Идентификация слов по входящим в них буквам с применением системно-когнитивного анализа

Текстовый файл создается в редакторе Word или MultiEdit. Если он создан в Word, то при сохранении выбирается режим: «Файл — Сохранить как — Тип файла: Текст DOS с разбиением на строки». Имя файла произвольное, но удовлетворяющее требованиям DOS. Этот файл каждый студент создает самостоятельно из двух — трех абзацев текста. Например, это может быть краткая биография студента или текст может быть… Читать ещё >
Идентификация слов по входящим в них буквам с применением системно-когнитивного анализа (реферат, курсовая, диплом, контрольная)
Язык является мощным средством моделирования реальности. Иерархическая структура языка, включающего в частности такие структуры, как символы, слова, предложения и тексты, является ярким примером иерархической структуры обработки информации, обеспечивающей адекватное отражение структуры реальности. Описание некоторых объектов на естественном языке является их моделированием и позволяет решать задачи идентификации, прогнозирования, сравнения и классификации этих объектов. Автоматизированный синтез моделей объектов, описанных на естественном языке, представляет большой интерес для теории и практики систем искусственного интеллекта.
Эффективность языка, как системы моделирования, удивительна: 32 буквы русского алфавита позволяют составить более 40 тысяч слов русского языка, из которых может быть образовано огромное количество осмысленных предложений.
Каждый символ содержит некоторое количество информации о словах, предложениях и текстах, в которые он входит, каждое слово — о предложениях и текстах, и каждое предложение — о текстах. Однако в буквах содержится больше информации о словах, в словах — о предложениях, в предложениях — о текстах. Поэтому на основе анализа букв целесообразно идентифицировать лишь слова, а на основе слов — предложения, на основе предложений — тексты.
В данной статье исследуется возможность идентификации слов по входящим в них буквам. При этом слова рассматриваются как классы распознавания, а буквы — как признаки.
Эта задача проста и наглядна. Поэтому она рекомендуется в качестве первой лабораторной работы для освоения инструментария системно-когнитивного анализа — универсальной когнитивной аналитической системы «Эйдос» [1, 2, 3]. В этой связи изложение материала в статье ведется в такой форме, чтобы ее можно было использовать в качестве руководства к лабораторной работе.
Подобные задачи имеют большое практическое значение и решаются в ряде систем, например, в редакторе Word — при проверке орфографии и подборе рекомендуемых слов для замены, в системе FineReader — для поиска слов с неверно распознанными символами и др.
Задание:
- 1. Создать файл в стандарте DOS-текст с концами строк, записать его в поддиректорию DOB.
- 2. Сгенерировать классификационные и описательные шкалы и градации, а также обучающую выборку.
- 3. Осуществить синтез и верификацию модели.
- 4. Провести анализ устойчивости модели к неполноте информации и наличию шума.
- 5. Проверить способность модели правильно идентифицировать классы, один из которых является подмножеством другого.
- 6. Оценить ценность букв для идентификации слов. Сравнить суммарную ценность для этой цели гласных и согласных букв.
- 7. Выполнить кластерно-конструктивный анализ слов и букв, вывести информационные и семантические портреты слов и букв, построить их профили.
- 8. Вывести в графической форме семантические сети и когнитивные диаграммы слов и букв, а также классическую и интегральную когнитивные карты.
Пример решения задания 1: «Создать файл в стандарте DOS-текст с концами строк, записать его в поддиректорию DOB»
Текстовый файл создается в редакторе Word или MultiEdit. Если он создан в Word, то при сохранении выбирается режим: «Файл — Сохранить как — Тип файла: Текст DOS с разбиением на строки». Имя файла произвольное, но удовлетворяющее требованиям DOS. Этот файл каждый студент создает самостоятельно из двух — трех абзацев текста. Например, это может быть краткая биография студента или текст может быть взят из какого-либо файла, имеющегося на компьютере. Могут использоваться и русский, и латинский алфавиты, а также цифры. Регистр роли не играет.
Пример текста файла: Молоко око срок окорок огород В. Г. Белинский высоко и по достоинству оценил гениальное творение нашего национального поэта. Великий критик писал:
" Пусть идет время и приводит с собой новые потребности, пусть растет русское общество и обгоняет «Онегина»: как бы далеко оно ни ушло, всегда будет оно любить эту поэму, всегда будет останавливать на ней исполненный любви и благодарности взор…" .
Слова из этого файла будут использованы системой для выполнения следующего этапа работы.
Пример решения задания 2: «Сгенерировать классификационные и описательные шкалы и градации, а также обучающую выборку»
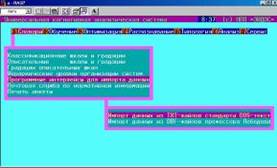
Генерация классификационных и описательных шкал и градаций осуществляется в соответствующих режимах системы «Эйдос»: «Автоввод первичных признаков и TXT-файлов», «F5 Признаки — Буквы» (рисунки 1, 2):
 Рисунок 1. Выбор режима «Импорт данных из TXT-файлов стандарта DOS-текст. | Рисунок 2. Выбор режима «Признаки — F5 Буквы» . | |
В результате будут автоматически сгенерированы классификационные и описательные шкалы и градации, а также обучающая выборка (приведена полностью) (таблицы 1, 2 3).
Таблица 1 — Классификационные шкалы и градации (слова)
Код. | Слово. | Код. | Слово. | Код. | Слово. | |
БЕЛИНСКИЙ. | ЛЮБВИ. | ОЦЕНИЛ. | ||||
БЛАГОДАРНОСТИ. | ЛЮБИТЬ. | ПИСАЛ. | ||||
БУДЕТ. | МОЛОКО. | ПОТРЕБНОСТИ. | ||||
ВЕЛИКИЙ. | НАЦИОНАЛЬНОГО. | ПОЭМУ. | ||||
ВЗОР. | НАШЕГО. | ПОЭТА. | ||||
ВРЕМЯ. | НЕЙ. | ПРИВОДИТ. | ||||
ВСЕГДА. | НОВЫЕ. | ПУСТЬ. | ||||
ВЫСОКО. | ОБГОНЯЕТ. | РАСТЕТ. | ||||
ГЕНИАЛЬНОЕ. | ОБЩЕСТВО. | РУССКОЕ. | ||||
ДАЛЕКО. | ОГОРОД. | СОБОЙ. | ||||
ДОСТОИНСТВУ. | ОКО. | СРОК. | ||||
ИДЕТ. | ОКОРОК. | ТВОРЕНИЕ. | ||||
ИСПОЛНЕННЫЙ. | ОНЕГИНА. | УШЛО. | ||||
КАК. | ОНО. | ЭТУ. | ||||
КРИТИК. | ОСТАНАВЛИВАТЬ. | |||||
Таблица 2 — Описательные шкалы и градации (буквы)
Код. | Буква. | Код. | Буква. | Код. | Буква. | Код. | Буква. | |
H. | Y. | П. | ||||||
I. | Z. | Р. | ||||||
J. | А. | С. | ||||||
K. | Б. | Т. | ||||||
L. | В. | У. | ||||||
M. | Г. | Ф. | ||||||
N. | Д. | Х. | ||||||
O. | Е. | Ц | ||||||
P. | Ж. | Ч. | ||||||
Q. | З. | Ш. | ||||||
A. | R. | И. | Щ. | |||||
B. | S. | Й. | Ъ. | |||||
C. | T. | К. | Ы. | |||||
D. | U. | Л. | Ь. | |||||
E. | V. | М. | Э. | |||||
F. | W. | Н. | Ю. | |||||
G. | X. | О. | Я. | |||||
Таблица 3 — Обучающая выборка
№. | Класс. | Коды признаков. | ||||||||||||||
БЕЛИНСКИЙ. | ||||||||||||||||
БЛАГОДАРНОСТИ. | ||||||||||||||||
БУДЕТ. | ||||||||||||||||
ВЕЛИКИЙ. | ||||||||||||||||
ВЗОР. | ||||||||||||||||
ВРЕМЯ. | ||||||||||||||||
ВСЕГДА. | ||||||||||||||||
ВЫСОКО. | ||||||||||||||||
ГЕНИАЛЬНОЕ. | ||||||||||||||||
ДАЛЕКО. | ||||||||||||||||
ДОСТОИНСТВУ. | ||||||||||||||||
ИДЕТ. | ||||||||||||||||
ИСПОЛНЕННЫЙ. | ||||||||||||||||
КАК. | ||||||||||||||||
КРИТИК. | ||||||||||||||||
ЛЮБВИ. | ||||||||||||||||
ЛЮБИТЬ. | ||||||||||||||||
МОЛОКО. | ||||||||||||||||
НАЦИОНАЛЬНОГО. | ||||||||||||||||
НАШЕГО. | ||||||||||||||||
НЕЙ. | ||||||||||||||||
НОВЫЕ. | ||||||||||||||||
ОБГОНЯЕТ. | ||||||||||||||||
ОБЩЕСТВО. | ||||||||||||||||
ОГОРОД. | ||||||||||||||||
ОКО. | ||||||||||||||||
ОКОРОК. | ||||||||||||||||
ОНЕГИНА. | ||||||||||||||||
ОНО. | ||||||||||||||||
ОСТАНАВЛИВАТЬ. | ||||||||||||||||
ОЦЕНИЛ. | ||||||||||||||||
ПИСАЛ. | ||||||||||||||||
ПОТРЕБНОСТИ. | ||||||||||||||||
ПОЭМУ. | ||||||||||||||||
ПОЭТА. | ||||||||||||||||
ПРИВОДИТ. | ||||||||||||||||
ПУСТЬ. | ||||||||||||||||
РАСТЕТ. | ||||||||||||||||
РУССКОЕ. | ||||||||||||||||
СОБОЙ. | ||||||||||||||||
СРОК. | ||||||||||||||||
ТВОРЕНИЕ. | ||||||||||||||||
УШЛО. | ||||||||||||||||
ЭТУ. |
Пример решения задания 3: «Осуществить синтез и верификацию модели»
Синтез модели осуществляется на основе обучающей выборки (таблица 3) в соответствующем режиме (рисунок 3) после формирования классификационных и описательных шкал и градаций и обучающей выборки.
В результате синтеза семантической информационной модели рассчитываются две ее основные матрицы: матрица абсолютных частот (таблица 4) и матрица информативностей (таблица 5).
Таблица 4 — Матрица абсолютных частот (фрагмент)
Коды букв. | Коды классов (слов). | |||||||||||||||||||
Таблица 5 — Матрица информативностей (фрагмент)
Кодыбукв. | Коды классов (слов). | |||||||||||||||||||
1,0. | 1,1. | 0,6. | 1,1. | 1,7. | 1,0. | |||||||||||||||
1,2. | 0,9. | 1,8. | 1,8. | 1,6. | ||||||||||||||||
1,1. | 1,6. | 1,4. | 1,3. | 1,3. | 0,7. | 1,4. | ||||||||||||||
1,0. | 1,7. | 1,2. | 1,0. | |||||||||||||||||
1,0. | 1,9. | 1,7. | 1,7. | 1,1. | 2,1. | |||||||||||||||
0,4. | 0,9. | 0,6. | 0,9. | 0,7. | 0,9. | 0,7. | 1,1. | 0,2. | ||||||||||||
4,1. | ||||||||||||||||||||
1,0. | 1,3. | 0,3. | 0,2. | 1,1. | 0,2. | 1,4. | 0,9. | 0,7. | ||||||||||||
1,8. | 2,0. | 1,6. | ||||||||||||||||||
0,8. | 1,0. | 1,2. | 1,2. | 2,5. | 1,9. | 1,2. | ||||||||||||||
0,8. | 0,4. | 1,0. | 0,7. | 1,2. | 0,6. | 1,4. | 1,2. | 1,2. | 0,4. | |||||||||||
2,8. | 2,7. | |||||||||||||||||||
0,4. | 0,9. | 0,2. | 1,2. | 1,1. | ||||||||||||||||
0,4. | 0,7. | — 0,5. | 0,1. | — 0,6. | 1,1. | 0,3. | ||||||||||||||
1,3. | ||||||||||||||||||||
0,6. | 1,7. | 1,5. | 1,3. | |||||||||||||||||
0,6. | 0,2. | 1,0. | 1,0. | 1,1. | 0,4. | |||||||||||||||
0,1. | 1,0. | 0,9. | 1,2. | 0,8. | 0,8. | |||||||||||||||
2,0. | 1,3. | |||||||||||||||||||
Верификация модели осуществляется путем копирования обучающей выборки в распознаваемую (рисунок 4), распознавания (рисунок 5) и измерения дифференциальной и интегральной валидности (рисунок 6).
 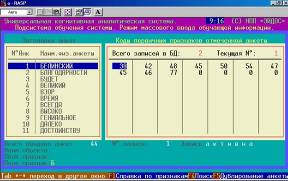 Рисунок 3. Режим «Синтез семантической информационной модели» системы «Эйдос» . | Рисунок 4. Режим «Ввод-корректировка обучающей выборки» системы «Эйдос» (копирование ее в распознаваемую — F5). | |
 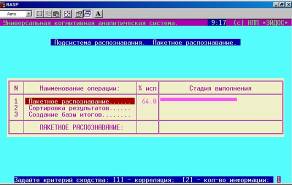 Рисунок 5. Выбор режима «Пакетное распознавание» . системы «Эйдос» . | Рисунок 6. Выполнение режима «Пакетное распознавание» . системы «Эйдос» . | |
 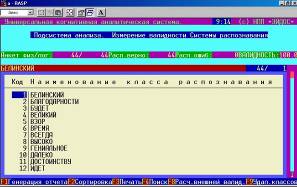 Рисунок 7. Выбор режима «Измерение адекватности модели» системы «Эйдос» . | Рисунок 8. Режим «Измерение адекватности модели» системы «Эйдос» . | |
Видим, что модель адекватна, т.к. интегральная валидность составляет 100%. Это означает, что при идентификации слов на основе знания входящих в них букв системой не было допущено ни одной ошибки, причем необходимо специально отметить, что при этом в модели не учитывались последовательность букв и их сочетаний.
Пример решения задания 4: «Проверить устойчивость модели к неполноте информации и наличию шума»
В примере, исследуемом в данной лабораторной работе, неполнота информации — это пропуск букв, а наличие шума — замена верных букв неверными.
Устойчивость модели к неполноте информации. Подготовим распщими буквами.
Для этого выполним следующую последовательность шагов:
Шаг 1. Сбросим распознаваемую выборку в режиме «F7 Сервис — Генерация (сброс) баз данных — Распознаваемые анкеты» (рисунок 9):
Шаг 2. Скопируем, например, первую анкету из обучающей выборки в распознаваемую, используя возможности режима «F2 Обучение — Ввод-корректировка обучающей выборки» (рисунок 4);
Шаг 3. Выберем режим «F4 Распознавание — Ввод-корректировка распознаваемой выборки» (рисунок 10):
Выбор режима осуществляется нажатием клавиши Enter.
Шаг 4. Перейдем в правое окно, в котором задаются коды признаков, нажав клавишу «TAB» .
Шаг 5. Удаляем последний код признака и дублируем анкету, нажав клавишу «F5 Дублирование анкеты» .
  Рисунок 9. Режим «Сброс распознаваемой выборки» системы «Эйдос» . | Рисунок 10. Выбор режима «Ввод-корректировка распознаваемой выборки» системы «Эйдос» . | |
Повторяем шаги 4 и 5 до тех пор, пока в описании слова останется одна буква. В результате получится видеограмма, представленная на рисунке 11.
Студенты при выполнении этого этапа работы могут взять несколько анкет на выбор. При этом набор анкет должен отличаться у разных студентов.
Обучающая выборка в этом случае будет иметь вид, представленный на таблице 4:
Таблица 6 — Варианты кодирования объекта обучающей выборки, отличающиеся степенью неполноты информации
№. | Класс. | Коды признаков. | |||||||||
БЕЛИНСКИЙ. | |||||||||||
БЕЛИНСКИЙ. | |||||||||||
БЕЛИНСКИЙ. | |||||||||||
БЕЛИНСКИЙ. | |||||||||||
БЕЛИНСКИЙ. | |||||||||||
БЕЛИНСКИЙ. | |||||||||||
БЕЛИНСКИЙ. | |||||||||||
БЕЛИНСКИЙ. | |||||||||||
БЕЛИНСКИЙ. | |||||||||||
Жирным шрифтом выделены символы, коды которых есть в анкете.
Шаг 6. Выполним пакетное распознавание, выбрав и выполнив режим «F4 Распознавание — Пакетное распознавание», как показано на рис. 5 и 6.
Шаг 7. Затем выберем и выполним режим «F4 Распознавание — Вывод результатов распознавания» (рисунок 12):
  Рисунок 11. Выполнение режима «Ввод-корректировка распознаваемой выборки» системы «Эйдос» . | Рисунок 12. Выбор режима «Вывод результатов распознавания» . системы «Эйдос» . | |
Шаг 8. Войдя в этот режим получим видеограмму, представленную на рисунке 13:
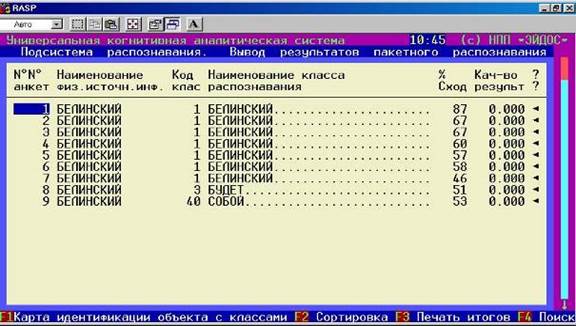 Рисунок 13. Обобщенная форма по результатам выполнения режима «Вывод результатов распознавания» системы «Эйдос» . |
Шаг 9. Нажав клавишу «F1 Карта идентификации объекта с классами» получим более подробные результаты идентификации, представленные на рисунке 14:
 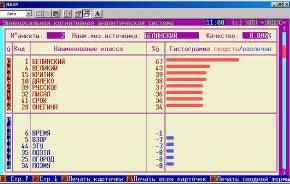 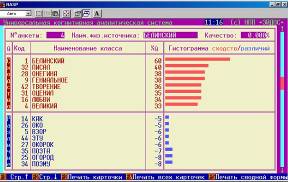 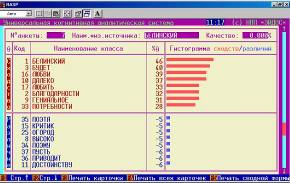 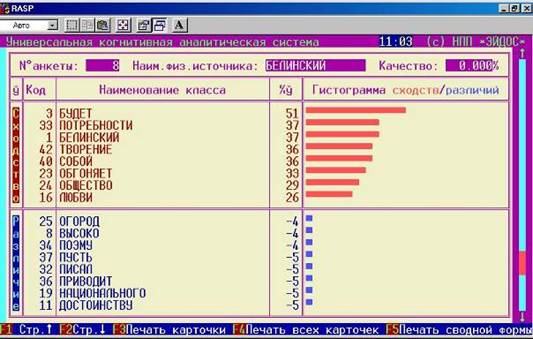 Рисунок 14. Идентификация в условиях неполноты информации в системе «Эйдос» . | |
Из обобщенных и детальных выходных форм по результатам распознавания слова по его неполному описанию видно, что модель обладает очень высокой устойчивостью к неполноте информации в описании идентифицируемых объектов.
Устойчивость модели к наличию шума. Шум можно раволы).
Поэтому замену символов в словах на символы, которые не встречаются по обучающей выборке можно считать неполнотой информации.
Этот случай мы рассматривать не будем, т.к. по сути уже рассмотрели его в предыдущем пункте.
Рассмотрим пример, в котором одно слово заменой букв преобразуется в другое слово, например, слово «критик» преобразуется в слово «окорок» .
Каждой замене будет соответствовать одна анкета распознаваемой выборки (таблица 5):
Таблица 7 — Варианты кодирования объекта обучающей выборки, отличающиеся уровнем шума
№. | Класс. | Коды признаков. | ||||||
КРИТИК. | ||||||||
КРОТИК. | ||||||||
КРОТОК. | ||||||||
ОКОРОК. | ||||||||
Результаты идентификации представлены на рисунке 15:
 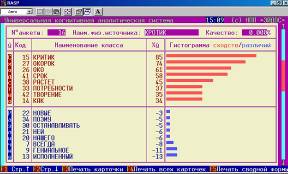 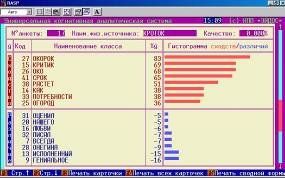 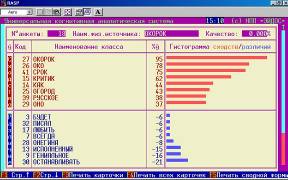 Рисунок 15. Результаты идентификации в условиях шума в системе «Эйдос» . | ||
Видим, что модель обладает определенной устойчивостью и к шуму.
Пример решения задания 5: «Проверить способность модели правильно идентифицировать классы, один из которых является подмножеством другого»
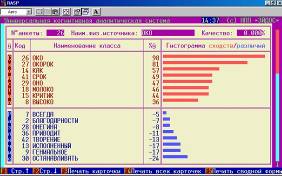
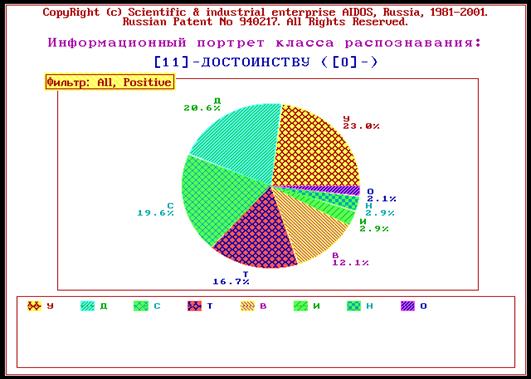
С этой целью в текстовый файл специально включены такие слова, как: «око», «окорок», «молоко». Результаты их идентификации приведены на рисунке 16:
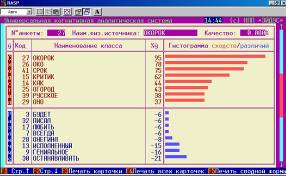 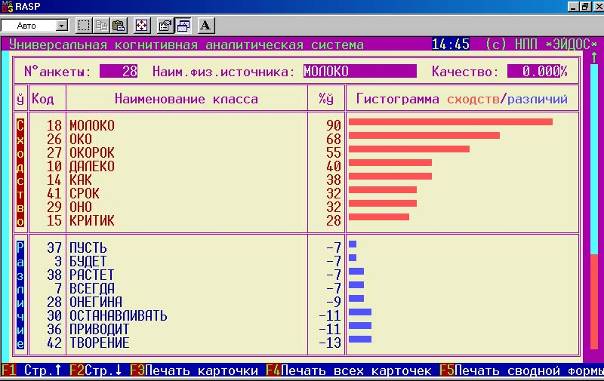 Рисунок 16. Карточки результатов распознавания системы «Эйдос» в случае идентификации классов, один из которых является подмножеством других. | ||
Как видим идентификация осуществляется правильно. Это является важным достоинством семантической информационной модели системы «Эйдос», т.к. представляет собой проблему для многих типов нейронных сетей. Достаточно отметить, что возможность решения подобных задач считается одним из основных достоинств развитой модели нейронной сети, реализованной в неокогнитроне Фукушимы.
Пример решения задания 6: Оценить ценность букв для идентификации слов. Сравнить суммарную ценность для этой цели гласных и согласных букв
Для решения этой задачи запустим 2-й режим в 3-й подсистеме (рисунок 17). В этом режиме все признаки, которыми в данном примере являются буквы, выводятся системой «Эйдос» в порядке убывания среднего количества информации, которое в них содержится о принадлежности к словам.
Если просуммировать ценность букв «нарастающим итогом» то получим накопительную кривую, представленную на рисунке 18.
Эта кривая называется «Парето-диаграмма» по имени известного итальянского математика и экономиста XIX века Вильфредо Парето, впервые предложившего оценивать силу влияния факторов и исключать из рассмотрения незначимые факторы и впервые построившего подобные диаграммы.
 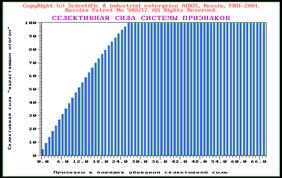 Рисунок 17. Запуск режима системы «Эйдос» измерения ценности признаков для решения задач идентификации, прогнозирования и управления. | Рисунок 18. Парето-диаграмма ценности букв для идентификации слов. | |
Характерная «полочка» на Парето-диаграмме соответствует цифрам и буквам латинского алфавита, которые не встретились в словах обучающей выборки. язык парето word идентификация слово В таблице 8 приведены буквы, проранжированные в порядке убывания среднего количества информации в них, о принадлежности к словам.
Таблица 8 — Ценность букв для идентификации слов
№. | Код. | Буква. | Ценность (бит). | Ценность (бит). " нарастающим итогом" . | Ценность (%). " нарастающим итогом" . | |
Э. | 0,76 988. | 0,76 988. | 4,841. | |||
У. | 0,74 529. | 1,51 517. | 9,526. | |||
М. | 0,71 090. | 2,22 607. | 13,996. | |||
Й. | 0,69 728. | 2,92 335. | 18,380. | |||
Ш. | 0,68 748. | 3,61 083. | 22,703. | |||
К. | 0,68 569. | 4,29 652. | 27,014. | |||
Ю. | 0,66 376. | 4,96 028. | 31,187. | |||
П. | 0,66 014. | 5,62 042. | 35,338. | |||
Ы. | 0,65 157. | 6,27 199. | 39,434. | |||
Д. | 0,64 023. | 6,91 222. | 43,460. | |||
Я. | 0,63 612. | 7,54 834. | 47,459. | |||
З. | 0,62 131. | 8,16 965. | 51,366. | |||
Ь. | 0,59 697. | 8,76 662. | 55,119. | |||
Б. | 0,59 622. | 9,36 284. | 58,868. | |||
Р. | 0,58 610. | 9,94 894. | 62,553. | |||
Ц | 0,57 201. | 10,52 095. | 66,149. | |||
Г. | 0,56 958. | 11,9 053. | 69,730. | |||
В. | 0,55 490. | 11,64 543. | 73,219. | |||
Щ. | 0,52 045. | 12,16 588. | 76,492. | |||
А. | 0,51 477. | 12,68 065. | 79,728. | |||
Л. | 0,50 010. | 13,18 075. | 82,872. | |||
С. | 0,47 977. | 13,66 052. | 85,889. | |||
Т. | 0,47 498. | 14,13 550. | 88,875. | |||
О. | 0,46 548. | 14,60 098. | 91,802. | |||
  | Н. | 0,45 089. | 15,5 187. | 94,637. | ||
И. | 0,43 046. | 15,48 233. | 97,343. | |||
Е. | 0,42 253. | 15,90 486. | 100,000. | |||
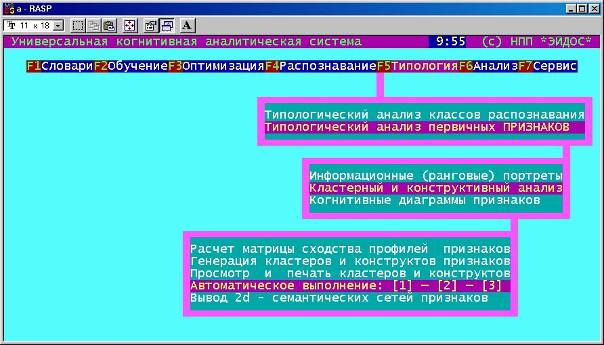
Пример решения задания 7: «Выполнить кластерно-конструктивный анализ слов и букв, вывести информационные и семантические портреты слов и букв, построить их профили»
Кластерно-конструктивный анализ слов. Кластерно-конструктивный анализ выполняется в 5-й подсистеме «Типология» (рисунок 19).
Сначала на основе матрицы информативностей рассчитывается матрица сходства классов (таблица 7), а затем на основе нее формируется таблица кластеров и конструктов клас…