Сравнение средних при неравных дисперсиях

Если мы имеем дело с достаточно объемными выборками X и Y, то распределение статистики t' практически нс отличается от стандартного нормального распределения. В данном случае выборки считаются большими, если число элементов каждой из них оказывается, скажем, больше 30. В этом случае для оценки статистической надежности полученного результата можно воспользоваться таблицами стандартного… Читать ещё >
Сравнение средних при неравных дисперсиях (реферат, курсовая, диплом, контрольная)
Если тест на однородность дисперсий двух выборок X и Y дает отрицательный результат, строго говоря, мы не можем их объединить в качестве общей, совокупной дисперсии — s2pooled — в этом случае оценка однородности двух выборок объемом в n и m наблюдений может предполагать вычисление следующей статистики:
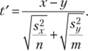
Распределение статистики t' отличается как от нормального распределения, так и от распределения Стьюдента. Вообще говоря, точный характер этого распределения неизвестен и зависит от соотношения дисперсий х и у. Тем не менее существуют способы, позволяющие оценить статистическую значимость результата, рассчитанного таким способом.
Если мы имеем дело с достаточно объемными выборками X и Y, то распределение статистики t' практически нс отличается от стандартного нормального распределения. В данном случае выборки считаются большими, если число элементов каждой из них оказывается, скажем, больше 30. В этом случае для оценки статистической надежности полученного результата можно воспользоваться таблицами стандартного нормального распределения (см. Статистические приложения).
В случае если объемы исследуемых выборок не слишком велики, статистическая надежность t может быть оценена с помощью ?-распределения Стьюдента. Число степеней свободы исследуемой статистики в этом случае может быть задано по формуле.
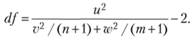
Здесь.
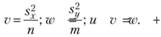
Полученное таким образом значение степеней свободы df округляют до целого значения, просто отбрасывая дробную часть. После этого сравнивают величину статистики t' с квантильными значениями t-распределения, имеющего такое же число степеней свободы.
Если тест Стьюдента проводится с помощью статистических пакетов, таких как IBM SPSS Statistics или STATISTICA, никаких дополнительных расчетов делать не нужно. Все необходимые действия осуществляют сами статистические программы. Как правило, они выдают два значения полученной в итоге статистики: одно соответствует статистике t при условии, что гипотеза об однородности дисперсии принимается, другое рассчитывается для случая, когда эта гипотеза окажется неверной. В обоих вариантах дается также оценка статистической надежности полученного результата.
Сравнение средних в связных выборках. Ранее при сравнении двух выборок мы предполагали, что все данные, используемые в статистическом анализе, получены в серии независимых испытаний. На практике иногда оказывается, что более экономным вариантом мог бы стать вариант, когда обе выборки данных относятся к одним и тем же испытуемым.
Пусть, например, перед нами стоит задача сравнить результаты выполнения однотипных действий испытуемыми в ситуации низкой и высокой тревоги. Вариант решения этой задачи, который уже был рассмотрен выше, очевидно, должен был бы состоять в привлечении двух групп испытуемых, одна из которых выполняла бы интересующие нас действия в ситуации низкой тревоги, а другая — в ситуации высокой тревоги. Более экономный вариант предполагает, что только одна группа испытуемых примет участие в эксперименте, но каждый испытуемый этой группы пройдет через оба экспериментальных условия. Но в этом случае полученные два ряда экспериментальных данных уже не будут статистически независимыми. И, как следствие, процедура оценки статистических гипотез о равенстве средних несколько изменится.
Обозначим результат, который демонстрирует i-й испытуемый в первом условии как ?1i. Структурно этот результат можно выразить следующим уравнением:
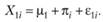
Здесь ?i представляет собой теоретический параметр, отражающий эффект испытуемого i. Остальные параметры этого структурного уравнения оказываются идентичными тем, что были включены в структурное уравнение (2.2).
Аналогичным образом можно представить результат этого же испытуемого во втором условии:
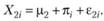
Вычитая результат испытуемого, полученный при одном экспериментальном условии, из результата, полученного при другом условии, мы избавляемся от параметра? i:
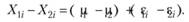
Обозначим это различие как di. Очевидно, что дисперсия статистики di будет определяться не разницей математических ожиданий ?, ведь эта разница оказывается одинаковой для всех испытуемых. Источником дисперсии будут различия между испытуемыми, заданные параметром экспериментальной ошибки? i.
Если величина экспериментальной ошибки, как это предполагает наша структурная модель, оказывается независимой от других параметров, ожидаемое значение этой величины должно быть равно нулю. Тогда ожидаемое значение величины di будет соответствовать разнице математических ожиданий ?1 и ?2. Иными словами, di оказывается несмещенной оценкой искомых различий ?, что можно формально выразить следующим соотношением:
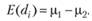
Будем предполагать, что величина d, распределена нормально с параметрами 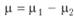 и
и 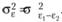 . Тогда оценить статистические различия между двумя рядами данных можно, построив статистику t:
. Тогда оценить статистические различия между двумя рядами данных можно, построив статистику t:
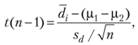 (2.6).
(2.6).
где п — число испытуемых, принявших участие в эксперименте.
Если все сделанные нами допущения оказываются верными, эта статистика описывается распределением Стьюдента с n — 1 степенями свободы. И тогда оценка статистической надежности полученных различий ничем не отличается от того, что нам уже известно на примере анализа статистически независимых рядов данных.