорацией Microsoft. Основной используемый язык запросов — Transact-SQL, создан совместно Microsoft и Sybase. Transact-SQL является реализацией стандарта ANSI/ISO по структурированному языку запросов (SQL) с расширениями. Используется для работы с базами данных размером от персональных до крупных баз… Читать ещё >
MS SQL Server и MS SQL Server Management Studio 2012 (реферат, курсовая, диплом, контрольная)
База данных создается в MS SQL Server и MS SQL Server Management Studio 2012.
Microsoft SQL Server — система управления реляционными базами данных (СУБД), разработанная корпорацией Microsoft. Основной используемый язык запросов — Transact-SQL, создан совместно Microsoft и Sybase. Transact-SQL является реализацией стандарта ANSI/ISO по структурированному языку запросов (SQL) с расширениями. Используется для работы с базами данных размером от персональных до крупных баз данных масштаба предприятия; конкурирует с другими СУБД в этом сегменте рынка. SQL Server является довольно сложным продуктом, работу с которым можно рассматривать с разных сторон. В частности, можно выделить два основных раздела работы с сервером, каждый из которых при ближайшем рассмотрении может быть легко разделен на более мелкие блоки: О администрирование; О программирование.
Администрирование SQL Server в свою очередь можно разделить на две части: администрирование собственно сервера и администрирование баз данных. Таким образом, администрирование баз данных представляет собой отдельную область работы с SQL Server. Оно включает разработку структуры базы данных, ее реализацию, проектирование системы безопасности, создание пользователей базы данных, предоставление им прав доступа, создание объектов и т. д. Кроме того, администратор базы данных должен периодически создавать резервные копии, выполнять проверку целостности данных и следить за размером файлов как самой базы данных, так и журнала транзакций. Указанный список можно легко продолжить, так как мы перечислили далеко не все задачи администрирования.
Первая задача, которая встает перед администратором или разработчиком, это проектирование структуры базы данных. Неверно спроектированная база данных впоследствии доставит много хлопот как администратору, так и программистам и пользователям. Поэтому необходимо ответственно отнестись к разработке базы данных, сразу же продумывая различные варианты использования данных, а также возможности интеграции с дополнительными системами и доступа к данным с помощью различных технологий.
Существует множество технологий и методов разработки баз данных, рассмотрение которых достойно отдельной книги. Для более детального знакомства с теорией реляционных баз данных и построением баз данных с использованием ER-диаграмм необходимо обратиться к специализированной литературе, посвященной этим вопросам. Для понимания теории реляционных баз данных, которая является доминирующей в настоящее время, необходимо хорошее знание математики, так как в основе реляционной модели данных лежат математические объекты.
В широком смысле слова база данных — это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления и, в конечном счете, автоматизации. Примером может служить предприятие, вуз и т. д. Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро извлекать нужные сведения с произвольным сочетанием признаков. Сделать это можно, только если данные структурированы.
База данных — поименованная совокупность взаимосвязанных данных, находящихся под управлением системы управления базами данных (СУБД). СУБД — это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Основная задача базы данных — хранить и при необходимости представлять по первому требованию пользователей все необходимые данные в одном месте, исключая их повторение и избыточность.
Централизованный характер управления данными в базе данных предполагает существование некоторого лица (группы лиц), на которое возлагаются функции администрирования данных, хранимых в базе.
Различают централизованные и распределенные базы данных. О Распределенная база данных состоит из нескольких частей, хранимых в различных ЭВМ вычислительной сети. Этот способ обработки подразумевает наличие нескольких серверов, на которых может храниться пересекающаяся или даже дублирующаяся информация. Для работы с такой базой данных используется система управления распределенными базами данных (СУРБД).
Централизованная база данных хранится в памяти одной вычислительной системы, то есть база данных располагается на одном компьютере. Если для этого компьютера установлена поддержка сети, то множество пользователей с клиентских компьютеров могут одновременно обращаться к информации, хранящейся в центральной базе данных. В локальных сетях чаще всего используется именно такой способ обработки данных. Системы централизованных баз данных могут существенно различаться в зависимости от их архитектуры." Файл-сервер.
БД располагается на файл-сервере (или нескольких файл-серверах), в качестве которого может использоваться наиболее мощная из ПЭВМ, объединенных в сеть. Функции файл-сервера заключаются, в основном, в хранении БД и обеспечении доступа к ним пользователей, работающих на различных компьютерах.
Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. Переданные данные обрабатываются СУБД, которая находится опять же на компьютерах пользователей. После того как пользователи выполнят необходимые изменения данных, они копируют файлы обратно на файл-сервер, где другие пользователи, в свою очередь, могут снова их использовать.
Кроме того, каждый пользователь может создавать на локальном компьютере свои собственные базы данных, используемые им монопольно. Эта схема работает при не очень больших объемах данных. При увеличении числа компьютеров в сети или росте БД производительность резко падает. Это связано с увеличением объема данных, передаваемых по сети, так как вся обработка происходит на компьютере пользователя.
Явным недостатком подобного подхода является высокая вероятность потери изменений, выполненных одними пользователями, при сохранении измененных файлов на центральный сервер. Дело в том, что пользователи могут и не подозревать, что помимо них еще кто-то изменял данные. Примерами СУБД, предназначенными непосредственно для разработки локальных пользовательских приложений БД, то есть приложений, работающих на одном локальном компьютере либо в компьютерной, сети являются: Microsoft Visual FoxPro, Microsoft Access, Paradox, fpr Windows, dBase for Windows и др.
* Клиент-сервер. Технология клиент-сервер подразумевает, что помимо хранения базы данных центральный компьютер (сервер базы данных) должен обеспечивать выполнение основного объема обработки данных. При технологии клиент-сервер запрос на выполнение операции с данными (например, обычная выборка), выдаваемый клиентом (рабочей станцией), порождает на сервере поиск и извлечение данных. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту дж. Система, использующая технологию клиент-сервер, разделяется на две части: клиентская часть (front-end) обеспечивает графический интерфейс и находится на компьютере пользователя; серверная часть (back-end), которая находится на специально выделенных компьютерах, обеспечивает управление данными, разделение информации, администрирование и безопасность.
Примерами СУБД технологии клиент-сервер являются Microsoft SQL Server, Oracle, IBM DB2, Sybase и др. Спецификой архитектуры клиент-сервер является использование специального языка структурированных запросов (Structured Query Language, SQL), обеспечивающего пользователя простым и эффективным инструментом доступа к данным.
Помимо подразделения баз данных по методам обработки можно классифицировать их по используемой модели (или структуре) данных. Модель данных — совокупность структур данных и операций по их обработке. С помощью модели данных можно наглядно представить структуру объектов и установленные между ними связи. Для терминологии моделей данных характерны понятия «элемент данных» и «правила связывания». Элемент данных описывает любой набор данных, а правила связывания определяют алгоритмы взаимосвязи элементов данных. К настоящему времени разработано множество различных моделей данных, но на практике используется три основных. Выделяют иерархическую, сетевую и реляционную модели данных. Соответственно говорят об иерархических, сетевых и реляционных СУБД.
Иерархическая модель данных. Иерархически организованные данные встречаются в повседневной жизни очень часто. Например, структура высшего учебного заведения — это многоуровневая иерархическая структура. Иерархическая (древовидная) БД состоит из упорядоченного набора элементов. В этой модели исходные элементы порождают другие элементы, причем эти элементы в свою очередь порождают следующие элементы. Каждый порожденный элемент имеет только один порождающий элемент.
Организационные структуры, списки материалов, оглавление в книгах, планы проектов и многие другие совокупности данных могут быть представлены в иерархическом виде. Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Основным недостатком данной модели является необходимость использования той иерархии, которая была заложена в основу БД при проектировании. Потребность в постоянной реорганизации данных (а часто невозможность этой реорганизации) привели к созданию более общей модели — сетевой.
Сетевая модель данных. Сетевой подход к организации данных является расширением иерархического подхода. Данная модель отличается от иерархической тем, что каждый порожденный элемент может иметь более одного порождающего элемента.
Рассмотрим предметную область для базы данных, в которой хранится информация о заказах магазина. Заказчики берут напрокат фильмы, используя два носителя: видеоленту и компакт-диски. Обслуживание заказчиков выполняют продавцы. Каждый продавец обслуживает многих заказчиков. Каждый продавец может пользоваться услугами нескольких магазинов и наоборот. Существует много копий одного и того же фильма и т. д.
Поскольку сетевая БД может представлять непосредственно все виды связей, присущих данным соответствующей организации, по этим данным можно перемещаться, исследовать и запрашивать их всевозможными способами, то есть сетевая модель не связана всего лишь одной иерархией. Однако для того чтобы составить запрос к сетевой БД, необходимо достаточно глубоко вникнуть в ее структуру (иметь под рукой схему этой БД) и выработать механизм навигации по базе данных, что является существенным недостатком этой модели БД.
Реляционная модель данных. Основная идея реляционной модели данных заключается в том, чтобы представить любой набор данных в виде двумерной таблицы. В простейшем случае реляционная модель описывает единственную двумерную таблицу, но чаще всего эта модель описывает структуру и взаимоотношения между несколькими различными таблицами.
Итак, целью информационной системы является обработка данных об объектах реального мира, с учетом связей между объектами. В теории БД данные часто называют атрибутами, а объекты — сущностями. Объект, атрибут и связь — фундаментальные понятия ИС.
Объект (или сущность) — это нечто существующее и различимое, то есть объектом можно назвать то «нечто», для которого существуют название и способ отличать один подобный объект от другого. Например, каждая школа — это объект. Объектами являются также человек, класс в школе, фирма, сплав, химическое соединение и т. д. Объектами могут быть не только материальные предметы, но и более абстрактные понятия, отражающие реальный мир. Например, события, регионы, произведения искусства; книги (не как полиграфическая продукция, а как произведения), театральные постановки, кинофильмы; правовые нормы, философские теории и проч.
Атрибут (или данное) — это некоторый показатель, который характеризует некий объект и принимает для конкретного экземпляра объекта некоторое числовое, текстовое или иное значение. Информационная система оперирует наборами объектов, спроектированными применительно к данной предметной области, используя при этом конкретные значения атрибутов (данных) тех или иных объектах. Например, возьмем в качестве набора объектов классы в школе. Число учеников в классе — это данное, которое принимает числовое значение (у одного класса 28, у другого — 32). Название класса — это данное, принимающее текстовое значение (у одного — 10А, у другого — 9Б и т. д.).
Атрибут некоторого набора объектов сам может быть набором объектов, имеющих собственные атрибуты. Например, атрибутом лица (как экземпляра набора объектов «Лица») является вуз, который это лицо окончило (МГУ, МИФИ и т. п.). С другой стороны, конкретный вуз — это экземпляр набора объектов «Вузы» и характеризуется множеством данных: фамилией ректора, адресом, специализацией, числом студентов и т. д. Наконец, ректор в свою очередь является экземпляром набора объектов «Лица». Таким образом, возникает возможность установления связи между экземплярами объектов из разных наборов.
Развитие реляционных баз данных началось в конце 60-х годов, когда появились первые работы, в которых обсуждались возможности использования при проектировании баз данных привычных и естественных способов представления данных — так называемых табличных даталогических моделей.
Основоположником теории реляционных баз данных считается сотрудник фирмы IBM доктор Э. Кодд, опубликовавший 6 июня 1970 г. статью A Relational Model of Data for Large Shared Data Banks (Реляционная модель данных для больших коллективных банков данных). В этой статье впервые был использован термин «реляционная модель данных», что и положило начало реляционным базам данных.
Теория реляционных баз данных, разработанная в 70-х годах в США доктором Э. Коддом, имеет под собой мощную математическую Основу, описывающую правила эффективной организации данных. Разработанная Э. Коддом теоретическая база стала основой для разработки теории проектирования баз данных.
Э. Кодд, будучи математиком по образованию, предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он доказал, что любой набор данных можно представить в виде двумерных таблиц особого вида, известных в математике как «отношения».
Реляционной считается такая база данных, в которой все данные представлены для пользователя в виде прямоугольных таблиц значений данных, и все операции над базой данных сводятся к манипуляциям с таблицами.
Таблица состоит из столбцов (полей) и строк (записей); имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка— конкретный объект. Каждый столбец таблицы — это совокупность значений конкретного атрибута объекта.
В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементам данных. Если при вычислении логического условия относительно элемента данных в результате получено значение «истина», то этот элемент принадлежит домену. В простейшем случае домен определяется как допустимое потенциальное множество значений одного типа. Например, совокупность дат рождения всех сотрудников составляет «домен дат рождения», а имена всех сотрудников составляют «домен имен сотрудников». Домен дат рождения имеет тип данных, позволяющий хранить информацию о моментах времени, а домен имен сотрудников должен иметь символьный тип данных.
В один домен могут входить значения из нескольких столбцов, объединенных, помимо одинакового типа данных, еще и логически. Например, домен может состоять из столбца с датой поступления на работу и столбца с датой увольнения. Но в этот домен нельзя включить столбец с датой рождения, так как дата поступления или увольнения с работы не связана с датой рождения.
Если два значения берутся из одного и того же домена, то можно выполнять сравнение этих двух значений. Например, если два значения взяты из домена дат рождения, то можно сравнить их и определить, кто из сотрудников старше. Если же значения берутся из разных доменов, то их сравнение не допускается, так как, по всей вероятности, оно не имеет смысла. Например, из сравнения имени и даты рождения сотрудника, ничего определенного не выйдет.
В большинстве систем управления реляционными базами данных понятие домена не реализовано. Каждый элемент данных в отношении может быть определен с указанием его адреса в формате A[i, j], где, А — элемент данных, i — строка отношений, j — номер атрибута отношения.
Множество значений, А [i, j] при постоянном i и всех возможных j образуют кортеж (или попросту строку таблицы). Количество всех кортежей в отношении определяет его мощность, или кардинальное число. Мощность отношения в таблице равна 5. Мощность отношения, в отличие от порядка отношения, может со временем меняться. Совокупность всех кортежей образует тело отношения (или собственно таблицу).
Поскольку отношения являются математическими множествами, которые по определению не могут содержать совпадающих элементов, никакие два кортежа в отношении не могут быть дубликатами друг друга в любой момент времени.
Каждый столбец (поле) имеет имя, которое обычно записывается в верхней части таблицы. При проектировании таблиц в рамках конкретной СУБД имеется возможность выбрать для каждого поля его тип, то есть определить набор правил по его отображению, а также определить те операции, которые можно выполнять над данными, хранящимися в этом поле. Наборы типов могут различаться у разных СУБД.
Имя поля должно быть уникальным в таблице, однако различные таблицы могут иметь поля с одинаковыми именами. Любая таблица должна иметь, по крайней мере, одно поле; поля расположены в таблице в соответствии с порядком следования их имен при ее создании. В отличие от полей, строки не имеют имен; порядок их следования в таблице не определен, а количество логически не ограничено.
Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции — среди них не существует «первой», «второй», «последней». Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом (primary key). Таким полем, например, может быть его порядковый номер в журнале для каждого ребенка, который сможет обеспечить уникальность каждой записи в таблице. Ключ должен обладать следующими свойствами:
- · Уникальностью. В каждый момент времени никакие два различных кортежа отношения не имеют одинакового значения для комбинации входящих в ключ атрибутов. То есть в таблице не может быть двух строк, имеющих одинаковый идентификационный номер или номер паспорта.
- · Минимальностью. Ни один из входящих в ключ атрибутов не может быть исключен из ключа без нарушения уникальности. Это означает, что не стоит создавать ключ, включающий и номер паспорта, и идентификационный номер. Достаточно использовать любой из этих атрибутов, чтобы однозначно идентифицировать кортеж. Не стоит также включать в ключ неуникальный атрибут, то есть запрещается использование в качестве ключа комбинации идентификационного номера и имени служащего. При исключении имени служащего из ключа все равно можно уникально идентифицировать каждую строку.
Выполнение условия уникальности является обязательным. В то же время при необходимости может быть допущено нарушение условия минимальности.
Каждое отношение имеет, по крайней мере, один возможный ключ, поскольку совокупность всех его атрибутов удовлетворяет условию уникальности — это следует из самого определения отношения.
Один из возможных ключей произвольно выбирается в качестве первичного ключа. Остальные возможные ключи, если они есть, принимаются за альтернативные ключи. Например, если в качестве первичного ключа выбрать идентификационный номер, то номер паспорта будет альтернативным ключом.
Среда SQL Server Management Studio — это единая универсальная среда для доступа, настройки и администрирования всех компонентов MS SQL Server, а также для разработки компонентов системы, редактирования текстов запросов, создания скриптов и пр. Благодаря наличию большого количества визуальных средств управления, среда SQL Server Management Studio позволяет выполнять множество типовых операций по администрированию MS SQL Server администраторам с любым уровнем знаний SQL Server. Удобная среда разработки, встроенный веб-браузер для быстрого обращения к библиотеке MSDN или получения справки в сети, подробный учебник, облегчающий освоение многих новых возможностей, встроенная справка от сообществ в Интернете и многое другое позволяют максимально облегчить процесс разработки в среде SQL Server, а также дает богатые возможности для создания различных сценариев SQL Server.
Я использую модель «сущность-связь», или ER-модель, которая является наиболее известным представителем класса семантических моделей предметной области. ER-модель обычно представляется в графической форме, с использованием оригинальной нотации создателя модели, называемой ER-диаграмма, либо с использованием других графических нотаций. Для моей базы данных, отвечающей заданию, было выбрано 3 сущности, позволяющие реализовать решение поставленных проблем. Эти сущности:
- 1. Таблица «Вылет» (номер самолета, номер маршрута, продажа билетов, дата-время вылета, дата-время прилета, рейс).
- 2. Таблица «Маршрут» (номер маршрута, расстояние, пункт вылета, пункт назначения).
- 3. Таблица «Самолет» (номер самолета, тип самолета, число мест, заполнение, скорость).
Между таблицами реализуются связи, обозначенные на рисунке 1. Выбор и представление таблиц и связей объясняется заданием и позволяет разработать на его основе действующую базу данных.
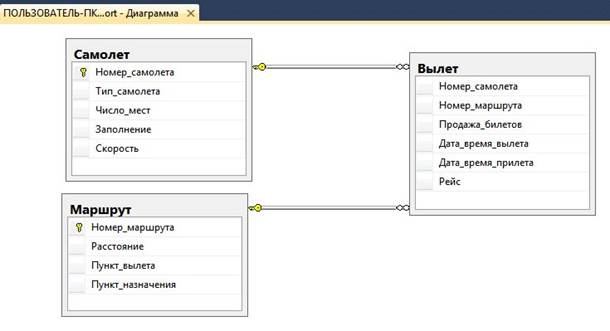
Рисунок 1 — Диаграмма базы данных.
Описание структуры таблицы «Вылет» в среде SQL Server Management Studio показана на рисунке 2.
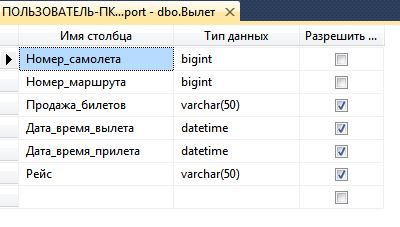
Рисунок 2 — Описание структуры таблицы «Вылет».
Описание структуры таблицы «Маршрут» в среде SQL Server Management Studio показана на рисунке 3.
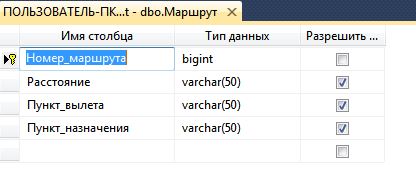
Рисунок 3 — Описание структуры таблицы «Маршрут».
Описание структуры таблицы «Самолет» в среде SQL Server Management Studio показана на рисунке 4.
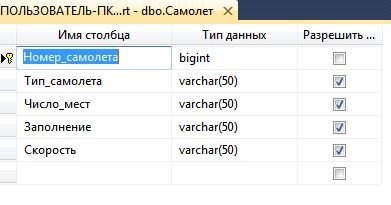
Рисунок 4 — Описание структуры таблицы «Самолет».
Введенные данные в таблицу «Вылет» с помощью средыSQL Server Management Studio показаны на рисунке 5.
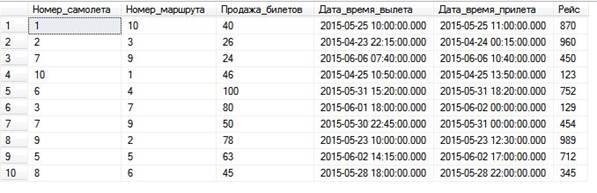
Рисунок 5 — Введенные данные в таблице «Вылет».
Введенные данные в таблицу «Маршрут» с помощью средыSQL Server Management Studio показаны на рисунке 6.
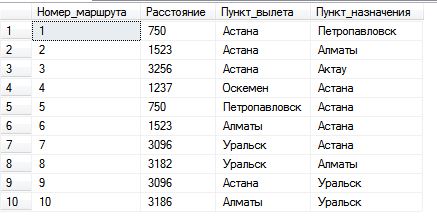
Рисунок 6 — Введенные данные в таблице «Маршрут».
Введенные данные в таблицу «Самолет» с помощью средыSQL Server Management Studio показаны на рисунке 7.
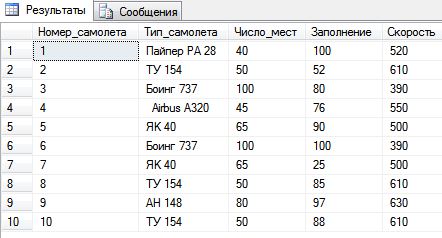
Рисунок 7 — Введенные данные в таблице «Самолет».