Цифровое кодирование речевых сигналов с низкой скоростью
Анализ аппарата формирования речевого сигнала и способов его описания указывает на некий общий алгоритм анализа и синтеза. На интервале длины 7″, на котором параметры генератора возбуждения и резонансной системы можно считать постоянными, производится анализ реализации с целью определения параметров сигнала возбуждения и резонансной системы. Информация об указанных параметрах (обычно в дискретной… Читать ещё >
Цифровое кодирование речевых сигналов с низкой скоростью (реферат, курсовая, диплом, контрольная)
Для рассмотренных алгоритмов АЦП требуется значительно большая полоса передачи ДРЦ, чем полоса преобразуемых аналоговых сигналов ДРА. При ИКМ-преобразовании речевых сигналов цифровой поток имеет скорость 56—64 кбит/с. Методы разностного квантования позволяют снизить эту скорость в 2—3 раза. Однако в обоих случаях ДРп много больше Д^А.
В то же время нижняя оценка информативности речевого источника лежит в диапазоне 10—50 бит/с и определяется энтропией печатного текста, который человек зачитывает по телефону. Информацию из текста можно передать по низкоскоростному телеграфному каналу даже быстрее. Принципиальная разница между телефонной и телеграфной передачами в том, что в первом случае узнают содержание высказывания и распознают собеседника по голосу, а во втором — получают обезличенный текст. Таким образом, информационная производительность речевого источника находится в пределах 10—64 000 бит/с. Естественно стремление приблизиться к нижней границе за счет обезличивания передаваемой информации.
Речевой сигнал (PC) как процесс, протекающий во времени, характеризуется рядом параметров, которые также являются функциями времени и изменяются значительно медленнее, чем процесс в целом. Если каналу связи передавать не сам речевой сигнал, а информацию о его параметрах, то потребуется канал связи с меньшей пропускной способностью.
Для PC в виде совокупности медленно изменяющихся параметров говорят о параметрической компрессии PC. Такой сигнал при непосредственном воспроизведении неразборчив. Восстановление разборчивости PC сигнала по его параметрам называют параметрическим экспандированием. Использование на линии связи параметрической компрессии и экспандирования называют параметрическим компандированием речевого сигнала. На базе параметрического компандирования строятся вокодеры (voice coder).
Устройство выделения и изменения параметров PC называют анализатором вокодера. Анализатор является составной частью передающего устройства вокодерной системы. Устройство восстановления PC по значениям его параметров называют синтезатором вокодера. Синтезатор является составной частью приемного устройства вокодерной системы. Методы анализа и синтеза речевого си шала определяют тип вокодера.
На основе анализа строения речевого аппарата (см. параграф 23.1) электрический речевой сигнал представим как результат воздействия напряжения генератора возбуждения на электрическую резонансную систему.
Генератор возбуждения при передаче вокализованных звуков генерирует импульсы с частотой следования, определяемой произносимым звуком. Эта частота называется частотой основного тона. В случае невокализованных звуков генератор возбуждения генерирует шумовой сигнал с равномерным в полосе звуковых частот спектром.
Таким образом, параметрическое описание источника сигнала включает вид источника возбуждения (тон или шум), частоту основного тона (для вокализованного сигнала) и параметры резонансной системы.
Анализ аппарата формирования речевого сигнала и способов его описания указывает на некий общий алгоритм анализа и синтеза. На интервале длины 7″, на котором параметры генератора возбуждения и резонансной системы можно считать постоянными, производится анализ реализации с целью определения параметров сигнала возбуждения и резонансной системы. Информация об указанных параметрах (обычно в дискретной форме) передается по каналу связи. На приеме после оценки принятой информации синтезируются генератор возбуждения и резонансная система, воспроизводящие реализацию сигнала длительностью Т.
Различные системы вокодеров чаще всего используют однотипное представление сигналов возбуждения, различаясь лишь описанием параметров резонансной системы, которое может иметь вид либо импульсной, либо амплитудно-частотной характеристики.
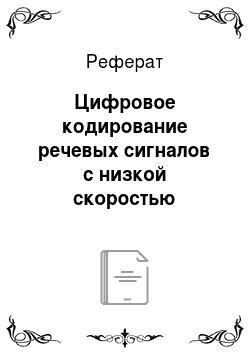
Полосный вокодер строится на базе спектрального построения речевого сигнала. Огибающая спектра речи определяется характеристикой фильтра, образованного голосовым трактом. Информация о резонансной системе получается путем анализа спектра амплитуд для ограниченной реализации (амплитуда БПФ). Примерная структурная схема анализатора полосного вокодера представлена на рис. 23.23.
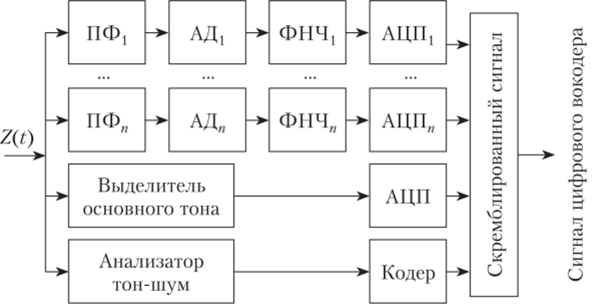
Рис. 23.23. Примерная структурная схема анализатора полосного вокодера.
Гребенка N полосовых фильтров (ПФ) с амплитудными детекторами (АД) представляет собой анализатор спектра параллельного типа с полосой анализа, равной полосе частот, которую занимает речевой сигнал.
Уровни на выходах АД зависят от коэффициента передачи резонансной системы речевого тракта в полосах частот, соответствующих полосам пропускания ПФ. Таким образом, совокупность напряжения на выходах АД моделирует амплитудно-частотную характеристику резонансной системы голосового тракта, как это показано на рис. 23.24. Фильтры нижних частот (ФНЧ) предназначены для фильтрации огибающих на выходах АД. Полосы пропускания ФНЧ обусловлены скоростью изменения огибающих на выходах АД, т. е. скоростью изменения амплитудно-частотной характеристики голосового тракта. Выходные уровни АД подвергаются АЦП. Выделитель основного тона изменяет его величину, которая также подвергается операции АЦП. Анализатор тон-шум устанавливает вид источника возбуждения. На выходах всех каналов анализатора формируются низкоскоростные цифровые потоки, которые объединяются мультиплексором в один более высокоскоростной цифровой поток. В мультиплексоре в суммарный поток вводятся элементы цифровой синхронизации. Таким образом, суммарный сигнал дискретного вокодера содержит кодированную информацию о характеристиках резонансной системы голосового тракта, виде и параметрах источника возбуждения.
Оценим количественные характеристики анализатора полосного вокодера. Анализатор частотной характеристики обычно содержит 10—16 частотных каналов. Полосы пропускания ПФ в области нижних частот речевого сигнала выбирают около 125 Гц, в области верхних частот — около 400 Гц, чтобы они перекрывали основной спектр речевого сигнала (300—2400 Гц). Полосы пропускания всех ФНЧ выбирают одинаковыми, равными 25 Гц. Следовательно, частота дискретизации в АЦП составляет 50 Гц. Квантование огибающих на выходных канальных анализаторов осуществляется на восемь или 16 уровней, используются 3- или 4-элементные коды. Для передачи информации о величине основного тона требуются 5-, 6-элементные коды и повышенная частота дискретизации.
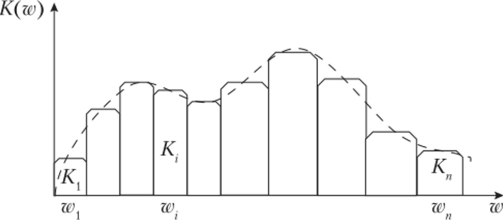
Рис. 23.24. Амплитудно-частотная характеристика резонансной системы голосового тракта Скорость работы полосных вокодеров обычно 1200—9600 бит/с, где около 600 бит/с — информация об основном тоне и типе возбуждения, остальные — для канальных сигналов.
Схема синтезатора полосного вокодера дана на рис. 23.25. Цифровой поток, поступающий на синтезатор полосного вокодера, на демультиплексоре разделяется на потоки, описывающие параметры речевого сигнала. Сигнал с выхода декодера тон-шум через ключевую схему подключает к частотным каналам синтезатора либо генератор импульсов (вокализованный звук), либо генератор шума (невокализованный звук). Декодер основного тона устанавливает частоту генератора импульсов. Декодированные сигналы с выходов ЦАП управляют уровнями сигналов возбуждения на выходах ПФ, аналогичных ПФ анализатора. Речевой сигнал синтезируется в сумматоре, подключенном к выходам ПФ.
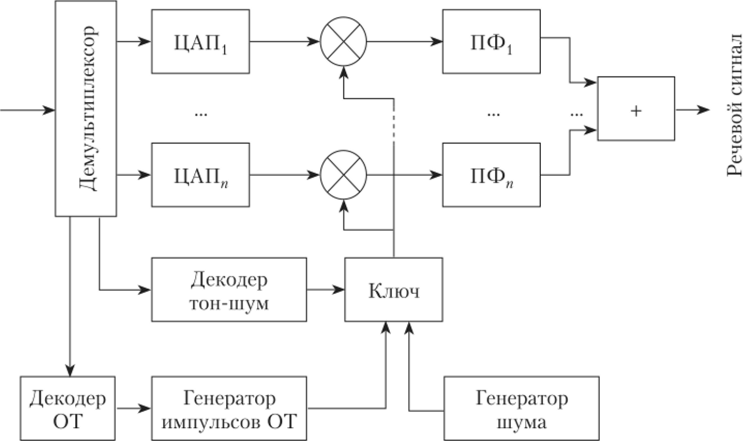
Рис. 23.25. Синтезатор полосного вокодера.
Форматный вокодер определяет положение и амплитуду спектральных пиков (формант) и передает эту информацию вместо огибающей всего спектра, т. е. формирует цифровой сигнал с пониженной скоростью передачи. Важнейшим требованием для получения разборчивой речи при использовании формантного вокодера является точное прослеживание изменений в формантах. Если это выполняется, формантный вокодер обеспечивает разборчивую речь при скорости передачи менее 1000 бит/с.
Вокодер с линейным предсказанием (ВЛП) извлекает нужные характеристики РС из временной формы сигнала, а не из частотного спектра, как в полосном и формантном вокодерах. Синтезатор на приеме воссоздает РС путем пропускания возбуждающего сигнала через модель речеобразующего тракта, аналитическое выражение следующее:

где 5, — г-е значение синтезированного РС на выходе модели; h? — г-е значение возбуждающей функции; а, — коэффициенты предсказания; К — коэффициент усиления; р — порядок модели, учитывающей глубину корреляции между отсчетами РС.
Важно, что модель (23.5) допускает предсказание значения 5, по линейной комбинации предыдущих отсчетов 5,-_у. На передаче задача анализа — определение коэффициентов предсказания ау Кроме того, определяется и передается для синтезатора информация о характере возбуждения (гласные, звонкие согласные или глухие звуки), о периоде основного тона, о коэффициенте усиления, о коэффициентах предсказания (параметрах модели речеобразующего тракта). Цифровой поток на выходе ВЛП имеет скорость 1,2—2,4 кбит/с.