Языковые модели.
Исследование параметров сегментации при статистическом машинном переводе с арабского на русский язык

Сглаживание Виттена-Белла Сглаживание Виттена-Белла является способом включить в модель фактор разнообразия возможных предсказываемых слов. Таким образом, можно будет учесть тот факт, что для некоторых историй существует мало возможных продолжений с высокой вероятностью, и, соответственно, вероятность встретить не употреблявшуюся в ранее n-грамму достаточно мала. В то же время, для других… Читать ещё >
Языковые модели. Исследование параметров сегментации при статистическом машинном переводе с арабского на русский язык (реферат, курсовая, диплом, контрольная)
Основные идеи.
Еще одним ключевым компонентом системы машинного перевода, как правило, является языковая модель. Языковая модель отражает вероятность того, что в естественном языке встретится та или иная фраза. Преимущества использования подобной модели очевидны — она помогает переведенному тексту быть не только соответствовать оригиналу по смыслу, но и быть легко читаемым с точки зрения целевого языка.
Языковая модель обеспечивает «гладкость» текста в первую очередь за счет того, что позволяет более точно выбирать подходящие слова и помогает определить наиболее правильный порядок слов. Например, вероятностная языковая модель должна помочь выбрать частотный порядорк слов в следующем примере:
Plm (the house is small) > Plm (small is the house).
В хорошей языковой модели вероятность первого высказывания будет значительно выше, чем вероятность второго, поэтому должен быть выбран вариант с таким порядком слов.
Другим случаем, в котором оказывается языковая модель оказывается полезна, является лексический выбор. Часто использование того или иного слова в качестве перевода зависит от контекста, что и позволяет учесть языковая модель. К примеру, в следующем примере она должна определить более вероятный вариант:
Plm (I'm going home) > Plm (I'm going house).
Вариант home намного чаще используется после слова going, поэтому он является предпочтительным с точки зрения вероятностной языковой модели для английского языка.
Наиболее популярный метод создания языковых моделей — использование n-грамм. Для того, чтобы рассчитать вероятность той или иной n-граммы, мы можем сначала рассчитать вероятности каждого отдельного слова:
p (w1, w2, …, wn) = p (w1) p (w2| w1) … p (wn| w1, w2, …, wn-1).
Таким образом, вероятность каждого слова равна произведение вероятностей предшествующих ему слов — истории. Для того, чтобы сделать вычисления технически возможными, ограничим истории до m слов:
p (wn| w1, w2, …, wn-1) = p (wn| wn-m, …, wn-2, wn-1).
Такая модель, учитывающая лишь ограниченную историю, называется цепью Маркова. При этом, количество элементов, входящих в историю, именуется порядком цепи, а сама идея того, что лишь ограниченное количество элементов цепи влияет на каждый следующий элемент — предположением Маркова. Вообще говоря, это не является правдой, но его можно использовать в вычислительных целях. Одной из наиболее популярных языковых моделей является модель на основе триграмм (то есть, марковская цепь второго порядка), но могут использоваться также биграммы, униграммы и n-граммы более высоких порядков.
Для того, чтобы вычислить вероятность того или иного слова при какой-то заданной истории, нужно лишь посчитать количество употреблений данного слова в такой ситуации и разделить его на число употреблений такой истории в корпусе в принципе:
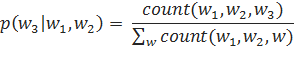
Взглянем, к примеру, на вероятности слов для трех следующих историй в корпусе Europarl, выделенные в [Koehn, 2009]:
Таблица 2. Вероятности следующего слова для истории «the green»
The green (1748 употреблений) | |||
Слово. | Употребления. | Вероятность. | |
Paper. | 0,458. | ||
Group. | 0,367. | ||
Light. | 0,063. | ||
Party. | 0,015. | ||
ecu. | 0,012. | ||
Таблица 3. Вероятности следующего слова для истории «the red» .
The red (225 употреблений) | |||
Слово. | Употребления. | Вероятность. | |
Cross. | 0,547. | ||
Tape. | 0,138. | ||
Army. | 0,040. | ||
Card. | 0,031. | ||
. | 0,022. | ||
Таблица 4. Вероятности следующего слова для истории «the blue» .
The blue (54 употребления) | |||
Слово. | Употребления. | Вероятность. | |
Box. | 0,296. | ||
. | 0,111. | ||
Flag. | 0,111. | ||
. | 0,056. | ||
angel. | 0,056. | ||
Из этих примеров мы можем видеть, что разные истории действительно имеют разные вероятностные распределения слов, стоящих за ними. К примеру, после слов «the red» чаще всего, с вероятностью 0,547, идет слово «cross», так как в текстах Европейского парламента, очевидно, часто употребляет название организации «Красный крест». В то же время, слово «cross» в данном корпусе не употребляется после последовательностей слов «the green» и «the blue». Вероятность того, что «cross» будет следовать за «the red», можно рассчитать как частное числа употрелений слова «cross» после «the red» и всех случаев употребления слов «the red»: .

Perlexity.
Логичной выглядит идея, что для того, чтобы оценить качество имеющейся языковой модели, стоит использовать какую-то общую меру. Одним из наиболее распространенных способов является применение perplexity — оценки, основанной на кросс-энтропии. Для того, чтобы понять, как нужно применять данную метрику, вспомним сначала формулу кросс-энтропии:
Из кросс-энтропии можно легко получить perplexity:
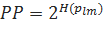
Покажем применение perplexity на примере предложения из корпуса Europarl, проанализированного в [Koehn, 2009], и основанной на триграммах модели. Выберем для данной цели следующее предложение:
I would like to commend the rapporteur on his work.
В качестве маркера начала предложения условимся использовать, для конца — .
5. Вероятности языковой модели.
Предсказанное лово | — log2. | ||
 (i|). | 0,109. | 3,197. | |
(would| i). | 0,144. | 2,791. | |
(like|I would). | 0,489. | 1,031. | |
(to|would like). | 0,905. | 0,144. | |
(commend|like to). | 0,002. | 8,794. | |
(the|to commend). | 0,472. | 1,084. | |
(rapporteur|commend the). | 0,147. | 2,763. | |
(on|the rapporteur). | 0,056. | 4,150. | |
(his|rapporteur on). | 0,194. | 2,367. | |
(work|on his). | 0,089. | 3,498. | |
(.|his work). | 0,290. | 1,785. | |
(|work.). | 0,99 999. | 0,14. | |
Среднее. | 2,634. | ||
Стоит отметить, что с помощью данной меры мы не просто считаем, сколько слов было «угадано» правильно. Perplexity основывается на том, какая вероятность была присвоена действительно встретившимся словам. Хорошая языковая модель не будет «тратить» вероятности на редко встречающиеся последовательности слов, так как иначе мало вероятности достанется более вероятным вариантам.
Сглаживание.
Еще одним крайне важным моментом при разработке языковой модели является вопрос сглаживания. Согласно рассмотренной выше модели, если n-грамма вовсе не встречается в модели, то ей присваивается вероятность, равная нулю. Возможно, такая оценка является слишком радикальной. Кроме того, в некоторых случаях она является недостаточно информативной. К примеру, если модель рассматривает несколько вариантов, каждый из которых ранее не встречался в текстах, то каждый из них будет иметь вероятность, равную нулю, и мы никоим образом не может сравнить их друг с другом. Таким образом, нам нужно присваивать какие-либо вероятности не встречавшимся ранее n-граммам. Интересно отметить, что эта проблема становится все острее при увеличении порядка рассматриваемых языковых моделей.
Одним из самых простых способов решить проблему нлеовых вероятностей является сглаживанием с добавлением единицы (или любого иного фиксированного заранее числа). Для того, чтобы реализовать его, прибавим по единице к каждому подсчету употреблений. Кроме того, для того, чтобы получившаяся мера отвечала определению вероятности, прибавим к количеству встретившихся в тексте n-грамм количество всех возможных триграмм. Таким образом, формулу для вычисления вероятности n-граммы можно записать как.
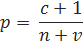
Здесь, c — количество употреблений n-граммы, n — количество n-грамм в корпусе, а v — количество всех возможных n-грамм. Недостатком данного метода является то, что он присваивает слишком большие вероятности не встречавшимся ни разу вероятностям. Эту проблему можно исправить, прибавляя к каждому числу употреблений не единицу, а некоторое число a. Тогда, формулу можно представить как.
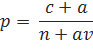
Определить оптимальное значени a можно, оптимизируя perplexity по a на каком-либо тестовом тексте.
Сглаживание Гуда-Тюринга.
Также популярным вариантом при построении языковых моделей является сглаживание Гуда-Тюринга. В его основе — идея о том, что все употребления n-грамм нужно как-либо обработать для того, чтобы получить более достоверную информацию о том, как часто такая n-грамма может встретиться в текстах в дальнейшем. Для этого используются данные о том, сколько n-грамм встречается в корпусе какое-то определенное число раз, а таке тех, которые не встречаются вовсе. Для оценки ожидаемой вероятности используется формула.
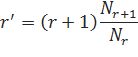
где r' = ожидаемое количество употреблений n-граммы в тексте, r — количество употреблений n-граммы в исходном корпусе, Nr — количество n-грамм, действительно в исходном корпусе r раз.
В качестве примера приведем еще раз статистику из корпуса Europarl по [Koehn, 2009]:
Таблица 6. Применение сглаживания Гуда-Тюринга.
Употребления | N-граммы с данным числом употреблений. | Ожидаемое число употреблений. | Тестовый подсчет. | |
r. | Nr. | r'. | t. | |
7 514 941 065. | 0,15. | 0,16. | ||
1 123 844. | 0,46 539. | 0,46 235. | ||
263 611. | 1,40 679. | 1,39 946. | ||
123 615. | 2,38 767. | 2,34 307. | ||
73 788. | 3,33 753. | 3,35 202. | ||
49 254. | 4,36 967. | 4,35 234. | ||
35,869. | 5,32 928. | 5,33 762. | ||
21,693. | 7,43 798. | 7,15 074. | ||
14,880. | 9,31 304. | 9,11 927. | ||
4,546. | 19,54 487. | 18,95 948. | ||
К примеру, если мы хотим подсчитать ожидаемое количество употреблений n-грамм, встречающихся в корпусе четыре раза, то сделать это можно следующим образом:
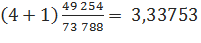
Как мы видим, расчетные значение ожидаемого количества употреблений достаточно близки тестовым показателям. Важным преимуществом данного метода Шуда-Тюринга является простота вычислений. С другой стороны, данный способ сглаживания может быть ненадежен в случаях, когда число употреблений велико (а n-грамм с таким числом употреблений, наоборот, мало).
Интреполяция.
Языковые модели разного порядка можно также сочетать с помощью интерполяции. Такой подход часто позволяет повысить точность модели и, кроме того, является дополнительным инструментом в решении проблемы не встретившихся при построении модели, но потенциально возможных n-грамм.
Интерполированную языковую модель можно построить с помощью линейной комбинации моделей разного порядка. Построим, к примеру, такую модель на основе униграмм, биграмм и тригамм:
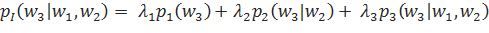
Таким образом, каждая отдельная языковая модель pn вносит свою лепту в итоговую оценку. При этом, каждая такая вероятность умножается на весовой коэффициент лn. Отметим, что для того, чтобы языковая модель pI оставалась вероятностным настоящим распределением, каждый весовой коэффициент лn должен находиться в пределах промежутка от нуля до единицы. Кроме того, сумма всех коэффициентов лn должна равняться единице:
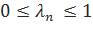
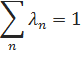
Основная сложность при построении подобной языковой модели — определение размеров весовых коэффициентов n. Их можно вычислить при помощи оптимизации на каком-либо тестовом корпусе.
.
При построении интерполированных языковых моделей также используется понятие рекурсивной интерполяции:
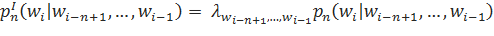
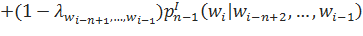
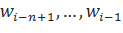
Здесь, параметры л отражают, насколько сильно мы доверяем модели уровня n. При этом, можно сделать параметры л зависимыми от истории — то есть, для каждой конкретной истории в таком случае будет свое значение параметра. С другой стороны, в реальной жизни у нас вряд ли получится получить достоверные оценки для каждой конкретной истории: это потребовало бы наличия слишком большого тренировочного корпуса. Поэтому, есть смысл сгруппировать данные по какому-либо принципу. Одним из способов такой группировки могло бы стать, к примеру, объединение историй по частотности.
Откат Интересным спобом справиться с проблемой не встречающихся n-грамм является также откат к n-граммам меньшего порядка в случае, если рассматриваемая n-грамма не встречалась в исходном корпусе. Определим формулу рекурсивного отката:
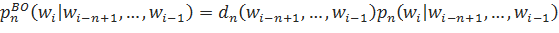
.
;
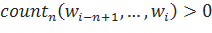
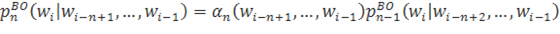
в ином случае.
Таким образом, в ситуациях, когда мы встречаем n-грамму, встречавшуюся нам в исходном корпусе, мы используем ее вероятность, иначе — «возвращаемся» к n-грамме на порядок ниже.
Так как для нас важно, чтобы языковая модель оставалась настоящим вероятностным распределением, нужно удостовериться, что сумма всех возможных исходов все еще равна единице. Для этого вводится дисконт d, принадлежащий отрезку от нуля до единицы, на который умножается вероятность, получившаяся в языковой модели каждого порядка pn.
Как и в случае с интерполяцией, мы можем захотеть, чтобы параметр d зависел от истории, для того, чтобы дать преимущества часто встречающимся n-граммам. Реже встречающиеся истории, в свою очередь, позволят выставить более высокие оценки б для откатов к n-граммам более низкого порядка.
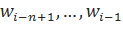
Сглаживание Виттена-Белла Сглаживание Виттена-Белла [Witten, Bell 1989] является способом включить в модель фактор разнообразия возможных предсказываемых слов. Таким образом, можно будет учесть тот факт, что для некоторых историй существует мало возможных продолжений с высокой вероятностью, и, соответственно, вероятность встретить не употреблявшуюся в ранее n-грамму достаточно мала. В то же время, для других вероятных вариантов может быть достаточно много, и, в таком случае, существует куда большая вероятность встретить новую n-грамму. Постараемся определить понятие многообразия предсказываемых слов более формально. Для начала, определим количество возможных продолжений истории :

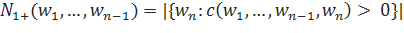
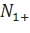
Здесь, — количество возможных продолжений, c — количество употреблений n-граммы.
Параметры л, при этом, можно определить следующим образом:
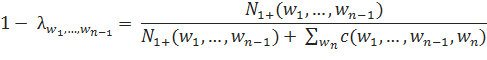
В качестве примера приведем два случая из корпуса Europarl. За словом spite обычно следует предлог of (из-за очень распространенного в английском языке словосочетания in spite of). Всего это слово встречается 993 раза, и у него есть 9 различных вариантов следующего слова, однако, 979 раз этим продолжением оказывается of, в то время как на остальные 8 вариантов приходится в общей сложности 14 продолжений.
Сравним эту ситуацию со словом constant, которое в корпусе Europarl употребляется также 993 раза. Однако, различных вариантов продолжения у него намного больше, а именно 415. Из них, к примеру, слово and встречается сразу за constant 42 раза, concern — 27 раз, pressure — 26 раз. Но также присутствует длинный хвост из слов, употребленных в такой ситуации лишь один раз. В таком случае, расчеты параметров будут выглядеть следующим образом:
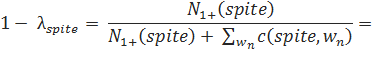
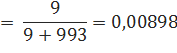
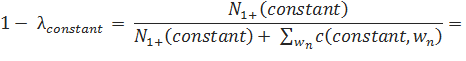
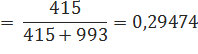
В таком случае, мы видим, что для n-грамм со словом spite меньше вероятности распределяется в пользу варианта с откатом к n-граммам более низкого порядка, так как в таких случаях вероятность новой n-граммы достаточно мала. Для n-грамм со словом constant, напротив, для модели с откатом зарезервирована относительно большая вероятность, так как в таких случаях вполне может встретиться сочетание constant с каким-либо не употреблявшимся ранее после него словом.
Также, отметим случай, когда та или иная история встречается лишь раз. Тогда,.

Такая оценка предполагает высокую вероятность не встречавшихся ранее n-грамм.
Сглаживание Кне Одним из наиболее популярным методов сглаживания в наши дни является сглаживание Кнезера-Нея [Kneser, Ney 1995], учитывающее роль разнообразия историй. В методе Кнезера-Нея подсчеты употреблений самих слов заменяюся на подсчеты историй слов. К примеру, в стандартной языковой модели, построенное на основе униграмм, оценка вероятности слова выглядит как:
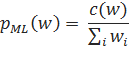
В то же время, оценка вероятности в языковой модели со сглаживанием Кнессера-Нея для униграмм оценка вероятности будет проводиться следующим образом:
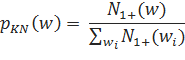
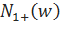
здесь — количество историй. Его можно рассчитать по такой формуле:
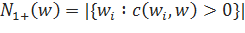
Возьмем, к примеру, слово york, которое 477 раз употребляется в корпусе Europarl. Из них, в 473 случаях перед York идет new, и лишь в 4 — какие-то иные варианты: дважды предлог of, и по одному разу предлоги in и to (в этих случаях речь идет об английском городе Йорке). В этом случае, мы будем использовать в расчетах не сами употребления слова york, а четыре его истории, три из которых справедливо получат намного меньший вес.
Модифицированное сглаживание Кнеера-Нея.
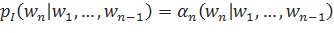
Кроме оригинального метода сглаживания Кнезера-Нея, также широко используется и модифицированное сглаживание Кнезера-Нея. Для того, чтобы сформулировать его идеи, определим следующим образом встречавшееся нам ранее понятие интерполяции:
.
;
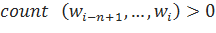
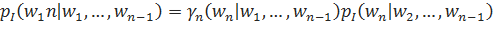
в ином случае.
Таким образом, в формуле вероятности задействовано две функции. Каждая n-грамме соответствует функция б, отвечающая за ее вероятность. Кроме того, каждой истории соответствует функция ??, отвечающая за вероятность, зарезервированную для не встретившихся в тренировочном корпусе n-грамм. Даннаяя формулировка поможет нам далее дать определение модифицированному сглаживанию Кнезера-Нея, предложенному в [Chen, Goodman 1998] (1998).
В основе модифицированного сглаживания Кнезера-Нея лежит идея абсолютного дисконта, предполагающего вычет определенного, заранее установленного значения D, принадлежащего отрезку от нуля до единицы из подсчетов упоминаний для модели, основанной на n-граммах наивысшего порядка:
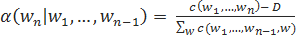
Однако, наилучшие, по мнению Чена и Гудмана результаты получаются не при вычете фиксированного значения D из каждого подсчета употреблений, а при вычислении D для каждого подсчета n-грамм. Они предложили три разных параметра D для разных количеств употреблений:
D© = D1, если c = 1,.
D© = D2, если c = 2,.
D© = D3+, если c? 3.
Значения параметров D1, D2 и D3+ можно вычислить следующим образом:
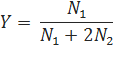
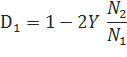
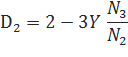
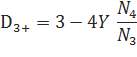
С другой стороны, параметры D могут быть также оптимизированы на каком-либо корпусе.
Параметр, влияющий на вероятность, присваиваемую не встретившимся ранее n-граммам, предлагается рассчитывать по следующей формуле:
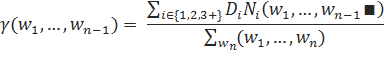
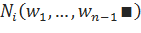
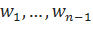
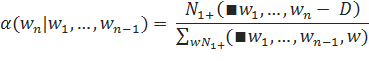
Здесь, для — количество расширений историй, встретившихся один, два или три и более раз, соответственно.
Вычислять б для n-грамм более низких порядков предлагается следующим образом:
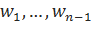
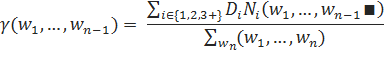
Как видно из формулы, для вычисления данного параметра используется подсчет историй, а не просто подсчет употреблений слов. При этом, здесь снова используются три разных значчений D (D1, D2 и D3+), вычисляемые на основе данных об истории .
Параметр для языковых моделей на основе n-грамм более низких порядов вычисляется также, как и для моделей на основе n-грамм наиболее высокого порядка:
Интерполированный.
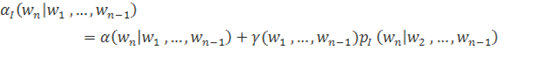
Модели с откатом определяют вероятности исходя из истории и предсказанных слов. Но в случае, если данных недостаточно, оценки могут быть не очень точными. К примеру, пусть мы имеем две n-граммы с одинаковыми историями, которые встречается по одному разу в тренировочных данных. Тогда мы присваиваем предсказываемым словам одинаковые вероятности. Однако, одно из них вполне может быть выбросом, в то время как другое — недостаточно представленным в корпусе, но частотным в текстах на данном языке вариантом. Для того, чтобы справиться с этой проблемой, можно попробовать использовать откат к модели, построенной с помощью n-грамм более низкого порядка, даже в тех случаях, когда n-грамма, а самом деле встречается в тренировочном корпусе. Для этого, можно видоизменить функцию б следующим образом:
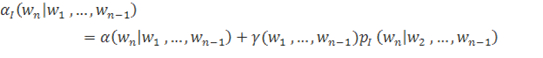
Функция в таких случаях также должна соответственно уменьшаться.