Деревья классификации (Classification Tree)

Назначение и общая характеристика. Группа методов под общим названием «Деревья классификации» (Classification Tree), начиная с 14-й версии SPSS, включена в число предлагаемых пользователю методов классификации, хотя эти методы очень существенно отличаются от рассмотренных выше методов в идейном плане. Как уже отмечалось, они решают не задачу так называемого обучения без учителя, когда среди… Читать ещё >
Деревья классификации (Classification Tree) (реферат, курсовая, диплом, контрольная)
Назначение и общая характеристика. Группа методов под общим названием «Деревья классификации» (Classification Tree), начиная с 14-й версии SPSS, включена в число предлагаемых пользователю методов классификации, хотя эти методы очень существенно отличаются от рассмотренных выше методов в идейном плане. Как уже отмечалось, они решают не задачу так называемого обучения без учителя, когда среди точек-объектов в пространстве переменных компьютер отыскивает сгущения и называет их «кластерами», а задачу обучения с учителем. В качестве такового выступает назначенная исследователем зависимая переменная (Y), измеренная в номинальной, ранговой или интервальной шкале.
Методы данной группы позволяют, например, выяснить, при каком сочетании независимых переменных зависимая переменная чаще всего принимает одно значение, а при каком — другое. Например, какие люди (скажем, с каким сочетанием социально-демографических или психографических характеристик) отдают предпочтение одной из конкурирующих между собой марке товара, какие — другой и т. д.
В справочной системе SPSS приведена другая практически важная ситуация, когда методы данной группы крайне полезны. Банк выдает кредиты, а затем сопоставляет данные тех, кто вовремя выплатил или исправно выплачивает кредиты, и тех, кто нарушает сроки возврата кредита. На этой основе в будущем банк оценивает вероятность того, что очередной обратившийся за кредитом вернет его своевременно. Основываясь на этой модели, банк разрабатывает правила выдачи кредитов.
Поясним работу методов данной группы для случая, когда анализируются результаты опроса. Этот результат представляет собой дерево, к корневой вершине которого «приписаны» все опрошенные с общим распределением значений зависимой переменной 7, а в каждой конечной вершине — определенная группа опрошенных, в которой преобладает какая-то одна категория независимой переменной. Например, это может быть группа опрошенных с определенным набором социально-демографических характеристик, большая часть которой отдает предпочтение определенной марке товара.
Остановимся чуть подробнее на том, как организовано это дерево.
Деление вершины дерева производится по значениям той независимой переменной, которая позволяет получить под группы как можно более контрастные в смысле распределения значений зависимой переменной. Таким образом, на верхнем уровне образуется две или более вершин первого уровня. Число таких вершин определяется категориями первого предиктора, причем алгоритм может при необходимости объединять какие-то категории, оптимизируя критерий построения дерева решений.
Далее для каждой из вершин первого уровня отыскивается, определяется своя независимая переменная-предиктор второго уровня. С помощью этих предикторов второго уровня получаются вершины второго уровня и т. д., пока параметры построения дерева разрешают это дерево строить.
Построение классификационного дерева. Остановимся на том, как пользоваться методами группы «Деревья классификации», разъясняя по ходу изложения, какие варианты действий существуют и как осуществить выбор.
Методы данной группы позволяют работать с переменными любых типов, но по-разному. Поэтому исследователь должен прежде всего задать тип всех используемых переменных, а для номинальных и ранговых переменных — еще и метки. Напоминание о такой необходимости возникает при запуске программ данной группы (рис. 13.27).
Впрочем, программа предоставляет пользователю удобное средство, позволяющее выполнить эти требования (кнопка «Задать свойства переменных»).
После того как формат данных определен, необходимо выбрать независимую (целевую) переменную и зависимые переменные (предикторы), а также указать один из четырех методов построения дерева — CHAID, Исчерпывающий (Exhaustive) CHAID, С&RТ или QUEST (рис. 13.28).
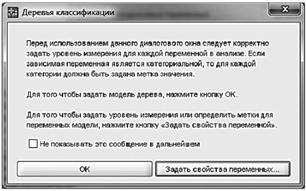
Рис. 13.27. Предупреждение о необходимости уточнения типа переменных и задания меток номинальным и ранговым переменным.
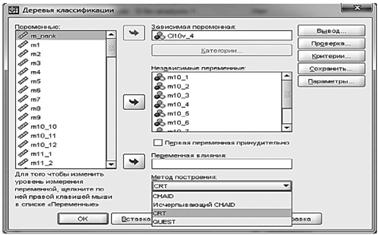
Рис. 13.28. Выбор метода построения дерева.
Метод CHAID (Chi-Square Automatic Interaction Detection — автоматический детектор взаимосвязей на основе критерия ?2) разработан в 1980 г. Это самый известный и наиболее быстро работающий многомерный статистический метод построения деревьев решений, в котором для получения оптимального разбиения используется критерий ?2 связи между категориальными переменными. В соответствии с этим методом каждая вершина дерева при необходимости может быть разделена более чем на две вершины следующего уровня.
Если зависимая переменная является интервальной, в методе используется другой критерий оптимизации — F-критерий Фишера. Если же в интервальной шкале измерены какие-то независимые переменные, они автоматически преобразуются в ранговые, причем числом категорий можно управлять.
Сходным с CHAID, но более совершенным методом является созданный в 1991 г. Исчерпывающий (Exhaustive) CHAID. Его преимущество состоит в том, что при построении дерева анализируются все возможные разбиения на следующих шагах алгоритма. Платой за качество анализа, естественно, является более медленная работа.
Совершенно на других идеях базируется созданный в 1984 г. метод C&RT (Classification And Regression Trees — деревья классификации и регрессии). В отличие от двух предыдущих метод C&RT основан не на статистических критериях различий, а на уменьшении неоднородности в группах объектов, отнесенных к конечным вершинам дерева. При этом «родительские» вершины дерева могут делиться только на две «дочерние» вершины следующего уровня.
Как и в двух предыдущих методах, в методе C&RT можно использовать как количественные, так и категориальные зависимые и независимые переменные. Поскольку здесь производится полный перебор, метод всегда находит наилучший вариант выбранного критерия. Но у этого решения есть особенность: оптимальным выбором чаще оказывается использование таких независимых переменных, у которых много категорий. Кроме того, при большом числе независимых переменных с большим числом категорий в каждой алгоритм может работать довольно долго.
Метод QUEST (Quick, Unbiased, Efficient Statistical Trees — быстрые, несмещенные, результативные статистические деревья) предназначен для преодоления двух отмеченных недостатков предыдущего метода. Этот статистический метод быстрого и эффективного построения бинарных (как и в случае C&RT) деревьев разработан в 1997 г. Однако этот метод применим, только если зависимая переменная измерена в номинальной шкале. Независимые же переменные могут быть любыми, в зависимости от типа той или иной из них применяются различные статистические критерии.
Наш опыт свидетельствует, что требуемого результата обычно удается достичь с помощью методов Exhaustive CHAID или C&RT.
Затем можно задать способ проверки достоверности модели, устойчивости полученного дерева классификации (рис. 13.29). Идея проверки состоит в том, чтобы строить классификационное дерево на одной (обучающей) части выборки, а проверять качество прогнозирования значений исследуемой переменой — на другой (контрольной) части выборки.
Программа предусматривает три варианта такой проверки. Во-первых, можно один раз расщепить выборку на обучающую и контрольную случайным образом. По умолчанию при этом выборка делится пополам, но данную пропорцию можно изменить. Во-вторых, можно тоже один раз расщепить выборку, но не случайным образом, а в зависимости от значения любой переменной из таблицы данных. Строки таблицы данных, в которых эта переменная равна единице, будут включены в обучающую выборку, а все остальные — в контрольную. В-третьих, можно выполнить так называемую кросс-проверку (cross-validation). В последнем случае разделение выборки на обучающую и контрольную выполняется не один, а заданное число раз, не превышающее 25. По умолчанию такое разделение выполняется десять раз. В этом случае выборка случайным образом разделяется на десять подвыборок. Сначала в качестве контрольной подвыборки используется первая подвыборка, затем вторая и т. д. Всякий раз при этом обучающую часть составляют остальные девять случайно сформированных подвыборок. Программа формирует одно, наилучшим образом подходящее для всех десяти расчетов классификационное дерево, качество этого дерева рассчитывается путем усреднения десяти значений соответствующего показателя.
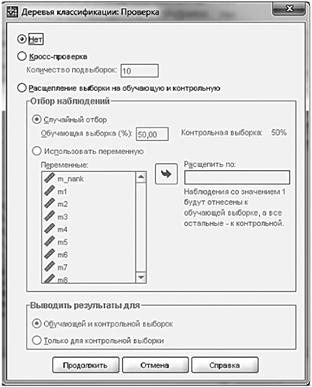
Рис. 13.29. Выбор метода проверки устойчивости дерева классификации.
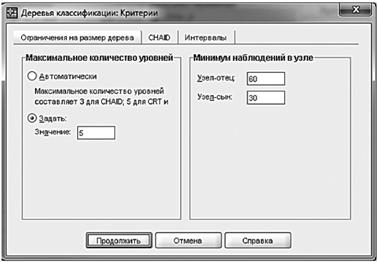
Рис. 13.30. Задание параметров критериев классификации После этого следует выбрать параметры критериев классификации (рис. 13.30). Этих параметров несколько, но основных — два: минимальная численность объектов в узле дерева, который можно разделить («узел-отец», parent node), и в конечной вершине дерева, т. е. узле, который получается после всех делений («узел-сын», child node). По умолчанию первый может содержать не менее 100 объектов, а второй — 50.
Основной результат работы программы — классификационное деревовыводится в графической форме (рис. 13.31). В данном случае в качестве независимой переменной используется переменная с результатами кластерного анализа методом К-средних. Сделано это было для того, чтобы раскрыть «тайну» возникновения четырех кластеров.
Поясним, что мы имеем в виду. Ранее (см. табл. 13.7) мы видели, что каждый из этих кластеров обладает яркими особенностями в плане пользования услугами фитнес-клуба. Например, все представители первого кластера посещают тренажерный зал и не посещают сауну. Однако это свойство, а не определение данного кластера. Дело в том, что и во втором кластере есть респонденты, посещающие тренажерный зал и не посещающие сауну, их три человека. Ко второму, а не первому кластеру они были отнесены потому, что пользуются многими другими услугами фитнес-клуба. Однако, где граница, перейдя которую респондент будет «зачислен» во второй кластер, а не в первый, — из кластерного анализа неясно, а потому результаты кластерного анализа сложно использовать на практике.
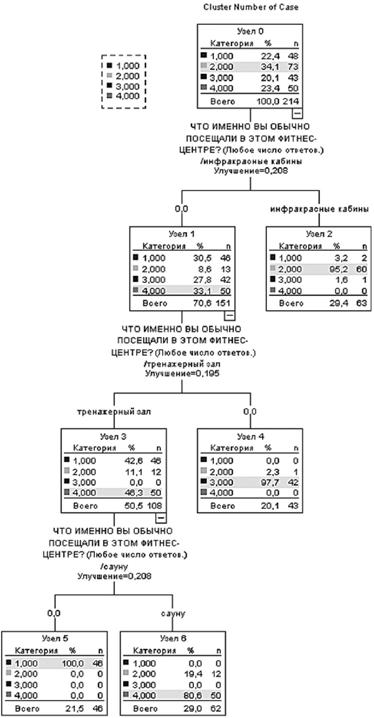
Рис. 13.31. Классификационное дерево В частности, достаточно сложно объяснить руководителю компании, заказавшей маркетинговое исследование, что такое кластеры. Прагматичных людей обычно не очень впечатляет объяснение, что это группы потребителей, которые некоторый сложный алгоритм считает похожими между собой. Можно еще сказать: «Скажите нам, господин заказчик, как потребитель ответил или ответил бы на все вопросы анкеты, и мы немножко посчитаем на компьютере и скажем вам, из какого он кластера!». Но и такой довод обычно мало кого впечатляет.
Другое дело, если бы мы могли сказать: «Господин заказчик! Сейчас мы расскажем вам про потребителей первого типа. Первым типом называются пользователи, которые отвечают на такой-то вопросы анкеты так-то и при этом на такой — так-то. Или — другой вариант — на такой вопрос так-то, на такой — так-то. И все, других вариантов нет, больше никто к данному типу не относится. А теперь мы расскажем вам о свойствах представителей этого типа. Они чаще, чем в среднем, молоды и т. д.». Другими словами, у всякой вещи должны быть не только свойства, но и определение. Авторы предложили использовать, для того чтобы каждый кластер приобрел определение (превратившись благодаря этому из кластера в четко определенный тип), метод классификационного дерева. Для этого в качестве независимой переменной следует взять переменную, содержащую номера кластеров, а в качестве независимых переменных те переменные, в пространстве которых эти кластеры были выделены с помощью иерархического кластерного анализа, а затем кластерного анализа методом К-средних.
Вернемся теперь к рис. 13.31. Этот рисунок, а также его упрощенный схематический вариант (рис. 13.32) позволяет легко понять, какие респонденты относятся к тому или иному кластеру.
Итак, рис. 13.32 позволяет дать простое и ясное определение каждого из типов. Клиенты второго типа — это те и только те, кто посещает инфракрасные кабины; третьего типа — кто не посещает ни инфракрасные кабины, ни тренажерный зал; четвертого типа — кто не посещает инфракрасные кабины, но посещает тренажерный зал и сауну; первого типа, кто не посещает инфракрасные кабины, посещает тренажерный зал и не посещает сауну. Второй тип составляет 29,4%, третий — 20,1%; четвертый — 29,0% и, наконец, первый — 21,5% от числа всех клиентов фитнес-клуба.
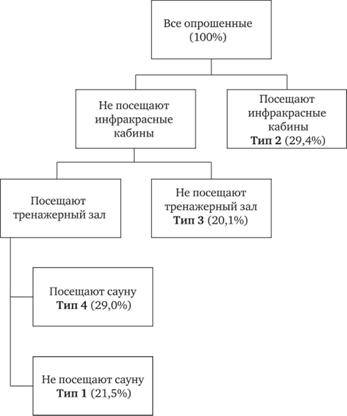
Рис. 13.32. Схематическое представление классификационного дерева Поясним теперь другие данные, которые содержатся на рис. 13.31 в отличие от рис. 13.32. В каждой вершине классификационного дерева содержится таблица частот категорий целевой переменной в количественном и процентном выражении. В строке «Всего» указывается, какую долю составляет данная вершина в процентах от всех опрошенных, а также сколько наблюдений (респондентов) всего к ней относится. Соответственно в строке «Всего» исходной (верхней) вершины процент равен 100, число наблюдений — общему числу наблюдений (опрошенных).
Итак, мы применили метод C&RT для того, чтобы сформировать пусть несколько более упрощенные, чем четыре обнаруженных ранее кластера, но зато четко определенные типы клиентов. Сопоставить разбиение на кластеры с разбиением на типы позволяет таблица результатов классификации, выводимая в отчете при запуске метода дерева классификации (табл. 13.10).
Таблица 13.10. Основные результаты работы метода классификационного дерева
Наблюденное | Предсказанное | ||||
Процент корректных | |||||
95,8. | |||||
82,2. | |||||
97,7. | |||||
100,0. | |||||
Общий процент. | 21,5%. | 29,4%. | 20,1%. | 29,0%. | 92,5. |
Строки таблицы соответствуют кластерам, а столбцы — типам клиентов, построенным методом C&RT. Мы видим, что к первому кластеру относилось 48 респондентов, 46 из которых метод C&RT классифицировал правильно, отнеся к первому типу. Из второго кластера 60 респондентов правильно были отнесены ко второму типу, один к третьему, а 12 (очень много!) — к четвертому. Из 43 представителей третьего кластера лишь один был ошибочно отнесен ко второму типу вместо третьего. И, наконец, все без исключения представители четвертого типа были классифицированы правильно. В итоге было правильно классифицировано 95,8% представителей первого кластера, 82,2% - второго, 97,7% - третьего и все 100% - четвертого. В целом методу CRT удалось правильно классифицировать очень высокую долю: 92,5% от числа всех опрошенных (см. число в итоговой строке правого столбца таблицы)· Таким образом, замена довольно туманных и малопонятных конечному потребителю (заказчику) образований — кластеров — на простые и ясные логические конструкции — типы — очень мало что изменила в распределении клиентов по сегментам. Поэтому в соответствии с разработанной авторами комплексной методикой многомерного анализа данных использование результатов работы метода К-средних в качестве своего рода подсказки и применение затем метода классификационного дерева — важный завершающий этап работы.