Иерархические кластер-процедуры.

Если мы выберем слишком большое число кластеров, то их наполняемость будет невысокой и мы можем упустить возможность изучения взаимосвязей внутри кластеров с помощью аппарата типологической регрессии. При малом числе кластеров характеристики объектов в них будут слишком размыты, что не позволит изучать присущие кластерам закономерности. Поэтому целесообразнее выбрать «золотую середину», т. е… Читать ещё >
Иерархические кластер-процедуры. (реферат, курсовая, диплом, контрольная)
Иерархические алгоритмы используются в задачах классификации небольшого числа объектов (в основном до 100−150 объектов), где основной интерес представляют не число кластеров, а анализ структуры множества этих объектов и наглядная интерпретация проведенного анализа в виде дендрограммы.
Иерархические алгоритмы основаны на построении дендрограмм (от греч. dendron — «дерево»), которые являются результатом иерархического кластерного анализа, описывают близость отдельных точек и кластеров друг к другу, представляют в графическом виде последовательность объединения (разделения) кластеров.
Дендрограмма (dendrogram) — древовидная диаграмма, содержащая п уровней, каждый из которых соответствует одному из шагов процесса последовательного укрупнения кластеров. Дендрограмму также называют деревом объединения кластеров, древовидной схемой, деревом иерархической структуры. Она представляет собой вложенную группировку объектов, которая изменяется на различных уровнях иерархии (рис. 6.2).
Дендрограмма для 73 наблюдений. Взвешенное попарное среднее евклидово расстояние.

Дендрограмма с использованием метода Варда. Объединение кластеров по масштабируемому расстоянию.

Рис. 6.2. Примеры построения дендрограмм в различных пакетах прикладных программ:
а — построенная в ППП STATISTICAL 6 — построенная в ППП SPSS
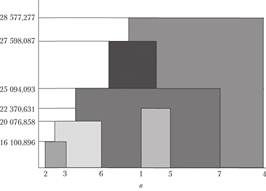
Рис. 6.2 (окончание). Примеры построения дендрограмм в различных пакетах прикладных программ:
в — построенная в пакете MS Excel
По оси ординат п дендрограмме откладываются расстояния объединения объектов в мастеры. Поэтому иа основе анализа дендрограммы можно проследить порядок объединения объектов в кластеры, изучить расстояние, на котором происходит объединение. Близко расположенные друг к другу объекты на дендрограмме представляются сгустками точек, объединенных на небольших по отношению друг к другу расстояниях.
Иерархические (древообразные) процедуры бывают двух типов: агломеративиые и дивизимные. В агломеративных процедурах начальным является разбиение, состоящее из га одноэлементных классов, а конечным — из одного класса (см. рис. 6.2).
Принцип работы дивизимных процедур заключается в последовательном разделении групп элементов — сначала самых далеких, а затем все более близких друг от друга. Большинство иерархических алгоритмов исходит из матрицы расстояний D.
В качестве примера опишем работу агломеративного иерархического алгоритма (см. рис. 6.2). На первом шаге алгоритма каждое наблюдение xh i =1, 2,…, га, рассматривается как отдельный кластер. В дальнейшем на каждом шаге работы алгоритма происходит объединение двух самых близких кластеров, и с учетом принятого расстояния по формуле пересчитывается матрица расстояний, размерность которой снижается на единицу. Работа алгоритма заканчивается, когда все наблюдения объединятся в один класс.
Преимущества иерархических кластер-процедур:
- • по сравнению с другими кластер-процедурами они дают более полный и тонкий анализ структуры исследуемого множества наблюдений;
- • имеется возможность наглядной интерпретации проведенного анализа на основе дендрограммы.
К недостаткам иерархических процедур следует отнести громоздкость их вычислительной реализации (алгоритм требует вычисления на каждом шаге матрицы расстояний). В связи с этим наглядность алгоритмов при числе наблюдений, большем нескольких сотен, теряется.
Отметим, что дендрограмма позволяет исследователю наглядно увидеть последовательность объединения объектов в кластеры и расстояния, на которых происходят объединения объектов, но не дает четкого ответа на вопрос «сколько кластеров необходимо выделить?». Считается, что наибольший скачок в расстояниях при объединении объектов в кластеры сигнализирует о необходимости остановки процедуры объединения и изучения полученной кластерной структуры. Продолжение объединения объектов приведет к образованию кластеров, находящихся на относительно большом расстоянии друг от друга.
В качестве примера на рис. 6.3 представлена дендрограмма объединения объектов в кластеры. Анализ дендрограммы позволяет увидеть, что существует несколько вариантов ответа на вопрос «сколько кластеров необходимо выделить?». Так, например, число выделяемых кластеров может быть равно восьми (пометки А1 — А8), четырем (пометки В1 — В4) и двум (пометки Cl — С2).
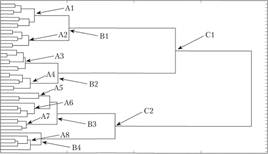
Рис. 6.3. Исследование числа кластеров.
Если мы выберем слишком большое число кластеров, то их наполняемость будет невысокой и мы можем упустить возможность изучения взаимосвязей внутри кластеров с помощью аппарата типологической регрессии. При малом числе кластеров характеристики объектов в них будут слишком размыты, что не позволит изучать присущие кластерам закономерности. Поэтому целесообразнее выбрать «золотую середину», т. е. число кластеров, равное четырем. Отметим, что вывод о количестве кластеров решается в каждом конкретном случае по-своему и зависит от целей исследования и характера исходной информации. В некоторых случаях рекомендуется рассмотреть состав кластеров при равных решениях и выбрать тот вариант, который наиболее хорошо интерпретируется и понятен исследователю. Также при вынесении решения о целесообразности разбиения совокупности объектов на кластеры необходимо рассмотреть варианты разбиения при различных расстояниях между группами объектов и мерах близости групп объектов. Рекомендуется выбирать тот вариант разбиения, который получился наибольшим числом способов (т.е. является наиболее устойчивым), имеет минимальное значение функционала качества разбиения (см. ниже, подпараграф 6.2.4).
На следующем примере покажем, как выбор метрики расстояния между объектами и классами влияет на результаты кластерного анализа.
Пример 6.1
Поданным, представленным в табл. 6.1, требуется провести классификацию шести семей по двум показателям:
- —
 удельные расходы семьи на летний отдых, %;
удельные расходы семьи на летний отдых, %; - —
 удельные расходы семьи за летние месяцы на культурные нужды и спорт, %.
удельные расходы семьи за летние месяцы на культурные нужды и спорт, %.
Таблица 6.1
Исходные данные для примера 6.1.
Семья. | ||||||
хи | ||||||
xi2 |
Классификацию провести по иерархическому агломератнвному атгоритму с использованием:
- 1) евклидова расстояния и метода «ближнего соседа» ;
- 2) евклидова расстояния и метода «дальнего соседа» :
- 3) расстояния Махаланобиса и метода «ближнего соседа» .
Решение
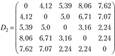
Проведем классификацию, выбрав евклидово расстояние и метод «ближнего соседа». Для расчета расстояния между объектами воспользуемся формулой (6.2) и построим матрицу расстояний D:

На первом шаге число кластеров совпадает с числом o6i>cktob. В матрице расстояний представлено расстояние от каждого объекта до любого другого объекта. Для объединения объектов в кластеры мы должны найти минимальное расстояние между объектами, так как в иерархических процедурах классификации всегда объединяются самые близкие друг к другу объекты, и объединить их в один кластер. Так как минимальными являются несколько расстояний: между вторым и шестым, третьим и пятым, четвертым и пятым объектами (или семьями) (dmin = 2,24), то при объединении объектов мы выберем те, для которых порядковый номер кластера является минимальным. Следуя такой логике, объединим второй и шестой объекты в один кластер. При пересчете расстояний от каждого объекта до объединенных в один кластер второго и шестого объектов (S26) при формировании матрицы D2, следуя алгоритму метода «ближнего соседа», выбираем минимальное расстояние между объектами. После выполнения первого шага объединения будем иметь кластеры Sv $(2.б)* •%" $ 4″ ¦%и матрицу расстояний D>:
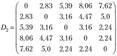
Рассуждая аналогичным образом, на втором шаге объединим в один кластер третий и пятый объекты, расстояние между которыми минимально и составляет </3,5 = 2,24. После объединения получим четыре кластера 5, 5(2 6), 5(3 5), SA.
Работа ап горит м, а повторяется до тех пор, пока все объекты не объединятся в один кластер. На рис. 6.4 в виде дендрограммы представлены результаты работы алгоритма кластерного анализа.

Рис. 6.4. Дендрограмма объединения объектов в кластеры (евклидово расстояние, метод «ближнего соседа»).
На основании анализа дендрограммы можно сделать вывод о том, что наилучшим является разбиение шести семей на два кластера: 5(1 2.6) и $(% i. 5) — Для наглядности результатов классификации представим наблюдения в пространстве переменных т, х2 (рис. 6.5).
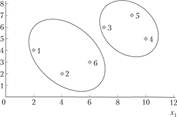
Рис. 6.5. Результаты классификации семей с использованием евклидова расстояния и метода «ближнего соседа» .
2. Проведем классификацию объектов, выбрав евклидово расстояние и метод «дальнего соседа». Для объединения объектов в кластеры воспользуемся рассчитанной ранее на основе евклидовой метрики матрицей расстояний D,.
Для объединения объектов в кластеры мы должны найти минимальное расстояние между объектами, так как в иерархических процедурах классификации всегда объединяются самые близкие друг к другу объекты, и объединить их в один кластер. Так как минимальными являются несколько расстояний: между вторым и шестым, третьим и пятым, четвертым и пятым объектами (или семьями) (dmin = 2,24), то при объединении объектов мы выберем те, для которых порядковый номер кластера является минимальным. Следуя такой логике, объединим второй и шестой объекты в один кластер. При пересчете расстояний от каждого объекта до объединенных в один кластер второго и шестого объектов (52 6) при формировании матрицы D2, следуя алгоритму метода «дальнего соседа», выбираем максимальное расстояние между объектами. После выполнения первого шага объединения будем иметь кластеры 5, 53, S4, S5 и матрицу расстояний Р2:
Так как расстояние между третьим и пятым объектами является минимальным dmin = 2,24, то они объединяются в один кластер. После объединения будем иметь четыре кластера 5,. 5(2, 6), 5(3 5>.4 и матрицу расстояний D3.
Работа алгоритма повторяется до тех пор, пока все объекты не объединятся в один кластер. На рис. 6.6 в виде дендрограммы представлены результаты работы алгоритма кластерного анализа.

Рис. 6.6. Дендрограмма объединения объектов в кластеры (евклидово расстояние, метод «дальнего соседа»).
На основании анализа дендрограммы можно сделать вывод о том, что наилучшим является разбиение шести объектов на два кнастера: 5(j 2 6) и *?(3.4,5) — Для наглядности результатов классификации представим наблюдения в пространстве переменных х{ и х2 (рис. 6.7).
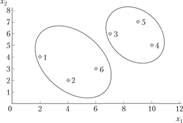
Рис. 6.7. Результаты классификации семей с использованием евклидова расстояния и принципа «дальнего соседа» .
3. Проведем классификацию семей, выбрав расстояние Махаланобиса и принцип «ближнего соседа» .
Для расчета расстояния Махаланобиса воспользуемся формулой (6.1), согласно которой расстояние между двумя объектами, например первым и вторым, может быть найдено следующим образом:  . При работе с выборочными данными воспользуемся аналогами параметров генеральной совокупности. Заменим ковариационную матрицу генеральной совокупности I на соответствующий выборочный аналог — матрицу S, элементы которой можно найти по формуле
. При работе с выборочными данными воспользуемся аналогами параметров генеральной совокупности. Заменим ковариационную матрицу генеральной совокупности I на соответствующий выборочный аналог — матрицу S, элементы которой можно найти по формуле  .
.
Элементы главной диагонали ковариационной матрицы соответствуют дисперсиям элементов, которые могут быть найдены по формуле 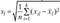
Коэффициент корреляции г= 0,639, отсюда.

Таким образом, матрица S имеет вид  Вычисляем далее:
Вычисляем далее:

Проведя аналогичные расчеты, запишем матрицу расстояний D:

Так как минимальное расстояние — между третьим и пятым объектами ( ), то на первом шаге они объединяться в один кластер. Работа алго;
), то на первом шаге они объединяться в один кластер. Работа алго;
ритма повторяется до тех мор, пока все объекты не объединятся в один кластер. На рис. 6.8 в виде дендрограммы представлены результаты работы алгоритма кластерного анализа.

Рис. 6.8. Дендрограмма объединения объектов в кластеры (расстояние Махаланобиса, метод «ближнего соседа»).
На основании анализа дендрограммы можно сделать вывод о том, что наилучшим является разбиение шести объектов на два кластера: 3 5) и ^2.4.6) — Результаты классификации семей в пространстве переменных х{ и х2 представлены на рис. 6.9.
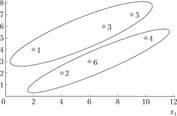
Рис. 6.9. Результаты классификации семей с использованием расстояния Махаланобиса и принципа «ближнего соседа» .
Отметим, что значительное отличие результатов классификации, полученной с использованием расстояния Махаланобиса, от результатов классификаций, полученных с использованием методов «ближнего соседа» и «дальнего соседа», обусловлено тем, что в расстоянии Махаланобиса учитывается наличие корреляционной зависимости между переменными д*| и х2. Полученные два кластера представляют собой регрессионно однородные совокупности, причем в каждом кластере три точки практически лежат на прямой (см. рис. 6.9). В данной задаче этому результату классификации следует отдать предпочтение.
Следует помнить, что евклидово расстояние априори предполагает, что переменные .V, и х2 некоррелироваиы, т. е. линейно независимы, а ковариационная матрица диагональная. Расстояние Махаланобиса позволяет учесть как вариацию признаков, так и их взаимосвязь. В случае наличия корреляции признаков, а в нашем случае парный коэффициент корреляции между переменными составил 0,64 (что свидетельствует о взаимосвязи средней силы), предпочтение следует отдать варианту классификации, полученному с использованием расстояния Махаланобиса.