Проверка на наличие гетероскедастичности Дрейпер Н., Смит Г. Прикладной регрессионный анализ.
Множественная регрессия — М.: Диалектика, 2007

Коэффициент детерминации определяет долю разброса объясняемой переменной, которая определяется регрессией Y на X; дробное отношение определяет составляющую часть разброса объясняемой переменной, которая не определяется регрессией. Фактические значения результативного признака отличаются от теоретических, вычисленных по уравнению регрессии, т. е. y и yx. Чем меньше эта разность, тем теснее… Читать ещё >
Проверка на наличие гетероскедастичности Дрейпер Н., Смит Г. Прикладной регрессионный анализ. Множественная регрессия — М.: Диалектика, 2007 (реферат, курсовая, диплом, контрольная)
Один из статистических критериев для проверки наличия гетероскедастичности (то есть непостоянной дисперсии) случайных ошибок модели линейной регрессии — Критерий Бройша-Пагана. Применяется, если есть основания полагать, что дисперсия ошибок может зависеть от некоторой совокупности наблюдаемых переменных:
где .
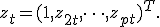
Проверяемая гипотеза сформулирована следующим образом:
остатки гомоскедастичны;
Альтернативная гипотеза:
неверна (остатки гетероскедастичны).
Процедуру вычисления статистики можно описать следующими шагами.
- 1) Начальная модель оценивается стандартным методом наименьших квадратов (МНК), определяются остатки .
- 2) Предположив гомоскедастичность модели, дисперсия ее ошибки вычисляется как
.
- 3) Вычисляются стандартизированные остатки .
- 4) Производится построение дополнительной регрессия квадратов стандартизированных ошибок на начальные значения предикаторов:
.
5) ,.
где — коэффициент детерминации построенной на предыдущем этапе регрессии.
Если статистика критерия имеет распределение хи-квадрат с степенями свободы, то гипотеза о гомоскедастичности остатков подтверждается.
Проверка качества модели
Проверка адекватности модели или, другими словами, тестирование значимости объясняющей переменной X проводится по критерию Фишера. Другими словами, проверяется, значимо ли влияние предикатора X влияет на значение объясняемой переменной Y.
Используя суммы квадратов отклонений, вычислим F-критерий Фишера по формуле:
При учете степеней свободы расчетная формула для вычисления критерия Фишера выглядит следующим образом:
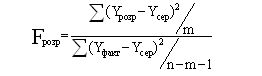
где m, (n-m-1) — число степеней свободы числителя и знаменателя зависимости соответственно; n — количество наблюдений; m — количество предикаторов.
Тестирование значимости переменной X по критерию Фишера состоит из следующих этапов:
Формулируем нулевую гипотезу H: в1=0;
Принимаем вероятность ошибки (уровень значимости) б (5%);
Производим вычисления F-отношения;
Из таблицы F-распределения Фишера определяем величину F-критическое при заданном уровне значимости (или ошибки) и по степеням свободы f1 и f2;
Если Fфакт < Fтабл то гипотезу о незначимости предикатора отклоняем с 5%-ным риском ошибиться, где Fтабл — значение F при 5%-ном риске ошибки.
Значение Fтабл определяют по специальным таблицам в зависимости от степеней свободы f1 и f2: f1=(n-m-1), f2=(n-1).
Если неравенство Fфакт > Fтабл справедливо, то можно сделать заключение об адекватности построенной модели, следовательно линейная связь между предикатором и объясняемой переменной допустима.
Итоговое оценочное значение качества модели отражается в коэффициент детерминации RІ. Если регрессия является парной, коэффициент детерминации будет совпадать с квадратом коэффициента корреляции:
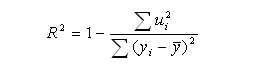
где uІi — разница между исходным значением Y и предсказанным значением с помощью построенной модели.
Коэффициент детерминации определяет долю разброса объясняемой переменной, которая определяется регрессией Y на X; дробное отношение определяет составляющую часть разброса объясняемой переменной, которая не определяется регрессией.
Для общего случая корректным является соотношение 0? RІ?1. Чем ближе коэффициент детерминации к единице, тем сильнее линейная связь между X и Y. Чем связь слабее, тем RІ ближе к нулю.
Средняя ошибка аппроксимации — еще одно средство оценки уравнения регрессии является.
Фактические значения результативного признака отличаются от теоретических, вычисленных по уравнению регрессии, т. е. y и yx. Чем меньше эта разность, тем теснее теоретические значения к эмпирическим данным, качество модели лучше.
Средняя ошибка аппроксимации рассчитывается по следующей формуле:
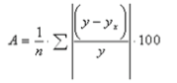
Для качественно построенных моделей, величина этого показателя не должно превышать 10%.