Параллелизация вычислений.
Численное решение уравнения теплопроводности методом конечных разностей

С помощью MPI_Scatter разбиваем оба вектора на куски и рассылаем их соответствующим процессам. С помощью MPI_Scatter разбиваем оба вектора на куски и рассылаем их соответствующим процессам. Вместо хранения матрицы A будем использовать функцию, возвращающую её элемент: Собираем куски вектора в один на нулевом процессе с помощью MPI_Gather. Собираем куски вектора в один на нулевом процессе… Читать ещё >
Параллелизация вычислений. Численное решение уравнения теплопроводности методом конечных разностей (реферат, курсовая, диплом, контрольная)
Основными вычислениями, которые целесообразно распараллелить в алгоритмах методов наискорейшего спуска и сопряженных градиентов являются матричные и векторные операции: умножение матрицы на вектор, сумма векторов и скалярное произведение вектора.
Вместо хранения матрицы A будем использовать функцию, возвращающую её элемент:
double A (int i, int j, int xys, double s).
{.
if (i == j).
return 1 + 4 * s;
if (i + 1 == j || i — 1 == j || i + xys == j || i — xys == j).
returns;
return 0;
}.
Параллелизация скалярного произведения (рисунок 7):
С помощью MPI_Scatter разбиваем оба вектора на куски и рассылаем их соответствующим процессам.
Каждый процесс вычисляет свою часть скалярного произведения.
С помощью MPI_Reduce выполняем редукцию суммированием, получая результат скалярного произведения в нулевом процессе.
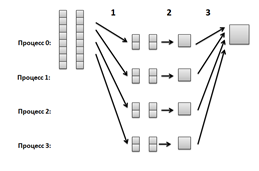
Рисунок 7. Параллелизация скалярного произведения.
I. Параллелизация умножения матрицы на вектор (рисунок 8):
- 1. Так как значения элементов матрицы мы берем из функции, которая доступна всем процессам, то рассылать нужно только вектор с помощью MPI_Broadcast.
- 2. Каждый процесс вычисляет свой кусок результирующего вектора
- 3. Собираем куски вектора в один на нулевом процессе с помощью MPI_Gather.
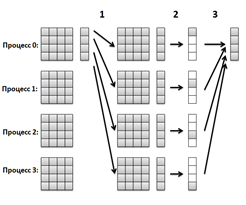
Рисунок 8. Параллелизация умножения матрицы на вектор
II. Параллелизация суммирования векторов (рисунок 9):
- 1. С помощью MPI_Scatter разбиваем оба вектора на куски и рассылаем их соответствующим процессам.
- 2. Каждый процесс вычисляет свой кусок результирующего вектора
- 3. Собираем куски вектора в один на нулевом процессе с помощью MPI_Gather.
Рисунок 9. Параллелизация суммирования векторов.