Вероятностная модель.
Исследование параметров сегментации при статистическом машинном переводе с арабского на русский язык

Также, иногда при построении модели перестановок бывает полезно прибегнуть к некоторым дополнительным приемам. К примеру, многие фразы могут сигнализировать не только то, что их нужно переставить, но и необходимость перестановки следующей за ними фразы. В таком случае нужно дополнительно построить модель перестановок для последующих фраз. Кроме того, время от времени имеет смысл учитывать… Читать ещё >
Вероятностная модель. Исследование параметров сегментации при статистическом машинном переводе с арабского на русский язык (реферат, курсовая, диплом, контрольная)
Согласно правилу Байеса, наилучший перевод ebest для фразы f можно рассчитать следующим образом:
ebest = argmaxe p (e|f) = argmaxe p (f|e) plm (e).
Здесь, p (f|e) — это модель перевода, а plm (e) — языковая модель.
При этом, модель перевода можно представить как.
p (fI1|eI1) = ПIi=1ц (fi|ei) d (starti? endi?1? 1),.
где ц — вероятность перевода, а d — вероятность перестановки.
Модель перестановок
Перестановки слов являются важной частью статистического машинного перевода. Действительно, порядок слов существенно различается во многих языках, особенно если речь идет о языках из разных семей.
Часто проблема отличающегося порядка слов решается с помощью такого инструмента, как языковая модель. Это справедливо для случаев, в которых расстояние между словами, которые нужно переставить, не слишком велико. Чаще всего языковые модели строятся на основе триграмм, так что такие перестановки могут происходить в пределах окна из трех слов. Например, при переводе французского выражения affaires extйrieures на английский в языковой модели будет содержаться external affairs намного чаще, чем affairs external (вероятнее всего, такой фразы не будет вообще), поэтому external и affairs будут переставлены местами. К сожалению, такое рассуждение не будет справедливо для языков с порядком слов SOV (существительное — дополнение — сказуемое), таких как турецкий. Из-за того, что сказуемое будет стоять в конце предложения, расстояние между сказуемым в переводе без перестановок и в правильном с точки зрения целевого языка переводе в таких случаях может существенно отличаться. Вследствие этого, нужно использовать модель перестановок. (В то время как для языковой французский-английский можно использовать так называемый «монотонный перевод» — перевод без специальной модели перестановок). Чаще всего, имеет смысл ограничить расстояние возможных перестановок окном из некоторого количества слов. У такого шага есть две цели. Во-первых, таким образом можно сократить время, расходуемое на вычисление вероятностей для всех возможных вариантов. Кроме того, слишком большое окно перестановок может приводить к ухудшению результатов перевода.
Лексикализованная модешль перестановок позволяет вычислить вероятность того, что пара фраз на целевом и исходном языке имеет монотонный, обратный или раздельный тип ориентации. Ориентация называется монотонной (monotone), если в матрице выравниваний существует соответствие между словами исходного и целевого языка левее и выше фразы. Обратной (swap) ориентацию называют, если соответствие между словами двух языков расположено правее и выше фразы. При этом, соответстия должны примыкать к углу той части матрицы, которая отражает рассматриваемую фразу. Тип ориентации считают прерывным (discontinious), если ни к левому верхнему, ни к правому верхнему углу фразы не примыкает никаких соответствий между словами исходного и целевого языков.
Рассчитаем вероятность того или иного типа ориентации для данной пары фраз. Пусть p0(orientation|f, e) — вероятность ориентации фразовой пары (f, e). Согласно принципу максимального правдоподобия, ее можно вычислить следующим образом:
p0(orientation|f, e) =.
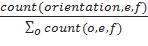
Стоит отметить, что из-за разреженности данных в при создании модели перестановок возникет проблема сглаживания. Для того, чтобы решить ее, мы можем использовать распределение безусловной вероятности максимального правдоподобия с каким-либо множителем d.
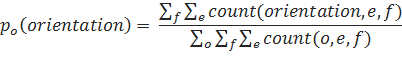

Также, иногда при построении модели перестановок бывает полезно прибегнуть к некоторым дополнительным приемам. К примеру, многие фразы могут сигнализировать не только то, что их нужно переставить, но и необходимость перестановки следующей за ними фразы. В таком случае нужно дополнительно построить модель перестановок для последующих фраз.
Кроме того, время от времени имеет смысл учитывать распределение ориентации лишь на фразах исходного языка (или только целевого). Это может помочь в борьбе с недостаточностью данных. Вдобавок к этому, можно объединить обратный и прерывный типы ориентации с тем, чтобы еще сильнее снизить сложность используемой модели перестановок.