Иерархические алгоритмы, использующие понятие порога

Отметим, что зависимость результатов кластеризации от методов тем сильнее, чем менее явно изучаемая совокупность данных разделяется на группы объектов. Существенное влияние на характеристики кластерной структуры оказывают, во-первых, набор признаков, по которым осуществляется классификация, во-вторых, тип выбранного алгоритма. Например, иерархические и итеративные методы приводят к образованию… Читать ещё >
Иерархические алгоритмы, использующие понятие порога (реферат, курсовая, диплом, контрольная)
Альтернативой кластерным методам являются иерархические алгоритмы, использующие понятие порога. Пороговые алгоритмы эффективны для исходных совокупностей, у которых слабо выражен цепочный эффект и они естественно распадаются на какое-то количество достаточно отдаленных скоплений точек (кластеров).
Общая схема таких алгоритмов отличается от иерархических агломеративных алгоритмов наличием монотонной последовательности порогов С[, С2,Са, (порог Са соответствует максимальному расстоянию между объектами), которые используются следующим образом:
- • на первом шаге попарно объединяются элементы, расстояние между которыми не превышает С{,
- • на втором шаге объединяются элементы (группы элементов), расстояние между которыми не превышает С2;
- • на последнем шаге объединяются все п элементов в один класс.
Наиболее популярными среди таких алгоритмов являются алгоритмы типа FOREL («формальный элемент»). FOREL является примером эвристического дивизимного алгоритма классификации, основанного на идее объединения в один кластер объектов в областях их наибольшего сгущения. Данный термин был предложен Н. Г. Загоруйко, В. Н. Ёлкиной и другими учеными в 1967 г. в Институте математики СО РАН при решении прикладной задачи в области палеонтологии [32]. Таксоны, получаемые этим алгоритмом, имеют сферическую форму. Количество таксонов зависит от радиуса сфер: чем меньше радиус, тем больше получается таксонов.
Рассмотрим алгоритм «Форель-1» .
Цель алгоритма заключается в разбиении наблюдений 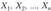 на заранее неизвестное число кластеров так, чтобы сумма расстояний от объектов, входящих в кластер, до центров кластеров была минимальной, но всем кластерам.
на заранее неизвестное число кластеров так, чтобы сумма расстояний от объектов, входящих в кластер, до центров кластеров была минимальной, но всем кластерам.
- 1. На первом шаге находят:
- • вектор средних
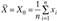 ;
; - • радиус минимальной гиперсферы с центром в точке
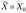 , содержащей все точки исследуемой совокупности. Его можно как задавать из априорных сведений о диаметре кластеров, так и настраивать с помощью процедуры «скользящего контроля» .
, содержащей все точки исследуемой совокупности. Его можно как задавать из априорных сведений о диаметре кластеров, так и настраивать с помощью процедуры «скользящего контроля» .
- • вектор средних
- 2. Задают произвольный радиус Rt < R() (например, равный 0,9Rn) и из любой точки Xj =Х, принятой за центр сферы, радиусом R, описывают гиперсферу Сф Находят центр тяжести Х2 точек совокупности, попавших в гиперсферу С,.
- 3. Из точки Х2 описывают радиусом R2 гиперсферу С2 и определяют Х3 — центр тяжести точек, попавших в гиперсферу С2. Процедура построения гиперсфер и точек повторяется до тех пор, пока центры тяжести точки Хк не перестанут меняться. Точки совокупности, попавшие в стационарную гиперсферу, принимаются за первый класс 5,.
- 4. Для всех оставшихся точек, не попавших в класс St, процедуру повторяют заново и выделяют класс, У2, и т. д. до тех пор, пока все точки совокупности не будут распределены по классам.
Применение алгоритма «Форель-1» позволяет ориентировочно оценить наиболее предпочтительное число классов для совокупности объектов. При этом основанием для выбора числа классов может служить многокрагное повторение одного и того же числа классов для нескольких последовательных значений R(v.
Процедура алгоритма «Форель-1» является сходящейся за конечное число шагов в евклидовом пространстве любой размерности при произвольном расположении точек и любом выборе гиперсферы.
Если начальную точку, в которую переносится центр сферы, на шаге № 2 менять случайным образом, может получиться несколько вариантов кластеризации.
Из нескольких вариантов выбирается тот, на котором достигается минимум функционала качества (либо исходя из профессиональных соображений исследователя).
Алгоритм «Форель-2» является модификацией исходного алгоритма и применяется в тех случаях, когда необходимо разбить совокупность на заданное число классов р. Алгоритм позволяет методом последовательного приближения находить минимальный радиус /?|пш, дающий разбиение на р классов.
Существуют и другие алгоритмы классификации |32]. Так, Р. Боннер описываетметод, похожий на алгоритмы типа FOREL. В этом методе объект, служащий начальной точкой, выбирается случайно. Все объекты, лежащие на расстоянии от начальной точки не больше г, принимаются за первый кластер. Из оставшихся точек снова случайным образом выбирается объект, и процесс повторяется, как и предшествовавший. В результате все точки будут разбиты на группы.
Л. Хиверинен рассматривает процедуру, аналогичную описанной Боннером, но в качестве начального объекта кластеризации выбирает не случайную, а так называемую типическую точку. Для определения типических точек он пользуется статистикой потери информации, причем эти точки лежат на минимальном расстоянии от центра оставшегося множества объектов.
В процедуре, авторами которой являются Ж. Болл и Д. Холл, первоначальные / кластеров формируются случайным отбором / точек, к которым затем присоединяется каждая из оставшихся п — I точек — по минимальному расстоянию к той или иной из них. Затем находятся центры кластеров, и два кластера I и J объединяются, если Оц меньше некоторого порогового значения г. Наоборот, если внутригрупповая дисперсия кластера по некоторой переменной х превосходит пороговое значение S2, то кластер разбивается. Таким образом, дисперсии кластеров SJ, получающихся в результате этой процедуры, ограничены. Вместо центра первоначального кластера рассматриваются центры новых образовавшихся кластеров, и процесс продолжается до тех пор, пока ие сойдется.
Дж. Мак-Куин предлагает метол, аналогичный методу Болла и Холла. Случайным образом отбирается / объектов, которые принимаются в качестве центров кластеризации. Для каждого объекта отыскивается ближайшая точка кластеризации, и если расстояние от выбранного объекта до этой точки не больше заданного уровня г, то объект приписывают к кластеру найденной точки кластеризации. Если это расстояние больше г, то объект образует новый кластер. После этого вычисляются новые центры кластеров. Если расстояние между центрами двух кластеров меньше другого априорно заданного уровня, то соответствующие кластеры объединяются. Процесс продолжается до разбиения всех п объектов на классы.
Метод Г. Себестьена имеет много общего с предыдущим. Однако по Ссбсстьсну объект принадлежит кластеру, если расстояние d до центра кластера меньше г, если же это расстояние больше г (R > г), то этот объект образует новую точку кластеризации. Однако если г < d < R, то объект выбывает из рассмотрения до следующей итерации.
Отметим, что зависимость результатов кластеризации от методов тем сильнее, чем менее явно изучаемая совокупность данных разделяется на группы объектов. Существенное влияние на характеристики кластерной структуры оказывают, во-первых, набор признаков, по которым осуществляется классификация, во-вторых, тип выбранного алгоритма. Например, иерархические и итеративные методы приводят к образованию различного числа кластеров. При этом сами кластеры различаются и по составу, и по степени близости объектов. Выбор меры сходства также влияет на результат разбиения. Если используются методы с эталонными алгоритмами, например метод-средних, то задаваемые начальные условия разбиения в значительной степени определяют конечный результат разбиения.