Генерация вспомогательных списков

Поскольку одна из основных идей — легкая масштабируемость инструмента на другие языки при наличии языкового корпуса и морфологического анализатора, при продумывании архитектуры приложения большое внимание уделялось тому, чтобы для работы генератора тестов требовалось минимальное количество ручного труда. Несмотря на то, что полностью абстрагироваться от языка генерации тестов не представляется… Читать ещё >
Генерация вспомогательных списков (реферат, курсовая, диплом, контрольная)
Поскольку одна из основных идей — легкая масштабируемость инструмента на другие языки при наличии языкового корпуса и морфологического анализатора, при продумывании архитектуры приложения большое внимание уделялось тому, чтобы для работы генератора тестов требовалось минимальное количество ручного труда. Несмотря на то, что полностью абстрагироваться от языка генерации тестов не представляется возможным, можно попытаться максимально сократить ручной труд и генерировать языковые списки автоматически.
Материалом для генерации тестов по русскому языку и языковых списков стала «База данных метатекстовой разметки Национального корпуса русского языка» (основной корпус письменных текстов)". Объем используемого корпуса: 3 000 000 предложений, 32 433 131 словоупотреблений, 223 194 леммы.
Для работы инструмента необходимы следующие автоматически генерируемые языковые списки:
- 1) отсортированный список частотностей двух типов
- 2) частеречные списки (местоимений, местоименных прилагательных, предлогов и союзов)
- 3) список коллокаций
Генерация вспомогательных списков, на основе которых позже будут генерироваться тесты, является первостепенной и очень важной задачей, поскольку от качества генерируемых списков непосредственно зависит качество генерируемых тестов. В следующих разделах будет более подробно описан процесс генерации языковых списков.
Генерация списков частотностей При генерации тестов очень важно учитывать частотность слов, поскольку знание более частотных слов на среднем уровне владения языком позволяет строить сразу большое количество предложений, в то время как редкие и тематические слова представляют интерес уже на продвинутых уровнях владения языком.
Списки частотностей строятся на всем материале языкового корпуса. Сначала тексты нормализуются. На этапе предобработки текста:
- · все буквы приводятся к нижнему регистру;
- · удаляются все не-буквы;
- · предложения токенизируются;
- · слова лемматизируются;
- · стоп-слова удаляются.
Далее, на основе данных корпуса генерируются три типа списков частотностей:
- 1) для каждой леммы подсчитывается ее абсолютная частота
- 2) для каждой леммы подсчитывается ее относительная частота, равная отношению абсолютной частоты к частоте самого частотного слова
- 3) для каждой леммы указывается ее порядковый номер в отсортированном списке частотностей
Ниже приведены 20-топ слов частотного списка, сгенерированного без удаления стоп-слов.
Таблица Списки частотностей.
Лемма. | Номер в частотном списке. | Абсолютная частота. | Относительная частота. | |
и. | 1.0. | |||
в. | 0.7910. | |||
не. | 0.5329. | |||
на. | 0.4511. | |||
я. | 0.4008. | |||
он. | 0.3922. | |||
что. | 0.3434. | |||
быть. | 0.3420. | |||
с. | 0.3040. | |||
а. | 0.2434. | |||
как. | 0.1891. | |||
она. | 0.1765. | |||
это. | 0.1726. | |||
но. | 0.1542. | |||
они. | 0.1502. | |||
к. | 0.1463. | |||
этот. | 0.1456. | |||
то. | 0.1448. | |||
по. | 0.1429. | |||
мы. | 0.1388. | |||
Поскольку при изучении языка важно знать частотные слова языка, знание которых позволяет составлять большое количество предложений, был введен параметр важности слова. Сама идея оценивать слова по их значимости для изучения языка не нова, разрабатываются лексические минимумы для разных уровней владения языком. Итак, для каждого слова в словаре частотностей также оценивается его важность. При оценке важности лексемы мы руководствовались некоторыми понятиями, используемыми при составлении лексических минимумов (Ильина). Важность лексемы складывается из следующих параметров:
- 1) количество предложений, содержащих лексему
- 2) способность лексемы входить в различные словосочетания
- 3) частотность лексемы в частотном словаре
Таким образом, на основе значений частотности и важности составляются альтернативные списки слов, важных для изучения языка.
Генерация частеречных списков Одной из задач при автоматическом создании тестов является выбор потенциальных слов для пропуска. Один из способов выбора потенциальных кандидатов на пропуск в тестах открытого типа — брать представителей определенных частей речи. Для начала ответим на вопрос, какие части речи представляют интерес для генерации тестов.
Возьмем за основу деление на части речи в проекте Universal Dependencies (Universal Dependencies), поскольку мы хотим сделать легко масштабируемый на другие языки инструмент, а основной идей проекта Universal Dependencies является как раз мультиязычность и сопоставимость между различными языками. Выделяют следующие части речи:
- 1) NOUN — существительное
- 2) ADJ — прилагательное
- 3) NUM — числительное
- 4) VERB — глагол
- 5) ADV — наречие
- 6) PRON — местоимение
- 7) ADP — адлог (предлоги и послелоги)
- 8) CCONJ — сочинительный союз
- 9) SCONJ — подчинительный союз
- 10) PART — частица
- 11) INTJ — междометие
- 12) PROPN — имя собственное
- 13) AUX — вспомогательный глагол
- 14) DET — артикль
В русском языке части речи делятся на изменяемые и неизменяемые. К изменяемым частям речи относятся глаголы, существительные, прилагательные, местоимения и числительные. Эти части речи будут взяты за основу при генерации упражнений на форму слова.
В заданиях открытого типа на слова определенной части речи нам кажется целесообразным делать тесты на слова, обладающие высокой частотностью, какими являются, например, предлоги, союзы и местоимения. Предлоги, союзы и местоимения представляют собой закрытый класс, то есть состоят из ограниченного списка слов, состав которого почти не пополняется, и обладают высокой частотностью, не варьирующейся сильно в зависимости от жанра текста. Таким образом, их знание и умение правильно использовать важно при изучении иностранного языка.
При генерации списков частей речи из корпуса извлекаются все леммы, которые морфологический анализатор относит к нужной нам части речи, при этом интерес для изучения представляют только самые частотные представители, то есть, например, те леммы, относительная частота которых, равная отношению частоты леммы к числу словоупотреблений в корпусе, составляет более 5%. Из получившегося списка для дальнейшей работы берется топ 90% слов. тест языковой текстовый коллокация Мы допускаем, что в зависимости от языка интерес для генерации тестов могут представлять различные части речи.
Ниже представлены первые топ-10 слов из автоматически сгенерированных списков местоимений, предлогов и союзов (отсортированные в порядке убывания частотностей):
Таблица 7. Частеречные списки.
Предлоги. | Союзы. | Местоимения. | |
|
|
| |
Генерация коллокаций Одним из самых эффективных способов изучения языка считается заучивание коллокаций. Коллокация — устойчивое словосочетание, связанное лексически и грамматически. Это группа слов, которые встречаются вместе чаще, чем случайно. Лексическая коллокация — последовательность лексических единиц, состоящая из лексической константы и лексических переменных (Fillmore, Kay, & O’Connor, 1988). Коллокация состоит из ключевого слова и коллоката. Словосочетание считается более или менее устойчивым на основании значений статистических мер. Одними из самых популярных статистических мер выделения коллокаций являются t-score, likelihood ratio, pmi и mi. Эти статистические меры основаны на данных о частоте совместной встречаемости слов из таблиц сопряженности 2×2.
Таблица сопряженности — способ представления совместного распределения двух переменных. Строки таблицы — значения одной переменной, столбцы — значения второй переменной. На пересечении строки и столбца указывается частота совместного появления. Так выглядит таблица сопряженности для биграмм:
N1P, N2P, NP1, NP2 — маргинальные частоты. Ожидаемые частоты Eij вычисляются по таблице сопряженности на основании маргинальных частот.
Таблица Вычисление ожидаемых частот слов по таблице сопряженности.
Y. | — Y. | ||
X. | E11 = N1P* NP1 / NPP. | E12 = N1P* NP2 / NPP. | |
— X. | E21 = NP1* N2P / N2P. | E22 = NP2* N2P / NPP. | |
Далее мы будем пользоваться обозначениями, приведенными в таблицах 8 и 9.
Довольно подробный обзор статистических мер, используемых для выделения коллокаций, дан в статье М. Хохловой (Хохлова, 2008). Рассмотрим более подробно статистические меры, сравним получающиеся списки при применении каждой из мер и выберем самую удачную. Для выделения коллокаций инструмент использует модуль nltk. При подсчете коллокаций слова не лемматизируются, стоп-слова не удаляются, выделяются биграммы и триграммы, ширина окна — 1.
Важно отметить, что нашей задачей является выделение самых важных и частотных коллокаций, поскольку мы считаем, что именно на них имеет смысл делать упражнения.
MI (Mutual Information) — коэффициент взаимной зависимости, объем информации. Сравнивает зависимые контекстно-связанные частоты с независимыми, как если бы слова появлялись в тексте совсем случайно.
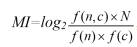
где.
- · n — ключевое слово, с — коллокат;
- · f (n, c) — частота встречаемости ключевого слова n с коллокатом с;
- · f (n) и f (c) — абсолютные частоты n и c в корпусе;
- · N — общее число словоформ в корпусе.
Словосочетание считается статистически значимым, если значение MI > 1. MI позволяет выделять имена собственные, устойчивые словосочетания, а также специальные термины низкой частотности. Особенностью меры MI является то, что она дает высокие значения тем словам, которые обладают более низкой частотностью и ограниченной сочетаемостью. Поэтому часто при использовании данной меры указывается порог встречаемости по частоте, то есть, рассматриваются только те коллокации, которые встретились в корпусе больше определенного числа раз.
PMI (Pointwise Mutual Information), другими словами поточечная совместная информация — часто используемый в NLP метод, учитывающий взаимную информацию. При отсутствии информационных потерь показатель PMI численно равен количеству информации на символ передаваемого сообщения. Как и MI, PMI дает высокий вес редким словосочетаниям.
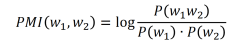
В силу специфики меры PMI было решено удалять из обработки коллокации со словами, которые не входят в топ частотного списка, автоматически посчитанного на материалах корпуса.
При применении метрики PMI на корпусе НКРЯ с порогом встречаемости коллокации > 10 раз из слов, входящих в топ 30% частотного списка, получились следующие топ-20 результатов:
Таблица 10. Коллокации методом pmi.
Коллокация. | PMI. | |
дын дын дын. | 40.14 704. | |
перстами пурпурными эос. | 40.6 903. | |
блям блям блям. | 39.94 495. | |
штакельберг унд вальдек. | 39.93 444. | |
ипотечному жилищному кредитованию. | 39.73 652. | |
мирзо турсун заде. | 39.69 247. | |
цу штакельберг унд. | 39.33 241. | |
лэ мэ нэ. | 38.78 858. | |
го линь шуан. | 38.46 521. | |
противодействию незаконному обороту. | 38.38 262. | |
кин нан тэ. | 38.3 051. | |
абдуррахман ибн хоттаб. | 37.92 679. | |
гассан абдуррахман ибн. | 37.70 440. | |
чан кай ши. | 37.66 983. | |
гарун аль рашид. | 37.46 170. | |
аль акрам абдул. | 37.36 243. | |
мао цзэ дун. | 37.26 603. | |
карловых варах. | 21.36 600. | |
Мы видим, что мера PMI выделяет очень низкочастотные коллокации, дает высокий вес именам собственным и терминологическим словосочетаниям. Поскольку нашей задачей является выделение наиболее типичных для языка словосочетаний, эта метрика нам не подходит.
T-score (критерий стьюдента) учитывает частоту совместной встречаемости ключевого слова и коллоката и отвечает на вопрос, насколько неслучайной является сила связи между коллокатами.
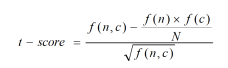
где.
- · n — ключевое слово, с — коллокат;
- · f (n, c) — частота встречаемости ключевого слова n с коллокатом с;
- · f (n) и f (c) — абсолютные частоты n и c в корпусе;
- · N — общее число словоформ в корпусе.
Особенностью данной меры является то, что она выделяет коллокации с очень частотными словами, в том числе со служебными словами. Поэтому часто при подсчете t-score задается список стоп-слов с местоимениями, союзами и предлогами, чтобы отбросить самые частотные слова, однако для решения нашей задачи было решено стоп-слова не удалять.
При применении метрики t-score на корпусе НКРЯ с фильтром встречаемости коллокаций > 10 раз получились следующие топ-10 результатов:
Таблица 11. Коллокации методом t-score.
Коллокация. | T-score. | |
самом деле. | 52.1005. | |
друг друга. | 50.5038. | |
сих пор | 45.3895. | |
конце концов. | 39.6524. | |
лет назад. | 38.6828. | |
не знаю. | 39.6244. | |
тех пор | 37.6901. | |
таким образом. | 37.1978. | |
друг другу. | 35.5127. | |
в конце концов. | 34.8136. | |
Нас вполне устраивают эти результаты, метрика t-score действительно выделяет самые частотные коллокации, знание которых, на наш взгляд, важно при изучении иностранного языка.
Log-likelihood ratio, другими словами логарифмическая функция правдоподобия.
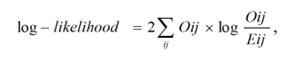
где Oij — наблюдаемая частота, Eij — ожидаемая частота При применении метрики log-likelihood на корпусе НКРЯ с фильтром встречаемости коллокации > 10 раз получились следующие топ-10 коллокаций:
Таблица 12. Коллокации методом log likelihood.
Коллокация. | Log-likelihood. | |
и и и. | 281 108.78770. | |
потому что он. | 280 879.79050. | |
потому что это. | 276 733.48672. | |
не может быть. | 276 276.61751. | |
о том что. | 268 933.79190. | |
потому что я. | 267 109.11807. | |
потому что ты. | 266 349.94229. | |
потому что такое. | 265 493.48475. | |
потому что вы. | 264 278.362194. | |
я потому что. | 263 857.463025. | |
В следующей таблице представлены результаты при применении метрики raw.
В результате анализа получившихся при использовании различных статистических метрик результатов для генерации списка коллокаций было решено использовать метрику t-score.