Регрессионный анализ.
Статистика.
Автоматизация обработки информации

Эта величина характеризует качество регрессионной прямой, то есть степень соответствия между регрессионной моделью и исходными данными. Мера определенности всегда лежит в диапазоне от 0 до 1. Существование ненулевых коэффициентов регрессии проверяется посредством вычисления контрольной величины F (см. среднюю часть таблицы), к которой относится соответствующий уровень значимости. Следует… Читать ещё >
Регрессионный анализ. Статистика. Автоматизация обработки информации (реферат, курсовая, диплом, контрольная)
Если расчет корреляции характеризует силу связи между двумя переменными, то регрессионный анализ служит для определения вида этой связи и дает возможность для прогнозирования значения одной (зависимой) переменной отталкиваясь от значения другой (независимой) переменной.
Следует отметить, что принципиальных отличий между простым анализом (одна независимая переменная) и множественным анализом (несколько независимых переменных) нет, однако линейная регрессия является простейшей и применяется чаше всех остальных видов. Этот вид регрессии лучше всего подходит для того, чтобы продемонстрировать принципы регрессионного анализа.
Линейная связь переменных может быть выражена уравнением:
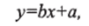
где b — регрессионный коэффициент, — смещение по оси координат.
Смещение по оси координат соответствует точке на оси у (вертикальной оси), где прямая регрессии пересекает эту ось. Коэффициент регрессии Ъ через соотношение b=tg (a) указывает на угол наклона прямой.
При проведении простой линейной регрессии основной задачей является определение параметров b и а. Оптимальным решением этой задачи является такая прямая, для которой сумма квадратов вертикальных расстояний доя отдельных точек данных является минимальной.
Рассмотрим пример из раздела 4.2 «Вычисление статистических характеристик» по определению зависимости показателя холестерина спустя один месяц после начала лечения от исходного показателя (файл hyper.sav).
В данном примере примем показатель холестерина через один месяц после начала лечения (переменная choll) как зависимую переменную (у), а исходную величину как независимую переменную (х). Тогда для проведения регрессионного анализа нужно будет определить параметры соотношения.
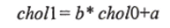
После определения этих параметров, зная исходный показатель холестерина, можно спрогнозировать показатель, который будет холестерина.
Расчет уравнения регрессии
• Откройте файл hyper.sav и выполните команды меню Analyze (Анализ) — Regression (Регрессия) — Linear (Линейная), (рис. 64).
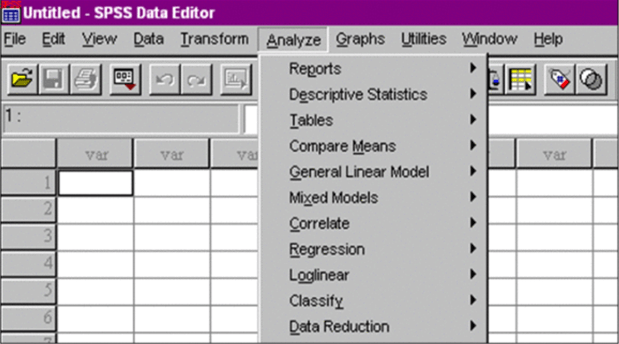
Рис. 64. Фрагмент экрана SPSS для вызова регрессионного анализа.
Появится диалоговое окно Linear Regression (Линейная регрессия) (рис. 65).
• Перенесите переменную choll в поле для зависимых переменных и присвойте переменной choR статус независимой переменной.
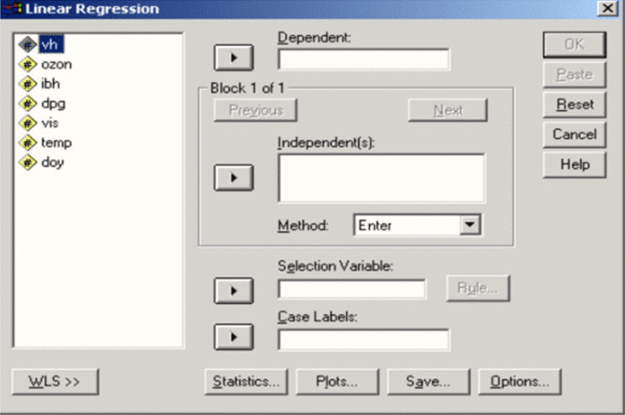
Рис. 65. Диалоговое окно Линейная регрессия.
• Выполните расчет нажатием кнопки ОК.
В окне просмотра появятся результаты вычислений. Фрагмент экрана в виде табличных форм представлены на рис. 66.
Рассмотрим результаты, представленные в третьей таблице Coefficients (Коэффициенты). Здесь выводятся коэффициент регрессии b и смещение по оси ординат а под именем «константа». То есть, уравнение регрессии выглядит следующим образом:
chol =0,863* сАо/0+34,546.
Если значение исходного показателя холестерина составляет, например, 280, то через один месяц можно ожидать показатель равный 276.
Частные рассчитанных коэффициентов и их стандартная ошибка дают контрольную величину Т соответственный уровень значимости относится к существованию ненулевых коэффициентов регрессии.
Средняя часть расчетов отражает два источника дисперсии: дисперсию, которая описывается уравнением регрессии (сумма квадратов, обусловленная регрессией) и дисперсию, которая не учитывается при записи уравнения (остаточная сумма квадратов).
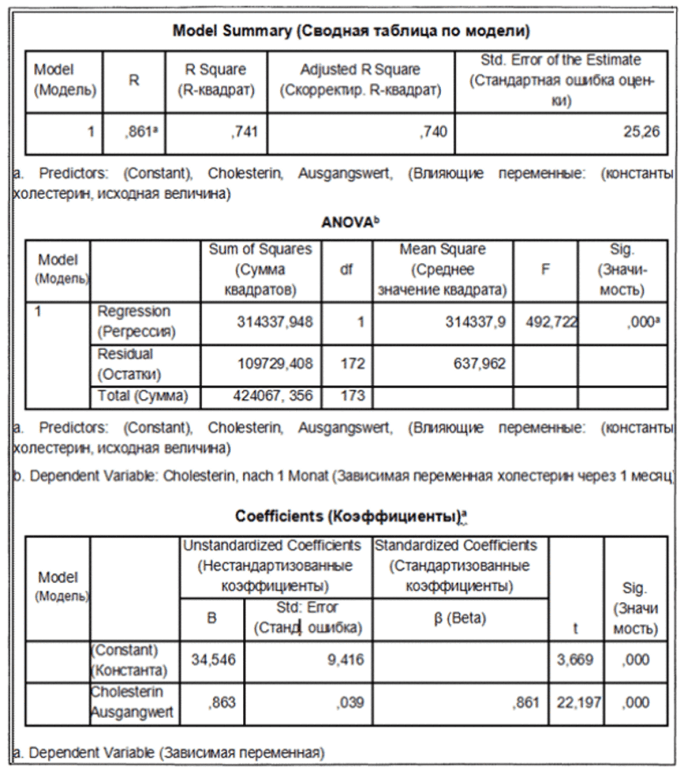
Рис. 66. Фрагмент экрана SPSS с результатами вычислений регрессионного анализа.
Частное от суммы квадратов, обусловленных регрессией, и остаточной суммы квадратов называется коэффициентом детерминации. В таблице результатов (Model Summary) это частное выводится под именем «R-квадрат». В нашем примере мера определенности равна:
314 337,948 / 424 067,356 = 0,741
Эта величина характеризует качество регрессионной прямой, то есть степень соответствия между регрессионной моделью и исходными данными. Мера определенности всегда лежит в диапазоне от 0 до 1. Существование ненулевых коэффициентов регрессии проверяется посредством вычисления контрольной величины F (см. среднюю часть таблицы), к которой относится соответствующий уровень значимости.
В простом линейном регрессионном анализе квадратный корень из коэффициента детерминации, обозначаемый /?, равен корреляционному коэффициенту Пирсона. При множественном анализе эта величина менее наглядна, чем сам коэффициент детерминации. Величина «Смещенный R-квадрат» всегда меньше, чем несмещенный. При наличии большого количества независимых переменных мера определенности корректируется в сторону уменьшения.
Принципиальный вопрос о том, может ли вообще имеющаяся связь между переменными рассматриваться как линейная, проще и нагляднее всего решать, глядя на соответствующую диаграмму рассеяния. Кроме того, в пользу гипотезы о линейной связи говорит также высокий уровень дисперсии, описываемой уравнением регрессии.