Стратегия синтеза алгоритма решения задачи

Данная задача решается с помощью алгоритма «вперед-назад», который позволяет найти в скрытой марковской модели вероятность попадания в состояние s на t-ом шаге при последовательности наблюдений O и (скрытой) последовательности состояний X. Где Vt, k — вероятность наиболее правдоподобной последовательности состояний, ответственной за появление первых t наблюдаемых символов, завершающейся… Читать ещё >
Стратегия синтеза алгоритма решения задачи (реферат, курсовая, диплом, контрольная)
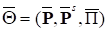
Принятая модель алгоритма определяет итеративную стратегию синтеза алгоритмов, которая сводится к преобразованию исходной модели =(P, Ps, П), приводящему к цели в виде оптимальной модели корректного алгоритма, путем итерационного пересчета параметров модели до схождения.
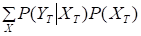
Постановка задачи. Известна наблюдаемая величина y (t) в виде последовательности YT=y0, y1,…, yТ-1 длины Т, порождаемая последовательностью O=o1o2…oT. Вероятность наблюдать y (t) равна P (YT)=, где сумма задаётся по всем возможным скрытым переменным x (t) в виде последовательности скрытых узлов XT=x0, x1,…, xТ-1. По имеющимся данным y (t) необходимо определить скрытые параметры наиболее вероятной последовательности состояний марковской цепи S=si1…siT.
Решение сформулированной задачи может быть достигнуто за три этапа, каждый из которых реализуется известным алгоритмом.
Первый этап: За T шагов в модели =(P, Ps, П) порождается последовательность наблюдений O1,T=o1,…, oT, причем в момент t для состояния s: Xi=i вероятность P (O1,t-1Xt=s) того, что во время переходов образовалась последовательность наблюдений O1,t-1, а P (Ot, TXt=s) — вероятность того, что после этого состояния наблюдается последовательность наблюдений Ot, T.
Ищется вероятность P (Xt=sO)=P (Xt=sO1,t-1Ot, T) того, что в момент t цепь будет в состоянии s.
1. Для произвольного состояния s в произвольный шаг t вероятность P (O1,tXt=si) того, что на пути к нему была произведена последовательность O1, t для следующих t можно вычислить рекуррентно:
P (O1,tXt=si)=.
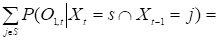
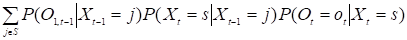
=.
Вероятность попасть в состояние s на t-ом шаге, учитывая, что после перехода произойдет событие ot будет равна вероятности быть в состоянии j на t-ом шаге, умноженной на вероятность перейти из состояния j в s, произведя событие ot для всех jS.
2. Вероятность того, что после произвольного состояния s будет произведена последовательность Ot+1,T определяются рекуррентно:
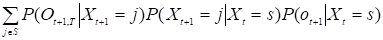
P (Ot, TXt=s)=.
3. Чтобы найти вероятность того, что будет произведена цепочка событий, P (O), нужно просуммировать произведение обеих вероятностей для всех состояний при произвольном шаге t:
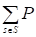
P (O)=(O1,tXt=s)P (Ot, TXt=s),.
а поскольку будущее марковской цепи не зависит от прошлого и вероятность наблюдения события Ot не зависит от прошлых наблюдений последовательности O1,t-1, то вероятность того, что в момент t цепь будет в состоянии s:
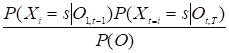
P (Xt=sO)=P (Xt=sO1,t-1Ot, T)=.
Данная задача решается с помощью алгоритма «вперед-назад» [9−11], который позволяет найти в скрытой марковской модели вероятность попадания в состояние s на t-ом шаге при последовательности наблюдений O и (скрытой) последовательности состояний X.
Второй этап: По заданной HMM с пространством состояний S={s1, s2,…, sK}, начальными вероятностями i нахождения в состоянии i и вероятностями Pi, j перехода из состояния i в состояние j, по наблюдаемым y1,…, yT и множества исходных информаций Jin ищется «оптимальная» наиболее правдоподобная последовательность состояний скрытых узлов S=s1…sT (путь Витерби), наиболее точно описывающую данную модель. Тогда наиболее вероятная последовательность состояний x1,…, xT задается рекуррентными соотношениями:
V1,k=P (y1k)k, Vt, k=P (ytk), (2).
где Vt, k — вероятность наиболее правдоподобной последовательности состояний, ответственной за появление первых t наблюдаемых символов, завершающейся в состоянии k. Путь Витерби ищется по состояниям x, удовлетворяющих уравнению (2), т. е.
xT=.
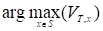
xt-1=.
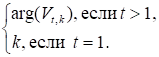
Для решения данной задачи используют алгоритм Витерби (Andrew Viterbi, 1967 год), позволяющего на основе последовательности наблюдений получить наиболее правдоподобную последовательность скрытых состояний (путь Витерби) скрытой марковской модели [12−15].
Третий этап: По заданной выходной последовательности наблюдений O определяются неизвестные параметры HMM, максимизирующие вероятность наблюдений O.
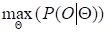
*=.
Причем число моментов времени r, в которых осуществляются наблюдения, устанавливается заранее и состоит из следующих шагов:
- 1) определение всех последовательностей состояний модели Si={si1,…, sir}, i=1,…, r проблеморазрешающей системы в заданные моменты времени;
- 2) оценка вероятностей P (Si) появления для каждой последовательности Si, i=1,…, r, выявленной на предыдущем шаге, путём вычисления произведений вероятностей переходов между состояниями модели в течение интервалов, ограниченных установленными контрольными моментами времени, а именно:
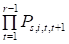
P (Si)=,.
где Ps, i, t, t+1-вероятность перехода из состояния sit, в котором система пребывала в момент времени t, в состояние si, t+1, занятого в момент t+1;
3) вероятность появления наблюдаемой последовательности X={x1,…, xr} для последовательностей состояний Si, i=1,…, r.
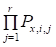
Pix=P (Si),.
где Px, i, j-вероятность получения наблюдаемой характеристики xj при состоянии sij;
4) выбор наиболее вероятной последовательности состояний Smax{Si}i=1,…, r, соответствующей наибольшей вероятности.
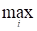
{P}x, max=Pix i =1,…, r.
Данный этап стратегии реализуется алгоритмом Баума-Велша (Baum — Welch algorithm) [10, 16].