Существующие модели рекомендательных систем

В методах группы user-based сходство ищется между пользователями и в качестве рекомендаций пользователю u0 выдается n самых часто покупаемых товаров k наиболее похожими на него покупателями. Введем обозначения: u0 — «целевой» пользователь, u0I — предметы, которые он оценивал, sim (u0, u) — сходство пользователя u0 с пользователем u. В нашей работе для подсчета сходства мы использовали коэффициент… Читать ещё >
Существующие модели рекомендательных систем (реферат, курсовая, диплом, контрольная)
В нашей работе представлены две группы методов, ставших классическими в рассматриваемой области: user-based (основанные на сходстве пользователей) и item-based (основанные на сходстве признаков) (см. [Badrul et al., 2000]). Ключевым для работы этих методов является понятие сходства (математически это может быть мера Жаккара, корреляция Пирсона, мера косинусов и т. п.). Исходные данные представлены объектно-признаковыми матрицами, в которых столбцам соответствуют признаки (товары), а строкам объекты (пользователи). На пересечении строк и столбцов записаны 1 или 0, которые означают факт покупки или ее отсутствие. Также значениями ячеек таблицы могут быть рейтинги или оценки товаров, например, фильмов, поставленные пользователями.
Рекомендации, основанные на сходстве пользователей (User-based)
В методах группы user-based сходство ищется между пользователями и в качестве рекомендаций пользователю u0 выдается n самых часто покупаемых товаров k наиболее похожими на него покупателями. Введем обозначения: u0 — «целевой» пользователь, u0I — предметы, которые он оценивал, sim (u0, u) — сходство пользователя u0 с пользователем u. В нашей работе для подсчета сходства мы использовали коэффициент корреляции Пирсона. Определим множество ближайших соседей (соседство) для целевого пользователя по формуле:
.
На самом деле удобнее брать top-k ближайших соседей, т. е. top-k определяет. Таким образом, во множество ближайших соседей попадают те пользователи, сходство которых с целевым выше некоторого порога. После упорядочения пользователей по убыванию сходства, нужно отбирать не только первые k, но и проверить значение сходства у следующего (k+1) по списку. Если это значение совпадает с последним, включать и k+1-го пользователя в соседство. И так до тех пор, пока сходство не изменится. Поскольку мы предсказываем оценку целевым пользователем конкретного предмета i, нам интересны только те пользователи из этого соседства, которые оценивали предмет i:
.
Обозначив оценку предмета i пользователем u через rui, получаем итоговую формулу для предсказанной оценки:
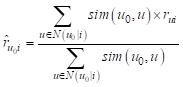
.
Чтобы выдать пользователю рекомендацию, нужно посчитать такие предсказания для каждого из неоцененных им предметов, ранжировать по убыванию и выдать первые n предметов в качестве рекомендованных.