Применение систолических процессоров для построения нейросред

Для некоторых задач необходим модуль постобработки (Post-Processing Min-Max Search), который проводит поиск минимума или максимума. Функция активации реализована в виде внешнего чипа, содержащего таблицу поиска. Некоторые типы нейросетей нуждаются не только в нелинейной функции активации, но и в линейной функции f (x) = x. Поэтому чип имеет два выхода: address — адрес в таблице поиска и data… Читать ещё >
Применение систолических процессоров для построения нейросред (реферат, курсовая, диплом, контрольная)
Этот класс вычислительных систем создавался с ориентацией на применение в области нейросетей. Основная идея построения систолических процессоров состоит использовании специальных обрабатывающих элементов, простых по своим функциям и структуре, эти элементы образуют процессорную матрицу, через которую идет поток данных, изменяемых каждым элементом. При этом может быть достигнута высокая степень параллельности обработки данных, если отработавший элемент сразу же считывает следующую порцию данных для обработки. Недостатком этих систем может быть названа узкая специализация обрабатывающих элементов, это ведет к тому, что систолическая матрица должна быть окружена большим количеством периферийных схем, реализующих дополнительную логику.
Систолическая архитектура вычислительного устройства является решением, агрессивно эксплуатирующим параллелизм «конвейерного» типа. Несмотря на принципиальную дороговизну решения (применение специализированных аппаратных решений), систолы являются одним из самых эффективных методов решения специализированных задач, так как часто обеспечивают на конкретной задаче быстродействие, недостижимое для большинства микропроцессорных архитектур. Значительное удешевление программируемых логических матриц сводит на нет экономическую составляющую вопроса применения и пробуждает интерес исследователей к применению систол в сложных вычислительных задачах.
Систолические системы являются очень специализированными вычислителями и производятся в основном под конкретную задачу. Фактически, задача построения систолического вычислителя сводится к постороению аппаратного конвейера, имеющего достаточно большое время получения результата (т.е. большое количество ступеней) но при этом сравнительно маленькое время между последовательной выдачей результатов, так как значительное количество промежуточных значений обрабатывается на разных ступенях конвейера.
Если провести параллель в физиологии, то систолы больше всего напоминают систему сосудов и сердце, которое постоянно посылает кровь во все артерии, сосуды и капилляры тела.
Систолы отличаются простой и регулярной структурой (по крайней мере описанные в специализированной литературе):
- o Вычисления в систолах «ритмичны», последовательны, и происходят в своеобразной ячеисто-циклической манере;
- o экономически выгодно построение в небольших партиях;
- o с технической точки зрения эксплуатировать можно практически все доступные виды параллелизма;
- o модульная структура систол позволяет достаточно просто расширять систолы;
- o вычислительная эффективность систол определяется правильным построением конвейера, чаще всего наиболее эффективны простые структуры;
- o систолы выгодно используют полосу пропускания каналов доступа к памяти, отличаясь предсказуемым обращением к памяти;
Базовые принципы постороения систолических архитектур:
- 1. Систола представляет собой сеть связанных вычислительных ячеек, обычно простых;
- 2. Каждая ячейка содержит в себе буферный входной регистр, защёлкивающий данные и вычислитель, оперирующий с содержимым этого регистра. Выход вычислителя может подаваться на входы других ячеек;
- 3. Операции в систоле производятся по типу конвейерной обработки;
- 4. Вычисления в систоле регулируются с помощью общего тактового сигнала;
- 5. Результатом правильного построения систолы должна быть простая, регулярная разводка с простой топологией связей;
Приведём схему типичной систолы:
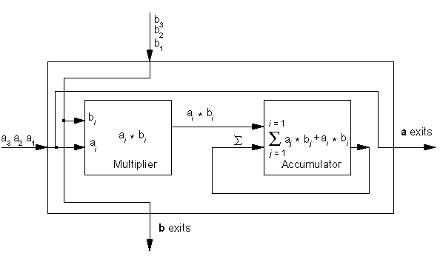
Рис. 1 Систола, дающая на выходе скалярное произведение массивов чисел
Структура систолы имеет ряд недостатков:
Общая тактовая частота должна быть такой, чтобы за время одного такта успевали полностью отработать все вычислители, на данном рисунке умножитель явно отрабатывает за в несколько раз большее время, чем сумматор. На выходе сумматора изменение суммы из-за очередной поданной пары значений производится через 2 такта. При конвейеризации устройства умножителя, обычно представляя его как сумматоры, длина конвейера удлиняется (до 9−33 тактов), но частота следования тактового сигнала может быть повышена на порядок. Съём результата производится с выходов сумматора, естественно предусматривается сигнал для его обнуления перед загрузкой очередных массивов данных.
Рассмотрим крайне показательный пример систолы: умножение матриц.
Для примера рассмотрим умножение матриц 3 на 3:
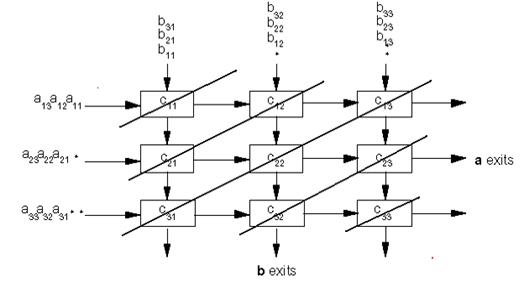
Рис. 2 Умножение матриц 3 на 3
Обычно сквозная система связей не реализуется, поэтому результаты снимаются с выходов ячеек-умножителей с верхнего левого угла до нижнего правого угла (одновременно получаемые результаты показаны толстыми наклонными линиями, соединяющими ячейки).
Некоторые замечания по разработке систол Процесс разработки ситолической структуры выглядит примерно так:
- 1. Разрабытывается алгоритм;
- 2. проектируется архитектура — поиск параллелизма (особенно конвейерного в алгоритме);
- 3. производится проекция алгоритмы на цифровые вычислительные схемы по следующему принципу:
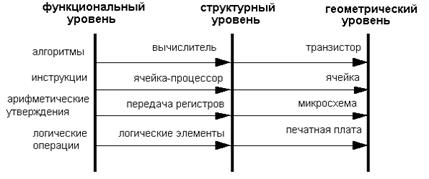
4. Отладка и доказательство правильности фнуционирования схемы.
Систолический процессор SAND.
Чип SAND (Simple Applicable Neural Device) разработан для применения в промышленных и исследовательских системах реального времени. Чип способен реализовывать нейросети с максимальным числом входов 512.
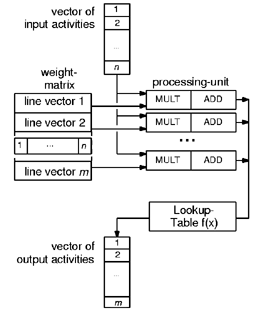
Принцип параллельной работы обрабатывающих элементов показан на рис.
Рис. 21 Параллельная работа обрабатывающих элементов
Вектор входных значений (vector of input activities) подается параллельно на все обрабатывающие элементы. Матрица весов (weight-matrix) разделена на m векторов-строк (line vector), каждый из которых обрабатывается собственным обрабатывающим элементом. В результате работы каждого элемента получается одна из m выходных величин. Таким образом, для слоя нейросети, состоящего из m нейронов, можно использовать m элементов, работающих в параллельном режиме, без обмена информацией.
Существенным недостатком этого решения является необходимость иметь m блоков памяти для матрицы весов (для каждого блока). Это приводит к большому числу компонентов и высокой стоимости схемы. Можно использовать один общий блок памяти, но тогда доступ к этому блоку должен происходить на крайне высокой скорости (в m раз больше, чем в предыдущем случае). Современные чипы памяти не способны обеспечить такие скорости.
Эффективное решение этой проблемы возможно, если количество весов равно количеству входных величин (длине входного вектора). При этом рассматривается не один входной вектор, а их последовательность. Входной вектор заменяется матрицей входных значений из m колонок.
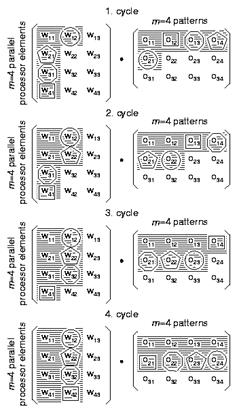
Рис. 22 Пример обработки данных (m = 4 входных вектора)
На рис. 22 показан пример обработки данных для m = 4. Четыре обрабатывающих элемента производят обработку сразу четырех входных векторов. Значения, уже переданные в чип SAND показаны на рисунку заштрихованными. Четыре обрабатывающих элемента показаны кругом, пятиугольником, восьмиугольником и квадратом. За каждый цикл перемножаются два одинаково выделенных элемента. За каждый цикл из памяти необходимо передавать только один весовой коэффициент и одно входное значение (остальные значения уже выбирались ранее). Четыре цикла обрабатывающий элемент работает с одним и тем же весовым коэффициентом, каждый четвертый цикл вес обновляется. Таким образом на шине весов наблюдается непрерывный поток значений-весов. Входные значения передаются от одного обрабатывающего элемента к следующему через внутренние регистры. Каждый цикл происходит передача очередного входного значения, поэтому на входной шине также наблюдается непрерывный поток значений.
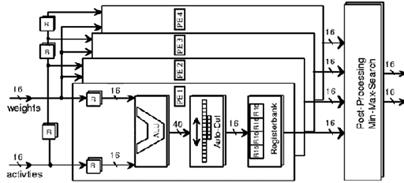
Рис. 23 Структура чипа SAND
Архитектура кристалла SAND показана на рис. 23. Он содержит четыре параллельных обрабатывающих элемента PE (Processing Elements), каждый из которых снабжен АЛУ и блоками отсечения (auto-cut). АЛУ используется для умножения векторов. Так как АЛУ накапливает входные значения, выходная шина имеет разрядность 40 бит (это ограничивает число входных нейронов до 512). Блок отсечения приводит снижает разрядность до 16 с контролем переполнения и потери точности. Окно, выбирающее 16 бит из 40 может быть смещено пользователем по его усмотрению.
Для некоторых задач необходим модуль постобработки (Post-Processing Min-Max Search), который проводит поиск минимума или максимума. Функция активации реализована в виде внешнего чипа, содержащего таблицу поиска. Некоторые типы нейросетей нуждаются не только в нелинейной функции активации, но и в линейной функции f(x) = x. Поэтому чип имеет два выхода: address — адрес в таблице поиска и data — линейное выходное значение. Для более быстрого вычисления блоки сложения и умножения размещены последовательно, образуя конвейер. Входные значения вначале умножаются на соответствующие веса, а затем складываются с предыдущими значениями.