Введение в многомерную статистику: кластер-анализ

Кластер представляет собой группу близких объектов в многомерном (в общем случае) пространстве. Кластер-анализ представляет собой набор алгоритмов разбиения совокупности объектов на кластеры. Такая операция называется кластеризацией. Обратите внимание на отличие кластеризации от классификации. В последнем случае мы также разбиваем объекты на несколько групп. Но содержательное основание такого… Читать ещё >
Введение в многомерную статистику: кластер-анализ (реферат, курсовая, диплом, контрольная)
До сих пор в фокусе нашего внимания находились статистические связи между переменными: мы выясняли, как одна или несколько независимых переменных влияют на зависимый признак. Однако существует и другой важный класс задач, связанных с выявлением пространственной структуры данных. Эти задачи решаются с помощью многомерных статистических методов, которые также называют пространственно-статистическими.
Основные принципы кластер-анализа
Еще в начале курса мы договорились, что структура — это совокупность отношений между объектами (глава 2). Когда мы говорим о пространстве, речь идет об одном определенном классе отношений — о расстояниях. Способ измерения расстояния между объектами в математике называется метрической функцией или метрикой.
Немного формальных определений (они пригодятся нам для того, чтобы суметь отличить расстояние от других отношений). Расстоянием (метрикой) р между точками А и В, принадлежащими одному и тому же множеству X (Ае Х, ВеХ), является такая вещественная числовая функция, которая удовлетворяет следующим условиям:
- 1) р (А, В) > 0. Расстояние неотрицательно.
- 2) р (А, В) = 0 тогда и только тогда, когда А = В. Расстояние равно нулю тогда и только тогда, когда А и В тождественны между собой, т. е. представляют один и тот же элемент множества X.
- 3) р (А, В) = р (В, А). Расстояние от А до В равно расстоянию от В до А.
- 4) р (А, В) + р (В, Q > р (А, С). Сумма расстояний от А до В и от В до С всегда больше или равна расстоянию от А до С.
Является ли метрикой, например, коэффициент корреляции? Нет, не является, поскольку не выполняются как минимум первые две аксиомы. Расстояние неотрицательно, а коэффициент корреляции может принимать отрицательные значения. Кроме того, в соответствии со второй аксиомой расстояние между тождественными объектами равно нулю, тогда как корреляция между идентичными переменными равна единице. При этом коэффициент корреляции может быть превращен в метрику — до смешного простым способом, который мы покажем ниже.
Таблица //. I
X | У | Z | |
А | |||
В | |||
С | — 1. | — 2. | — 3. |
Наиболее простой и широко распространенной метрической функцией является изучаемое уже в школьном курсе математики евклидово расстояние. Пусть даны три точки А, В, С со следующими координатами (см. табл. 11.1).
В евклидовой метрике расстояние между любой парой точек (например, А и В) будет рассчитываться по формуле.
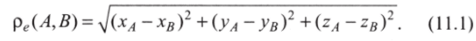
Для имеющихся данных это расстояние составит:
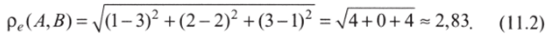
Легко убедиться, что евклидово расстояние соответствует всем аксиомам метрической функции.
Итак, формально пространство понимается как множество с определенной на нем метрической функцией. Проше говоря, массив данных превращается в пространство, как только мы решили, каким образом измерять расстояния между объектами. Что имеется в виду под «объектами»? Рассмотрим данные уже привычного вида, в которых зафиксированы результаты парламентских выборов 2011 г. в нескольких российских регионах (см. табл. 11.2).
Первое естественное предположение состоит в том, что объектами пространственного анализа являются регионы. С точки зрения многомерного анализа, в нашем примере каждый регион представляет собой точку с семью координатами — по числу политических партий. Определив способ.
Справедливая Россия. | ЛДПР. | Патриоты России. | КПРФ. | Яблоко. | Единая Россия. | Правое дело. | |
Астраханская область. | 14,6. | 8,3. | 0,7. | 13,3. | 1,0. | 60,2. | 0,3. |
Республика Башкортостан. | 5,5. | 5,2. | 0,5. | 15,6. | 1,2. | 70,5. | 0,4. |
Республика Дагестан. | 0,2. | 0,0. | 0,1. | 7,9. | 0,0. | 91,4. | 0,1. |
Ивановская область. | 15,6. | 14,8. | 1,2. | 22,5. | 3,5. | 40,1. | 0,8. |
Липецкая область. | 16,7. | 14,4. | 1,0. | 22,9. | 2,5. | 40,1. | 0,5. |
Республика Мордовия. | 1,3. | 1,5. | 0,1. | 4,5. | 0,3. | 91,6. | 0.1. |
г. Москва. | 12.1. | 9,4. | 1,3. | 19,4. | 8,6. | 46,6. | 0,8. |
Мурманская область. | 19,7. | 18,1. | 1,2. | 21,8. | 4,8. | 32,0. | 0,6. |
г. Санкт-Петербург. | 23,7. | 10,3. | 1,2. | 15,3. | 11,6. | 35,4. | 0,9. |
Республика Северная Осетия. | 6,0. | 2,2. | 0,4. | 21,7. | 0,3. | 67,9. | 0,3. |
Республика Татарстан. | 5,3. | 3,5. | 0,4. | 10,6. | 1.1. | 77,8. | 0,4. |
Ямало-Ненецкий АО. | 4.7. | 13,6. | 0.7. | 6,6. | 1,2. | 71,7. | 0,4. |
Ярославская область. | 22,6. | 15,5. | 1,8. | 24,0. | 4,8. | 29,0. | 0,7. |
измерения расстояния между этими точками, мы получим регионы в пространстве политических партий. Политические партии становятся координатными осями — аналогами обычных OX, OY и OZ, только теперь их существенно больше (именно поэтому такое пространство и является многомерным). Рассчитав расстояния между регионами, мы поймем, какие из них близки друг к другу в электоральном пространстве рассматриваемых выборов, какие — удалены на большие дистанции.
Однако с таким же успехом мы можем рассматривать и политические партии в качестве объектов, а регионы — в качестве пространственных измерений. В этом случае табл. 11.2 будет представлять политические партии в пространстве регионов, и мы сможем определить близость (удаленность) партий друг от друга в этом пространстве.
В целом, пространственной статистике свойственно предположение, что геометрическая близость двух или нескольких точек в этом пространстве означает близость «физических» (или «политических») состояний соответствующих объектов, их однородность. Аналогичным образом удаленность точек интерпретируется как их несхожесть, неоднородность.
Кластер представляет собой группу близких объектов в многомерном (в общем случае) пространстве. Кластер-анализ представляет собой набор алгоритмов разбиения совокупности объектов на кластеры. Такая операция называется кластеризацией. Обратите внимание на отличие кластеризации от классификации. В последнем случае мы также разбиваем объекты на несколько групп. Но содержательное основание такого разбиения при классификации известно нам заранее, а при кластеризации — нет. Лишь получив разбиение, основанное исключительно на расстояниях между объектами в многомерном пространстве, мы пытаемся ответить на вопрос: а почему именно эти объекты вошли в один кластер? Другими словами, в классификации выделение группирующих признаков предшествует работе с эмпирическими данными, а в кластеризации — наоборот.
Кластер-анализ — одно из наиболее мощных средств компактного описания и анализа пространственных отношений в больших массивах данных. К примеру, в парламентских выборах 17 декабря 1995 г. приняли участие 43 избирательных объединения, выборы проводились во всех 89 регионах России. Наша задача — разбить субъекты Федерации на несколько групп по признаку близости политических предпочтений избирателей, выявленных в ходе голосования за избирательные объединения и блоки. Исходные данные в этом случае составят таблицу с 89 столбцами и 43 строками, всего 3287 (43×89) наблюдений. Даже если мы проведем предварительное «сжатие» данных с помощью группировки или типологизации, — к примеру, объединим партии в несколько идеологически близких групп, — все равно решить поставленную задачу будет чрезвычайно трудно. Если, конечно, не применять кластер-анализ, который как раз и предназначен для решения подобного рода проблем.
Другим примером задачи, решаемой с помощью кластеранализа, является выделение стран мира, сходных по показателям социально-экономического развития: и стран, и показателей десятки и даже сотни. В целом, этот метод может помочь всегда, когда имеется набор объектов в многомерном пространстве, которые нужно упорядочить по признакам сходства или различия.
Как было отмечено выше, кластер-анализ объединяет несколько различных алгоритмов классификации. Наиболее распространены три алгоритма: иерархический кластеранализ (tree clustering, hierarchical clustering), метод A-средних (К-means) и двухходовое объединение (two-way joining). Мы рассмотрим первые два алгоритма, как более активно используемые в политическом анализе.