Способы построения выборки
При построении выборки с возвращением, после того как единица была отобрана из списка, используемого в качестве основы выборки, она по-прежнему остается в списке и может быть отобрана вновь с той же вероятностью, что и любая другая. В большинстве случаев вероятность повторного отбора крайне мала, но если такое случится, эта единица отбора должна учитываться в расчетах дважды. При построении… Читать ещё >
Способы построения выборки (реферат, курсовая, диплом, контрольная)
Способы построения выборки принято классифицировать по трем основаниям. Они делятся:
- 1) на байесовские (Bayesian) и традиционные;
- 2) с возвращением (replacement) и без возвращения;
- 3) вероятностные и невероятностные.
При байесовском подходе данные обрабатываются после опроса каждого респондента, так что выборочные статистики становятся точнее с каждым новым интервью. При этом фиксируются затраты на опрос и решается задача минимизации математического ожидания потерь, которые могут возникнуть, если решение, принятое по его результатам, окажется ошибочным. Минимум указанной величины достигается путем включения в выборку респондентов такого типа, информация о которых в наибольшей степени снижает вероятность принятия ошибочного решения. Теоретически этот подход очень привлекателен. Однако он сложен организационно и неприменим, когда цена ошибки неизвестна.
При традиционном подходе отбор всех элементов выборки выполняется до начала сбора данных. Поскольку этот подход применяется в подавляющем большинстве случаев, будем исходить из того, что используется именно он.
При построении выборки с возвращением, после того как единица была отобрана из списка, используемого в качестве основы выборки, она по-прежнему остается в списке и может быть отобрана вновь с той же вероятностью, что и любая другая. В большинстве случаев вероятность повторного отбора крайне мала, но если такое случится, эта единица отбора должна учитываться в расчетах дважды. При построении выборки без возвращения такая ситуация невозможна. В зависимости от выбранного подхода выборочные статистики рассчитываются по-разному. Однако численно эти различия очень малы и становятся заметными, лишь когда размер исследуемой совокупности сопоставим с размером выборки. Поэтому мы будем пользоваться более простыми статистиками, полученными для случая, когда выборка строится с возвращением.
Наиболее важное решение — это выбор между вероятностными и невероятностными способами построения выборки. Об этих способах мы поговорим несколько позднее.
Определение необходимого размера выборки
Под размером выборки подразумевается число элементов, которые должны быть в нее включены.
Необходимый размер выборки зависит от ряда качественных и количественных факторов. Начнем с качественных факторов.
1. Чем важнее решение, тем больше информации нужно для его обоснования и тем точнее она должна быть.
Соответственно нужна большая выборка. Однако каждая дополнительная единица повышения точности требует все больше затрат. Случайная ошибка выборки уменьшается обратно пропорционально корню квадратному из числа элементов в выборке. Чтобы снизить ее вдвое, нужно увеличить выборку в четыре раза. Допустим, при выборке объемом 100 респондентов среднеквадратическое или, по-другому стандартное отклонение оценки среднего составит 4 единицы. Если учетверить выборку, добавив еще 300 респондентов, стандартное отклонение оценки уменьшится вдвое и составит 2 единицы. Чтобы уменьшить стандартное отклонение еще вдвое, понадобится вновь учетверить выборку, т. е. добавить в нее уже не 300, а 1200 респондентов. Мы видим, что чем больше выборка, тем меньше выигрыш в точности от добавления в нее каждого следующего респондента.
- 2. На размере выборки сказывается природа исследования. Для поисковых исследований качественными методами размер выборки обычно мал. Для описательных и причинных исследований требуются значительные по объему выборки.
- 3. Если предполагается использовать тонкие методы анализа, выборка должна быть больше. То же относится к ситуации, когда нужно получить оценки не только для всех элементов выборки в целом, но и для отдельных подгрупп элементов (например, для представителей разных сегментов рынка).
- 4. Необходимый размер выборки можно приблизительно оценить, зная, в каких пределах он обычно находится в аналогичных исследованиях (табл. 9.1).
Таблица 9.1. Минимальный и типичный размеры выборки при разных исследованиях
Задачи исследования | Минимальный размер выборки | Типичный размер выборки |
Выявление проблем (например, оценка потенциала рынка). | 1000−2500. | |
Решение проблем (например, относительно цены товара). | 300−500. | |
Тестирование товара. | 300−500. | |
Тестирование рекламы. | 200−300. |
5. Размер выборки определяется финансовыми и временными ресурсами, а также численностью квалифицированного персонала для сбора данных. Выбор размера выборки зависит и от того, как часто можно встретить нужных респондентов, а также от предполагаемой доли завершенных интервью (completion rate). Более подробно об этом говорится в следующем разделе.
Рассмотрим теперь количественные факторы. Приводимые ниже формулы вытекают из соответствующих формул для расчета ошибки выборки описательных исследований (см. с. 182). Мы будем поочередно рассматривать два типа ситуаций.
- 1. Требуется оценить среднее значение некоторой маркетинговой характеристики по всем представителям исследовательской совокупности.
- 2. Требуется оценить долю представителей исследуемой совокупности, которые дали бы определенный ответ на некоторый вопрос (например, высказали бы склонность к приобретению интересующего нас товара).
Начнем с первой ситуации.
Пример 9.2.
Оценка среднего
Пусть, например, надо оценить, сколько в среднем пива выпивает за месяц один житель России. Обычно говорят, что нам надо определить эту величину с определенной случайной погрешностью, например, отклониться от истины не более чем на ±0,1 литр.
Но что означает это требование? Ведь не исключено, что при случайном отборе в выборку попадут только совершенно не пьющие пиво люди. Обратим внимание, однако, что вероятность такого «ужасного» с точки зрения точности замера случая чрезвычайно мала. Итак, пусть мы хотим измерить искомую величину так, чтобы отклонения от истинного значения на 0,1 литр и более встречались не чаще, чем в пяти выборках из ста. Иначе говоря, чтобы случайная погрешность не превышала ±0,1 литр с доверительной вероятностью 0,95.
Для определения необходимого размера выборки нужно представлять хотя бы приблизительно, насколько различается типичное количество выпиваемого за месяц пива у разных людей. Характеристикой такого рода различий служит, как известно, величина среднеквадратического отклонения (?). До проведения опроса мы, понятно, не можем рассчитать эту величину. Обычно ее оценивают по данным ранее проведенных аналогичных исследований.
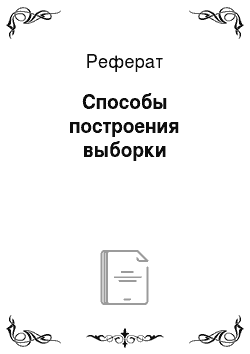
Размер выборки, необходимый для оценки средней величины, определяется по формуле.
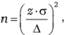 (9.1).
(9.1).
где? — величина допустимой случайной погрешности (в нашем примере 0,1 литра); z — значение границы доверительного интервала, соответствующее выбранному уровню доверительной вероятности (в нашем примере при доверительной вероятности 0,95 эта величина равна 1,96, т. е. приблизительно 2);? — стандартное отклонение показателя, среднее значение которого требуется определить.
Предположим, в нашем примере? = 2 литра. Тогда выборка должна состоять не менее чем из 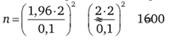 респондентов.
респондентов.
Перейдем теперь к рассмотрению второй ситуации: когда нужно оценить долю жителей страны, определенным образом ответивших на некоторый вопрос анкеты, если бы он был им всем задан. Формула для этого случая имеет вид:
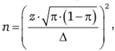 (9.2).
(9.2).
где? — величина погрешности в долях единицы, которую решено считать допустимой; z — значение границы доверительного интервала, соответствующее выбранному уровню доверительной вероятности (в данном примере, как и в предыдущем, эта величина равна 1,96, т. е. приблизительно 2);? — предположительная доля представителей исследуемой совокупности, которые ответили бы на данный вопрос интересующим нас образом.
Пример 9.3.
Оценка доли
Пусть нам нужно определить долю жителей страны, которые, если бы к ним обратились с вопросом о некотором товаре, выразили бы намерение его приобрести. Пусть нас устроит, если данные выборки будут с доверительной вероятностью 95% отклоняться от этой доли не более чем на 2%. Пусть мы уверены, что доля лиц, высказывающих интересующее нас намерение, не может превышать 0,1. Тогда выборка должна состоять не менее чем из 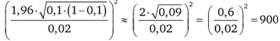 респондентов.
респондентов.
Приведенные выше формулы 9.1 и 9.2 получены для случая, когда размер выборки пренебрежимо мал по сравнению с размером исследуемой совокупности. Если же они соизмеримы (например, различаются не более чем в 10 раз), та же самая точность достигается при меньшем размере выборки nс, который можно рассчитать по формуле.
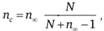 (9.3).
(9.3).
где  — размер выборки, рассчитанный по приведенным выше формулам для бесконечной исследуемой совокупности; nс — размер выборки, учитывающий конечность исследуемой совокупности; N — размер исследуемой совокупности.
— размер выборки, рассчитанный по приведенным выше формулам для бесконечной исследуемой совокупности; nс — размер выборки, учитывающий конечность исследуемой совокупности; N — размер исследуемой совокупности.
В заключение отметим, что все приведенные выше формулы базируются на предположении, что выборка строится методом простого случайного отбора, описываемого ниже (см. с. 308). Если же это не так, например, если выборка составляется из определенного числа групп респондентов, проживающих близко друг от друга, погрешность может оказаться выше той, из которой мы исходили. Представим себе, например, что при определении дохода, приходящегося на одного члена семьи, мы опрашиваем всех членов семей, попавших в выборку. Ясно, что ответы на этот вопрос в каждой семье будут совпадать. Другими словами, фактическое число действительно различных, с интересующей нас точки зрения, респондентов окажется равным не числу членов семьи, а всего лишь числу семей. Этот эффект носит название «дизайн-эффекта» .