Повторить.
Метод иерархического Байеса

Анализ предпочтений на рынке услуг сотовых операторов будет проводиться с помощью функции RhierMlnRwMixture. Выбор был сделан в пользу данной модели, поскольку по описанию, она наиболее близка к той, что используется в сервисе Sawtooth. RhierMlnRwMixture — это алгоритм иерархической мультиноминальной регрессии со миксом гетерогенных распределений. На каждом шаге значения параметров генерируются… Читать ещё >
Повторить. Метод иерархического Байеса (реферат, курсовая, диплом, контрольная)
На каждом шаге мы переоцениваем один из интересующих нас параметров, учитывая данные по другим двум параметрам. Данная техника соответствует алгоритму «Gibbs sampling».
Подробное описание итераций Марковской цепи мы начнем с шага, на котором мы получаем новые значения в для каждого респондента индивидуально. Мы будем использовать символ в0 («beta old») для того, чтобы выделить оценку частичных полезностей, полученную на предыдущей итерации. Величина, которую мы сгенерируем в качество новой оценки, будет фиксироваться нами как вn («beta new»).
Далее мы проведем тест вn. Если новая оценка продемонстрирует улучшение, то она будет принята, и мы используем ее как в0 на следующей итерации. Если же мы не выявим улучшений, то мы примем ее или отвергнем новую оценку с вероятностью того, насколько она хуже предыдущей оценки.
Для того, чтобы получить вn мы создаем случайный вектор d («различие») из распределения со средним значением равным 0 и ковариационной матрицей, пропорциональной D, такой что:
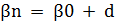
Мы считаем вероятность «правдоподобия» из формулы байеса z, используя формулу Pk для логит модели. Это делается с помощью вычисления вероятности каждого выбора, который делает индивид внутри карточки. После того как мы провели вычисления мы создаем значения P0 и Pn соответственно.
Помимо «правдоподобия» мы также считаем плотность вероятности для каждой из оценок в, при условии данных изначально параметров б и D, которые установлены как «априорные» величины в Байесовской модели. Мы называем эти переменные d0 и dn соответственно.
Относительные плотности вероятностей рассчитываются по формуле:
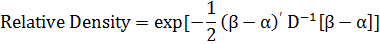
В завершение мы считаем соотношение:
В байесовском подходе мы установили, что «апостериорные вероятности» пропорциональны произведению «правдоподобия» и «априорных вероятностей». Вероятности P0 и Pn — это «правдоподобия» при условии в0 и вn. Частоты d0 и dn пропорциональны вероятностям получить оценки в0 и вn. Они используются в Байесовском уравнении в качестве «априорных вероятностей». Таким образом, — это соотношение «апостериорных вероятностей» двух оценок в0 и вn при условии исходных оценок б и D в качестве информации из данных.
Если равен объединению вероятностей двух событий, то вn обладает «апостериорной вероятностью» либо равной в0. Это значит, что мы принимаем вn как нашу следующую оценку в0. Если больше или меньше объединения вероятностей двух событий, то вn обладает «апостериорной вероятностью» меньшей или большей, чем в0. Мы должны принять решение с помощью уравнения детального баланса, оставляем ли мы вn как нашу следующую оценку в0 с вероятностью g, или мы получим вn в одной из следующих итераций. Подводя итог, достаточным критерием для точного принятия вn является соотношение «апостериорных вероятностей» равное 1-му.
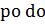
Как было сказано ранее, существуют два подхода для принятия решения по поводу вn. Если вn лучше соответствует данным, чем в0, то Pn будет гораздо больше, чем P0. Это, в свою очередь, значит, что соотношение будет больше. Тем не менее, обе относительные плотности тоже участвуют в формуле соотношения. Следовательно, у большей плотности больше преимуществ The CBC/HB System for Hierarchical Bayes Estimation Version 5.0 Technical Paper P8.
Мы упоминали, что вектор d («вектор различия») получается из распределения со средним равным нулю и ковариационной матрицей, пропорциональной D, но мы не уточнили аспект пропорциональности. В литературе распределение, из которого берется d, называется «jumping distribution», поскольку оно обуславливает размер случайного прыжка из в0 в вn. Пропорциональность и длина прыжка должна выбираться исследователем тщательно, потому что от нее зависит скорость сходимости цепи. Слишком большие прыжки, к сожалению, не будут приниматься, а слишком маленькие — уменьшат скорость сходимости.
«Алгоритм Metropolis-Hastings может быть описан пропорцией „прыжков“, которые были приняты. Для многомерного нормального распределения оптимальным является следующие пропорции принятых „прыжков“. Приблизительно 44% „прыжков“ принимается в одном измерении, и количество принятых „прыжков“ снижается до 23%, когда алгоритм работает с большим числом измерений… Такое описание позволяет подстраиваться под процесс симуляции Gelman, A., Carlin, J. B., Stern H. S. and Rubin, D. B. (1995) „Bayesian Data Analysis,“ Chapman & Hall, Suffolk. P 335».
Пакет функций для байесовского анализа Bayesm
Для анализа данных совместного анализа, основанного на дискретном выборе, в конкретной работе будет использоваться программное обеспечение R в сочетании с интерфейсом R-Studio. R позволяет сторонним разработчикам выпускать дополнения для R в виде пакетов определенного рода функций. И размещать их на форуме. Среди пакетов для свободного скачивания и установки доступен пакет bayesm, предназначенный для свободного пользования.
Пакет bayesm разработан Питером Росси. Разработчик обновляет пакет приблизительно раз в год, поэтому пакет функций относительно свежий. Последняя дата обновления 05.06.15. Функции пакета покрывают почти все популярные и часто используемые алгоритмы иерархического байесова моделирования. Регламентация данных алгоритмов присутствует в сжатом виде в инструкциях R, а в более полном виде ее можно найти в учебнике П. Росси Bayesian Statistics in Marketing.
Анализ предпочтений на рынке услуг сотовых операторов будет проводиться с помощью функции RhierMlnRwMixture. Выбор был сделан в пользу данной модели, поскольку по описанию, она наиболее близка к той, что используется в сервисе Sawtooth. RhierMlnRwMixture — это алгоритм иерархической мультиноминальной регрессии со миксом гетерогенных распределений. На каждом шаге значения параметров генерируются с помощью сочетания алгоритмов Гиббса и Метрополиса Документация пакета bayesm 3.02 [https://cran.r-project.org/web/packages/bayesm/bayesm.pdf].