Алгоритм к центроидов

Шаг обновления: для каждого центроида тп и каждого элемента набора данных о из этого кластера происходит обмен ролями: в этом кластере о становится центроидом, am — рядовым элементом кластера. Вычисляется общий штраф конфигурации кластера (здесь и ниже штрафом называется сумма расстояний, вычисляемых на шаге назначения). Эта процедура повторяется для всех элементов о кластера, и выбирается… Читать ещё >
Алгоритм к центроидов (реферат, курсовая, диплом, контрольная)
Алгоритм к центроидов (k medoids algorithm) является алгоритмом кластеризации, идейно связанным с алгоритмом ^-средних.
Центроид (medoid) — репрезентативный элемент набора данных или кластера, среднее отличие которого от всех элементов кластера минимально.
Центроиды по смыслу подобны средним значениям или средним точкам кластера, но центроиды всегда — элементы набора данных. Центроиды обычно используются для таких данных, среднее или центр которых не могут быть определены. Для некоторых наборов данных может быть больше чем один центроид, как и с медианами. Этот алгоритм в основном работает следующим образом:
- 1) выбирается наугад несколько (например, к) центроидов;
- 2) вычисляются расстояния до других элементов набора данных;
- 3) данные группируются согласно центроиду, которому они являются самыми близкими;
- 4) набор центроидов оптимизируется с помощью рекуррентного процесса.
Заметим, что центроид не эквивалентен медиане или геометрической медиане. Медиана определена только на одномерных данных, и она минимизирует только отличие от других элементов набора данных по определенной метрике расстояния (манхэттенская норма — сумма модулей разности координат). Геометрическая медиана определена в любом измерении, но не обязательно является элементом исходного набора данных.
Алгоритмы к средних и к центроидов расчленяют исходный набор данных на кластеры, одновременно минимизируя расстояние между данными и центром кластера. В отличие от алгоритма к средних алгоритм к центроидов выбирает в качестве центра кластера один из элементов набора данных и работает с произвольной матрицей расстояний между элементами набора данных (вместо эвклидова расстояния используются расстояния Лебега Ьр, например р — 2, как в алгоритме k средних). Этот метод был предложен Л. Кауфманом и П. Руссэ в 1987 г. для работы с нормой I, и другими расстояниями. Алгоритм к центроидов является классической техникой разделения набора данных на кластеры, он группирует набор п данных объектов в k кластеров (к известно априори; однако для того чтобы определить k, можно использовать алгоритм «силуэт»). Алгоритм к центроидов является более устойчивым (робастным) к искажениям и выбросам данных, но сравнению с алгоритмом к средних, потому что алгоритм k центроидов минимизирует сумму попарных отличий, которые нс обязательно являются суммами квадратов евклидовых расстояний, как в алгоритме k средних.
Центроид может быть определен как элемент кластера, среднее различие которого со всеми элементами кластера минимально, т. е. это элемент, расположенный в самом центре кластера. Наиболее распространенной реализацией алгоритма к центроидов является РАМ (Partitioning Around Medoids), который работает следующим образом.
- 1. Калибровка: наудачу фиксируется k конкретных элементов из исходного набора п данных как центроиды.
- 2. Шаг назначения: каждый элемент из исходного набора п данных связывается с самым близким центроидом («самый близкий» здесь определяется с использованием любой вещественной метрики расстояния: обычное евклидово расстояние, манхэттенское расстояние или расстояние Минковского). Манхэттенское расстояние между двумя векторами р и q в «-мерном реальном векторном пространстве с фиксированной декартовской системой координат является суммой длин проекций линейного сегмента между концами вектора на координатные оси. Это соответствует вычислению по формуле
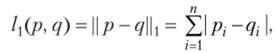
где 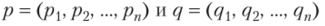 — векторы.
— векторы.
- 3. Шаг обновления: для каждого центроида тп и каждого элемента набора данных о из этого кластера происходит обмен ролями: в этом кластере о становится центроидом, am — рядовым элементом кластера. Вычисляется общий штраф конфигурации кластера (здесь и ниже штрафом называется сумма расстояний, вычисляемых на шаге назначения). Эта процедура повторяется для всех элементов о кластера, и выбирается конфигурация с наименьшим штрафом.
- 4. После обновления всех кластеров выбирается конфигурация с наименьшим штрафом.
Повторяются шаги 2—4 до тех пор, пока никакого изменения в наборе центроидов не происходит.
Пример 13.2 (реализация алгоритма РАМ). Кластеризуем следующие данные из 10 объектов (двумерных векторов) на два кластера, т. е. k = 2. Данные заданы таблицей:
х{ | х2 | *3. | *4. | *5. | *6. | X? | х8 | *9. | ?По. |
Решение. Представим данные графически (13.2).
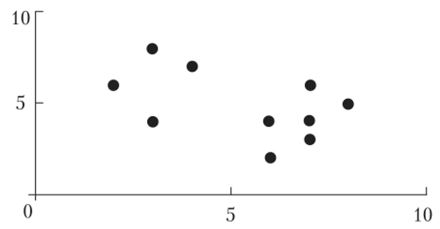
Рис. 13.2. Графическое представление данных примера 13.2.
Шаг 1. Пусть центроидами двух кластеров выбраны mt = (3, 4) и гп2 = (7, 4), т. е. х2 и х8. Вычисляются расстояния, связывающие каждый объект данных с его самым близким центроидом. Штраф вычисляется, используя манхэттенское расстояние (расстояние Минковского, метрика с г = 1). Штраф для пары точек вычисляется по формуле 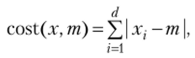
где х — элемент набора данных; т — центроид: d — размерность данных, которая в рассматриваемом случае равна 2. Общий штраф равен сумме штрафов для элементов, образующих кластер с центроидом т. Штрафы со стороны самого близкого центроида показаны жирным шрифтом в табл. 13.2.
Точки (2, 6), (3, 8) и (4, 7) ближе к тх, чем к т2, значит, они вместе с тх образуют один кластер, в то время как остальные точки образуют другой кластер. Общие штрафы кластеров будут равны, соответственно, 11 (для кластера 1, сумма жирных цифр в 6-й колонке) и 9 (для кластера 2, сумма жирных цифр в последней колонке таблицы), а общий штраф всей конфигурации равен 20.
Штрафы для примера 13.2
Таблица 132
Центроид от, = (3, 4). | Центроид т2 = (7, 4). | ||||||||||
i | от,. | Данные,. xi | Штраф к,-от,|. | т2 | Данные,. xi | Штраф. |*,.-от2|. | |||||
б. | |||||||||||
Поэтому кластерами становятся следующие наборы:
- • кластер 1 = {(3, 4), (2, б), (3, 8), (4, 7)};
- • кластер 2 = {(7, 4), (6, 2), (6, 4), (7, 3), (8, 5), (7, 6)}.
Шаг 2. Выберем теперь в кластере 1 в качестве центроида точку о, = (2, 6), а от, = (3, 4) будем считать рядовым элементом кластера. Теперь центроидами конфигурации будут точки о, = (2, 6) и от2 = (7, 4). С этими центроидами правая половина табл. 13.2 останется прежней, а левая половина преобразуется к виду.
Центроид о, = (2, 6). | |||||
i | ° | Данные, х,. | Штраф |х, — о,|. | ||
б. | |||||
б. | |||||
Структура кластеров не меняется, однако общий штраф кластера 1 уменьшился на 2, стал равным 9, и общий штраф всей конфигурации уменьшился до 18.
Шаг 3. Повторяем процедуру при другом выборе центроидов и снова подсчитываем общий штраф конфигурации. Если это приводит к уменьшению общего штрафа конфигурации, принимаются соответствующие ему центроиды. Затем выбирается новый центроид и т. д. Процедура прекращается, когда никакого изменения в наборе центроидов не происходит. Например, в рассматриваемом случае выберем один из элементов набора данных о2, не являющихся центроидом. Пусть о2 = (7, 3). Таким образом, теперь центроидами будут о, = (2, 6) и о2 = (7, 3). Вычислим для них общий штраф. В результате изменения центроида на о2 вместо т2 правая половина табл. 13.2 для кластера 2 изменится и будет такой:
Центроид о2 = (7, 3). | |||||
i | °2. | Данные, xt | Штраф о2|. | ||
Общий штраф оказывается равным 20, т. е. увеличивается на 2 по сравнению с шагом 2.
Таким образом, получается, что вариант шага 2 был лучшим. Поэтому конфигурация не изменяется, и алгоритм на этом завершает работу, так как нет никакого изменения центроидов.
В общем случае может оказаться, что некоторые отдельные элементы набора данных могут перейти из одного кластера в другой в зависимости от их близости с центроидом. В некоторых ситуациях алгоритм k центроидов демонстрирует лучшую работу, чем алгоритм k средних. Самой трудоемкой процедурой алгоритма k центроидов является вычисление расстояний между элементами набора данных. Если предварительная обработка и хранение информации доступны, матрица расстояний может быть вычислена предварительно, что ускоряет процедуру. Заметим, что существуют различные эвристические способы выбора начальных k центроидов.