Анализ одномерных количественных данных

Элемент называется i-й порядковой статистикой, главные порядковые статистики — наименьшее значение и наибольшее значение. Обозначение индекса в круглых скобках (i) является общепринятым символом обозначения ранжированности (упорядоченности в порядке неубывания) наблюдений. Масштаб по осям выбирают произвольно такой, чтобы была обеспечена необходимая наглядность. Так же как и гистограмма, полигон… Читать ещё >
Анализ одномерных количественных данных (реферат, курсовая, диплом, контрольная)
Количественные данные — дискретные и особенно непрерывные — вследствие более совершенных шкал измерения и возможности количественной оценки различий между ними допускают уже гораздо более широкий спектр возможностей в плане их статистического анализа.
Так как практические исследования зачастую связаны с достаточно большими массивами данных, одной из первых у исследователя возникает задача их сгруппировать, изучить их внутреннюю структуру, представить в более компактном и удобном виде, дающем лучшую визуализацию таких данных.
Группировка дискретных количественных данных
Пусть имеются данные п наблюдений 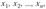 каждое из которых характеризует один количественный признак X. Решается задача обработки этих данных. Если число наблюдений (п) достаточно велико (по крайней мере
каждое из которых характеризует один количественный признак X. Решается задача обработки этих данных. Если число наблюдений (п) достаточно велико (по крайней мере 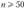 '), то их предварительно ранжируют и подвергают группировке.
'), то их предварительно ранжируют и подвергают группировке.
Вариационный ряд — значения п независимых наблюдений 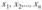 количественного признака X, расположенные в порядке возрастания (неубывания) значений:
количественного признака X, расположенные в порядке возрастания (неубывания) значений:
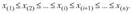
Элемент 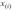 называется i-й порядковой статистикой, главные порядковые статистики — наименьшее значение
называется i-й порядковой статистикой, главные порядковые статистики — наименьшее значение 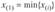 и наибольшее значение
и наибольшее значение 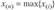 . Обозначение индекса в круглых скобках (i) является общепринятым символом обозначения ранжированности (упорядоченности в порядке неубывания) наблюдений.
. Обозначение индекса в круглых скобках (i) является общепринятым символом обозначения ранжированности (упорядоченности в порядке неубывания) наблюдений.
Разность наибольшего и наименьшего значений признака называется размахом вариационного ряда:
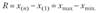
Размах служит самостоятельной характеристикой разброса значений изучаемого признака (см. подпараграф 1.3.3).
С целью улучшения представления эмпирических данных при большом числе наблюдений их группируют, получая сгруппированный вариационный ряд.
Для группировки дискретных количественных данных подсчитывают частоту встречаемости mi, каждого признака  . При достаточно большом числе значений сгруппированный вариационный ряд может быть подвергнут дальнейшей группировке и преобразован в интервальный.
. При достаточно большом числе значений сгруппированный вариационный ряд может быть подвергнут дальнейшей группировке и преобразован в интервальный.
Сгруппированный дискретный вариационный ряд представляет собой к значений признака  , указанных вместе с соответствующими частотами га. или частостями
, указанных вместе с соответствующими частотами га. или частостями 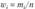 (эти частоты называют эмпирическими):
(эти частоты называют эмпирическими):
Значения признака дг,. | *. | хт | … | хт | … | x. |
Частоты mi. | ТП | т2. | … | mi | … |
Сгруппированный дискретный вариационный ряд графически представляют в виде гистограммы (которую мы рассмотрели для категориальных данных) или полигона.
Полигон — графическое изображение сгруппированного дискретного вариационного ряда в виде ломаной, соединяющей точки, по оси абсцисс соответствующие всем возможным значениям признака, а по оси ординат — значениям частот  или относительных частот
или относительных частот 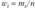
Масштаб по осям выбирают произвольно такой, чтобы была обеспечена необходимая наглядность. Так же как и гистограмма, полигон позволяет оценить распределение частот значений дискретной переменной, выявить наиболее часто (мода) и редко встречающиеся значения признака.
Сгруппированный кумулятивный дискретный вариационный ряд представляет собой значения признака  , указанные вместе с соответствующими накопленными частотами
, указанные вместе с соответствующими накопленными частотами  или частостями
или частостями  :
:
Значения признака xi. |  |  |  | |
Накопленная частота тт. |  |  |  |
Сгруппированный кумулятивный дискретный вариационный ряд графически представляют в виде кумуляты.
Кумулятивная кривая (кумулята) (cumulative line graph), или огива (ogive) [56] - графическое изображение сгруппированного кумулятивного дискретного вариационного ряда в виде столбцов, при построении которого по оси абсцисс откладывают все возможные значения признака, а по оси ординат — накопленные частоты или накопленные относительные частоты, относящиеся к данному значению. Кумулята показывает количество (или долю) объектов совокупности, значения признака которых не превышают заданного.
Пример 1.18
По данным представленной таблицы результатов анализа числа промахов 30 случайно отобранных спортсменов, участвовавших в соревнованиях и сделавших, но 10 выстрелов, но движущейся мишени (табл. 1.7), требуется построить вариационный дискретный ряд и получить различные графические изображения ряда данных — гистограмму, полигон и кумуляту частот и относительных частот ряда распределения.
Таблица 1.7
Исходная таблица числа промахов 30 случайно отобранных спортсменов
Решение
Чтобы построить вариационный ряд, значения необходимо ранжировать в порядке неубывания. В MS Excel это легко сделать с помощью функции СОРТИРОВКА, А — Я. Полученный вариационный ряд числа промахов представлен в таблице 1.8.
Таблица 1.8
Вариационный ряд числа промахов 30 случайно отобранных спортсменов
X, | |||||||||||||||
По полученному вариационному ряду уже легко посчитать, сколько раз встречается каждое значение и построить сгруппированный ряд.
Если число значений очень велико, то нет необходимости строить вариационный ряд, можно сразу из исходных данных получить сгруппированный вариационный ряд с помощью функции MS Excel ЧАСТОТА, которая позволяет подсчитать частоты значений массива данных, попадающих в заданные интервалы или принимающих заданные значения (как у нас).
Для этого после определения возможных значений признака нужно выделить область, состоящую из смежных ячеек, количество которых на единицу больше количества значений (выделена серым цветом), вызвать встроенную статистическую функцию ЧАСТОТА, выделить массив данных и массив значений признака в соответствующих окнах функции, нажать комбинацию клавиш для работы с матрицами CTRL + SHIFT + ENTER, после чего в выделенной (серой) области появятся частоты встречаемости значений в массиве данных:

Полученные частоты на данном небольшом массиве данных легко проверить, но табл. 1.8.
Аналогично можно построить сгруппированный вариационный ряд с помощью модуля MS Excel АНАЛИЗ ДАННЫХ — Гистограмма.
Итак, полученный сгруппированный дискретный вариационный ряд и кумулятивный вариационный ряд частот и относительных частот числа промахов спортсмена представлены в табл. 1.9.
Таблица 1.9
Сгруппированный вариационный ряд числа промахов 30 случайно отобранных спортсменов
Значения признака х, — число промахов. | |||||||||
Частота | |||||||||
Относительная частота |  | 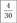 |  |  | 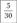 | 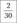 | 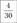 | 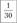 | 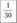 |
Накопленная частота встречаемости — количество спортсменов с числом промахов не менее | |||||||||
Относительная накопленная частота |  | 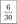 | 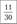 | 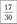 |  | 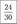 |  |  |


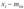

На основании данных табл. 1.9 мы можем построить все требуемые графики частот и относительных частот числа промахов — гистограмму, полигон и кумуляту.
По гистограмме (рис. 1.11) и полигону (рис. 1.12) распределения легко определить моду — число промахов с максимальной частотой: здесь это три промаха (встречается у шести спортсменов), и наиболее редкие значения признака — семь и восемь промахов встречаются всего лишь по одному разу.

Рис. 1.11. Гистограмма частот числа промахов к примеру 1.18.
Полигон строится по тем же точкам, что и гистограмма, просто имеем другой вид графика — не столбиковая диаграмма, а точечно-линейный график.
Для построения кумуляты (рис. 1.13) используем накопленные частоты из табл. 1.9.
График кумуляты позволяет найти число объектов, имеющих значения признака, не превышающие заданного. Например, из табл. 1.9 и рис. 1.13 очевидно, что 24 спортсмена имеют число промахов, не превышающее пяти (от нуля до пяти промахов).

Рис. 1.12. Полигон частот числа промахов к примеру 1.18.

Рис. 1.13. Кумулята частот числа промахов к примеру 1.18.
Графики гистограммы, полигона и кумуляты относительных частот выглядят абсолютно аналогично, только по оси ординат у них соответственно находятся относительные частоты, и они показывают не число, а долю объектов. Для примера построим только гистограмму относительных частот (рис. 1.14).

Рис. 1.14. Гистограмма относительных частот числа промахов к примеру 1.18.
Графики относительных частот показывают долю объектов с соответствующим значением переменной. Например, из рис. 1.14 и табл. 1.9 очевидно, что мода, равная трем промахам, имеет относительную частоту встречаемости, равную 0,2. Это означает, что 20% (6 из 30) всех объектов совокупности (выбранных спортсменов) имеет ровно три промаха.